
In the ever-growing constellation of ISO best-practice standards, ISO 24027:2021 gives AI technical and governance teams tools and techniques to establish whether their AI systems are fair and bias-free. It’s not the typical heavy corporate read, but a rather short and practical best-practice standard. I’ll try to demystify ISO 24027 and break it down in a few simple paragraphs.
What is bias and what is fairness?
Bias is a systematic disparity of treatment, judgment, or outcomes towards certain groups of individuals or attributes. On the other hand, fairness is a treatment or behaviour that respects facts, beliefs, and norms, and is not determined by favouritism.
Why this matters for AI systems
A classic example explaining why these concepts are so crucial for AI systems relates to recruitment. You apply for a job, the company receives your CV and scans it through an AI parsing. Based on its analysis of the document’s text, the tool will decide whether you’re a good enough fit to progress your application and, if so, pass it onto the relevant HR person. It’s an awful lot of time saved on the HR side. But how can we be sure that the initial decision made by that AI system is accurate?
In fact, the training data of that AI system might have carried unwanted, unintentional bias. Perhaps a bias towards genders. If not properly mitigated or removed at the training/development stage, that bias will go unnoticed and undisturbed, skewing results and propagating itself in the model’s outputs. The parsing tool trained on biased data may predict that a candidate is a better fit because they are male and discard the application of a better qualified candidate because they are female. The model is not sexist, but the training data may have been (even unintentionally).
ISO 24027 distinguishes between bias and fairness. Bias is not the direct opposite of fairness, but one of its potential drivers. The document mentions cases in which biased inputs did not necessarily result in unfair predictions (a university hiring policy biased towards holders of relevant qualifications), as well as instances of unbiased systems that still can be considered unfair (a policy that indiscriminately rejects all candidates – unbiased towards all categories, but not for this reason fair).
Besides, achieving fairness is also about making difficult trade-offs, which can put the governance person’s ethical coordinates to the test. Take an AI system tasked with deciding what university graduate to award a scholarship. What stakeholder should the algorithm listen to? The university’s diversity officer, who wants a fair distribution of awards to students from varied geographic regions, or that professor who wants a deserving student, who is very keen on the specific research area, to obtain the scholarship? Probably, there is no right answer, and it is the duty of the AI governance function to recognise the possibility. The best course of action remains orientating the AI systems and the overarching governance strategy toward the guiding star of transparency.
A Lot of Biases!
The possible unwanted biases influencing an AI model are numerous. ISO 24027 divides them in three categories: human cognitive bias, data bias, and bias introduced by engineering decisions.
Human cognitive bias
Whether conscious or unconscious, biases influencing human beings’ decisions are likely to affect data collection, AI systems’ design and model training. The most common include:
- Automation bias takes place when humans favour outputs or recommendations made by automated systems over those made without automation (even when the automated systems make errors).
- Confirmation bias is famously known as seeking information that supports or reinforce existing beliefs. This could happen when we read news from outlets that are aligned to our beliefs, because we expect to read opinions we agree with. The same dynamic could influence the way training data is collected, which will likely seed biases in the AI model.
- Societal bias is the result of one or more cognitive biases being held by many individuals in society. This leads to the bias being encoded, replicated and propagated throughout organisations’ policies. An example of societal bias is the over-reliance on historical data to make predictions about current trends, raising questions over the relevance and the accuracy of that data.
Other human cognitive biases comprise:
- Group attribution bias occurs when humans assume that what is true for an individual is also true for everyone (especially when convenient, non-representative samples are used in the data collection phase of the AI lifecycle).
- Implicit bias relates to making associations or assumptions based on their mental models and memories. For instance, training a classifier to identify wedding photos using the presence of a white dress as a feature. But in many cultures, brides do not traditionally dress white.
- In-group bias is another potential driver of poor representativeness in data, and occurs when we show partiality to one’s own group or own characteristics. If an AI system is tested by acquaintances of the system’s developer, there is a realistic possibility that the testing is biased.
- Out-group homogeneity bias is the tendency to see out-group members as more homogenous than in-group members, especially when comparing characteristics such as personal traits, attitudes or values.
Data bias
Data bias is more technical in nature, in that it originates from technical design decisions. Human cognitive bias, training methodology and variations in infrastructure can also indirectly introduce bias into datasets.
Given the overlap between the AI domain and statistics science (think about inferences, predictions, and the wider data science), it will not come as a surprise that statistical bias is a big one. It comprises:
- Selection bias occurs when data samples are not representative of real-world distribution. Significant instances are: a) sampling bias (data samples being collected not randomly from the intended population); b) coverage bias (mismatch between population represented in the data set and the population that the AI model is making predictions about): c) non-response bias (individuals opting out of a survey being significantly higher or lower to than those who do respond).
- Confounding variables are variables that influence both dependent and independent variables, causing spurious association (e.g., ice cream sales and drowning incidents both increase in summer, but one does not cause the other).
- Non-normality occurs when a dataset or variable does not follow a normal distribution, which can influence certain statistical methods and model assumptions.
Other sources of data bias include:
- Data labels and labelling processes may cause societal bias, especially if labels may be broadly interpreted and reduce a continuous spectrum to a binary variable (old/young, male/female). As such, the labeller’s sensibility or beliefs may inject cognitive bias into the data.
- Non-representative sampling is an example of biased training data selection. If the dataset is not representative of the intended population, the model risks learning biased patterns. In the facial recognition domain, a dataset that is not reflective of all skin tones may cause bias towards certain ethnic groups.
- Data processing (pre- and post-): steps such as inputting missing values, removing features, or correcting errors can inadvertently introduce human cognitive bias.
- Simpson’s paradox is a counterintuitive phenomenon in statistics where a trend that appears in several groups of data reverses (or disappears) when the groups are combined (e.g., a treatment appears effective within two separate groups but ineffective when groups are combined).
Bias introduced by engineering decisions
AI model architectures can also bring biases:
- Feature engineering is the process of creating, modifying, or selecting the input variables (features) used in a machine learning model to improve its performance. AI developers may engineer features based on their mental models and beliefs, which can unintentionally introduce bias. For instance, a newly introduced feature might favour a certain group.
- Algorithm selection is another potential driver for bias, because a certain algorithm can introduce a variation in the model performance.
- Hyperparameter tuning involves selecting parameters to optimise the model performance. In principle, this process can affect the model’s functioning and accuracy, potentially contributing to bias.
- Informativeness of feature, even when high, is not a guarantee of safe or unbiased data: it can increase predictive power, but also amplify existing societal or data-driven biases.
Assessing Your AI Model’s Bias and Fairness
You can determine whether your AI model is affected by bias and exhibits fairness by assessing its prediction outputs. ISO 24027 proposes a set of fairness metrics to test the quality of a model’s outputs.
Confusion Matrix
Let’s start with the confusion matrix – a visual breakdown of an AI model’s predictions, showing true positives, false positives, true negatives, and false negatives. It allows for a nuanced understanding of where the model performs well and where it falls short, which is particularly helpful for binary classification tasks.
n For example, a high false negative rate might indicate an issue with how the model weighs certain criteria (an AI loan model denying loans to applicants who actually meet the requirements). Conversely, a high false positive rate (approving loans for high-risk applicants) could signify overly lenient predictions. We can fine-tune the model to reduce specific errors by adjusting parameters. And this is based exactly on a confusion matrix.
Precision
The first metric drawn from the matrix is precision, which measures the reliability of the model’s positive predictions: the proportion of true positives out of all positive predictions made (true positives + false positives). Precision is calculated as follows:
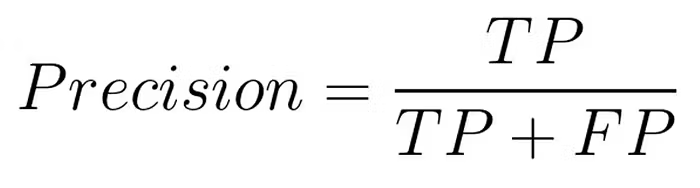
- [ ] PRO: Great when it’s important to minimise false positives (it shows how reliable your positive predictions are)
- [ ] CON: it only evaluates the correctness of positive predictions and ignores false negatives (it won’t show how many real positives you missed)
Accuracy
Accuracy looks at the model’s overall success rate across both positive and negative predictions. It is calculated by dividing the number of correct predictions (both true positives and true negatives) by the total number of predictions made.
n 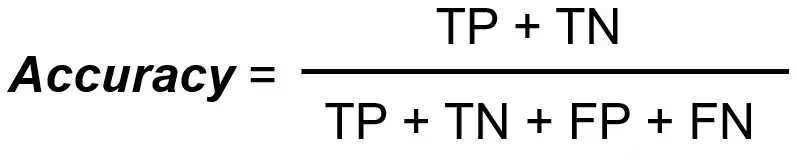
- [ ] PRO: Simple approach to evaluate overall model performance.
- [ ] CON: Easily misleading in case of imbalanced datasets.
Recall
Recall measures how many of the actual positives were correctly identified. It is obtained by dividing the true positives by the sum of true positive and false negatives.
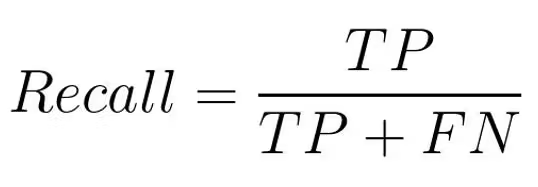
- [ ] PRO: Useful when you need to capture as many true positives as possible (even if that means allowing some false positives).
- [ ] CON: Misleading if used alone (a high recall might come at the cost of many positive predictions, reducing precision).
ROC / AUC Curve
ROC (Receiver Operating Characteristic) plots true positive rate vs. false positive rate at various thresholds, highlighting the trade-off between 𝘴𝘦𝘯𝘴𝘪𝘵𝘪𝘷𝘪𝘵𝘺 (true positives rate) and 𝘴𝘱𝘦𝘤𝘪𝘧𝘪𝘤𝘪𝘵𝘺 (true negatives rate).
AUC (Area Under Curve) quantifies the model’s overall performance across all thresholds, providing a single metric that reflects the model’s ability to distinguish between classes. n
- [ ] PRO: Captures overall discriminative power regardless of threshold.
- [ ] CON: Can at times overstate performance on highly imbalanced data; not the most intuitive for non-technical audiences.
Fairness metrics
Equalised odds
Equalised odds require a model to have both equal true positives and false positives rates across demographic categories. It ensures that those who qualify for a positive outcome are treated equally, and the model’s mistakes are distributed fairly across groups.
It is calculated by comparing true positive rate and false positive rate. If both rates are similar across groups, then the model satisfies equalised odds.
- [ ] PRO: Ensures balanced performance and reduces discriminatory outcomes between groups.
- [ ] CON: May lower overall accuracy or require different decision thresholds for each group, complicating deployment.
Equal opportunity
Equal opportunity is a metric that requires the same true positive rates across all protected groups. To see if your model satisfies equal opportunity, you need to compare the true positive rates across groups.
- [ ] PRO: Focuses directly on reducing false negatives for disadvantaged categories.
- [ ] CON: Ignores false positive differences, hence some categories may still be over- or under-penalized even when opportunity is indeed equal.
Demographic parity
Demographic parity requires that the selection rates for an AI model are the same across different demographic groups. Basically, each group should receive positive outcomes at the same rate, no matter their actual qualification or risk. To establish whether this condition is satisfied, you need to compare the positive prediction rate across different categories.
- [ ] PRO: Ensures equal treatment rates across groups, mitigating issues such as systematic favouritism or underrepresentation.
- [ ] CON: It can hide issues such as higher positive rates for underprivileged groups.
Predictive equality
Predictive equality implies that false positive rates are equal across demographic categories. The main idea is that no category should be more likely to be wrongly flagged as positive than another. When false positive rates across groups are similar, then predictive equality is satisfied.
- [ ] PRO: It mitigates harm caused by false positives, especially in high-stakes sectors like credit, hiring, or criminal justice
- [ ] CON: Ignores differences in True Positive Rate (TPR), so some groups may still miss out on positive outcomes.
Treating bias across the AI lifecycle
If any of the above metrics detect bias in the model’s predictions, it indicates that the bias is present in the model. Ideally, bias should be mitigated as much as possible before deployment. Regardless, ISO 24027 provides a framework to treat bias across the whole lifecycle.
Inception
Requirements analysis
At this stage, you want to scan and evaluate all internal and external requirements of your system.
- Internal requirements include your company’s strategic goals, policies, and values. Attention should also be paid to how to avoid societal impacts and reputational damage.
- External requirements largely include regulatory requirements, ranging from human rights treaties to national legislation on data privacy and data protection. The latter may translate into a series of obligations for your organisation, comprising risk assessments, explainability & auditability measures, as well as provision for “meaningful involvement of a human in the decision-making process”.
Stakeholder engagement
Given that unwanted bias is a known issue in social sciences, ISO 24027 recommends involving an array of trans-disciplinary professionals, spanning social scientists, ethicists, legal and technical experts. To further ensure regulatory compliance and mitigate societal impacts, the document suggests identifying all stakeholders directly or indirectly affected by the AI system.
Data gathering
Another key focus area is the selection of data sources. Organisations should rigorously apply data selection criteria such as
- Completeness: Datasets must be representative of all relevant groups in target populations.
- Accuracy: Inaccuracies in the data will propagate in the model’s outputs.
- Collection procedures: Data collection and origin must be tracked.
- Timeliness: Data must be collected or updated frequently enough to ensure completeness and accuracy.
- Consistency: Data must be formatted and structured consistently to support reliable model training.
Design and development
Data labelling
A key activity of these phases is data representation and labelling, which carries a high risk of bias due to human implicit assumptions. Generally speaking, this occurs when developers label data “good” or “bad” based on their assumptions or beliefs. The use of crowd(sourced) workers can help mitigate bias, as they bring diverse perspectives, when annotating data. What is good for some may not be so good for others.
Sophisticated training
ISO 24027 warns that merely removing features possibly responsible for bias (ethnicity, gender) is insufficient to mitigate bias. In fact, there may still be features acting as proxy revealing the same information that was removed. Techniques to ensure better data representativeness include data re-weighting, sampling, and stratified sampling. A different approach consists in offsetting the bias ex-post from the result. ISO 24027 mentions a series of advanced, highly technical operations, including (but not limited to):
- Iterative orthogonal feature projection – A method that repeatedly adjusts features so that each one provides unique information, reducing overlap and improving the model’s fairness or accuracy.
- Ridge regression – A type of linear regression that slightly “shrinks” coefficient values to prevent overfitting, making predictions more stable.
- Random forest – A collection of decision trees that work together; each tree votes on the outcome, which makes predictions more reliable and reduces mistakes.
Tuning
Your model can be appropriately tuned using bias mitigation algorithms, which are typically classified in three categories:
- Data-based methods (e.g., use of synthetic data, up-sampling of under-represented populations).
- Model-based methods (e.g., introduction of regularization or constraints to force an objective).
- Post-hoc methods (e.g., identifying specific decision threshold to equalise false positive rates).
Verification and Validation
Several techniques can be deployed to measure how well your model is doing and, including:
- Conducting sample checks of labels can reveal the extent to which human labellers unintentionally introduced (see Data Labelling above).
- Internal validity testing ensures that the model performance (as assessed by Accuracy and Precision metrics, for instance) genuinely reflect its learning from the training data, and not from other factors like overfitting.
- External validity testing means re-assessing the model on new or external data to establish whether the new results remain consistent with internal validity tests. This technique is particularly useful to address the issue of proxies. For instance, you can carry out external validity testing by introducing features originally excluded (demographic data) and comparing the outcomes of the original results.
- Another way to detect unwanted bias is gathering feedback from users who interacted with your model in the real world, or from diverse testers, who act as adversaries and uncover previously unnoticed biases.
Deployment
Continuous monitoring is critical for AI models, because they are subject to performance degradation. For this reason, your organisation must commit to transparency regarding the model’s performance and limitations. Your model documentation should comprise qualitative information (ethical considerations and use cases) and quantitative information (model evaluation as split across different subgroups and combinations of multiple subgroups).
High effort, high reward
The AI Governance & Compliance strategy needs a multi-disciplinary approach and cross-functional efforts to be truly effective. At minimum, you want compliance and risk management experts, legal and data privacy advisors, and technical/engineering teams. ISO 24027 generally falls under the remit of the latter group.
Nonetheless, this standard – or at least its broader meaning and implications – should be shared knowledge among your AI governance team, because the mission of making AI safe and trustworthy is a collective challenge. And once the dust of excitement around AI settles, only the companies that are AI-robust will thrive.



 | HackerNoon")



{kind=link}