
AI systems often fail for reasons that seem unpredictable. A model works during development but behaves differently in production. An upstream field changes format without notice. A feature arrives late. A threshold shifts because old assumptions stayed in place for too long. When problems like these appear, teams search through logs and dashboards without a clear guide. One cause can account for many issues. The model was deployed without proper documentation.
Strong documentation gives teams a shared reference that explains how the model should act. It supports audits. It reduces the time needed to diagnose issues. It improves handoffs between teams. It raises long-term confidence in the system. The following sections describe a practical method for documenting model behavior in a way that supports reliability and trust.
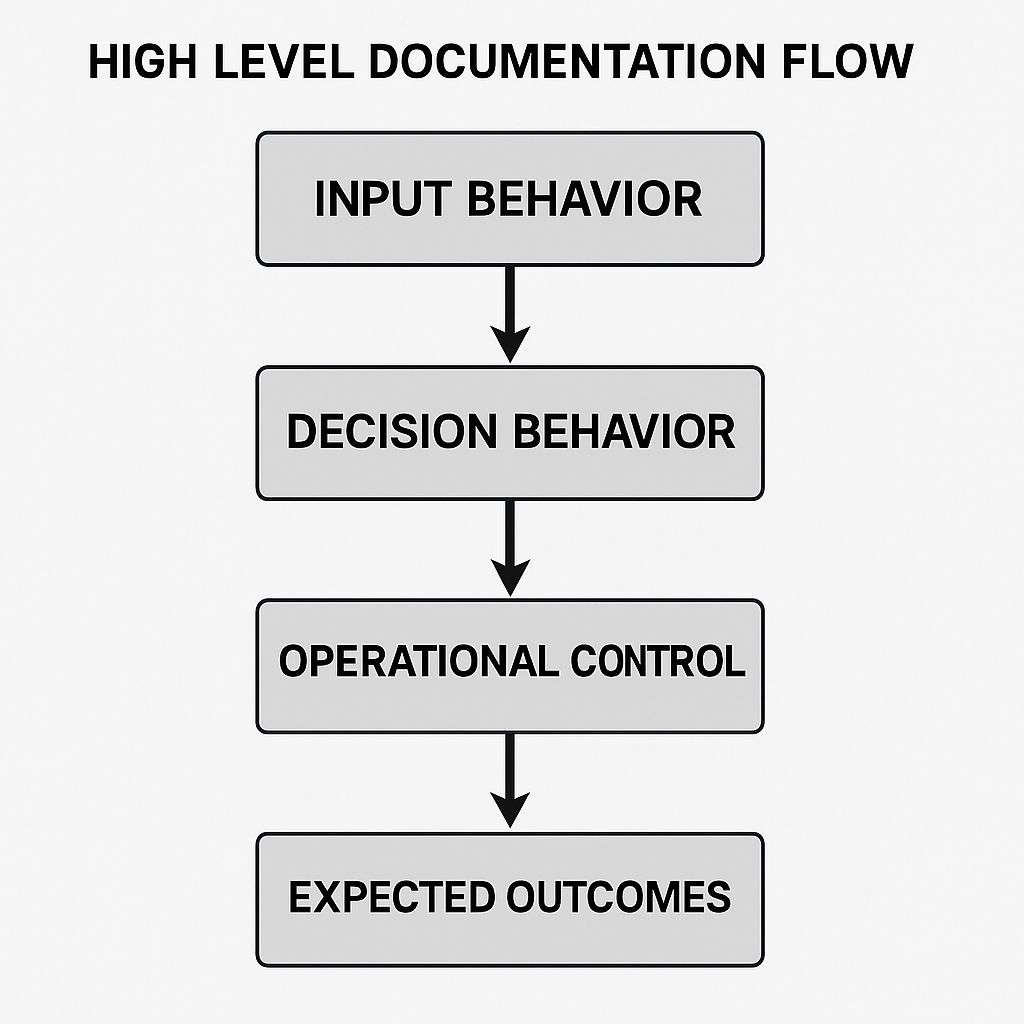
Model Intention
Every model needs a clear statement of intention. This section defines the decision the model supports. It identifies the outcome the model produces and the action that follows the prediction.
A model intention statement uses direct language. It avoids broad claims and vague descriptions. If the model classifies events, the statement explains what the classification means. If the model generates a score, the statement explains how it is used downstream. This clarity prevents incorrect assumptions about the model’s role.
The section lists the inputs the model expects. Each input is described with its field name, format, and purpose. The outputs are described in the same way. Response time expectations are recorded here. Some models run in low-latency environments. Others run in scheduled jobs. Recording these constraints helps teams understand where the model fits in the workflow.
Environmental details also belong here. A model may run on cloud infrastructure, on a local server, or on a constrained device. Each environment shapes how the model behaves under load. Recording these details prevents deployment in situations the model cannot support.
Input Behavior
Input behavior is the source of many production failures. A changed field can cause silent drift. A delayed pipeline can shift predictions. A value outside the normal range can trigger unexpected actions. Documenting input behavior reduces the impact of these events.
This section begins with a list of all input fields. Each field description includes acceptable ranges, valid formats, and any transformation applied before prediction. Recording the origin of each field is essential. Many fields depend on upstream systems that evolve. Knowing where each field comes from helps teams identify causes of unexpected changes.
A short example makes the concept clear. A model may receive a field named device_load. The valid range may be zero to one hundred. Values above this limit should trigger a fallback path. Recording this detail helps teams catch corrupted or noisy input before it reaches production traffic.
This section documents common data risks. These risks include delayed updates, missing values, placeholder entries, and inconsistent sample rates. Recording these risks presents teams a realistic view of the data. It also helps reviewers understand where drift or instability may begin.
An example dataset strengthens this part of the document. The dataset should reflect real patterns. It should include typical ranges, common outliers, and realistic distributions. The content should be non-sensitive and simplified. The goal is to support quick tests, validation checks, and local experimentation. This dataset becomes a reusable resource that helps prevent repeated data errors.
Decision Behavior
Teams rely on predictable decision behavior to maintain stable systems. When decision behavior is unclear, the model appears unpredictable. Such behavior slows audits. It adds uncertainty during incidents. It increases the time needed to review features and resolve issues.
This section describes how the model reaches an output. This section documents thresholds, numeric cutoffs, category rules, and decision points. If the model uses rules before or after prediction, they are included. The goal is to show the full path from input to final action.
Examples bring clarity to this part of the document. Realistic examples demonstrate how specific inputs produce specific outputs. These examples show normal cases, boundary cases, and atypical inputs. They help teams understand the decision process without searching through codes.
The section also explains how the model handles invalid or unexpected input. Many incidents begin with a single bad record. When fallback rules are documented, teams can respond quickly. This reduces guesswork and protects the system during irregular events.
If the system provides confidence scores, ranking levels, or reason codes, these elements are defined here. Clear definitions help readers interpret results correctly. They also support consistent decisions across teams.
Operational Control
Operational control protects the system after deployment. Many teams focus on training and testing but overlook the conditions that affect long-term performance. Strong operational documentation prevents drift, reduces downtime, and improves system resilience.
This section starts with performance limits. These limits include throughput, latency under load, retry rules, and timeout behavior. Recording these details helps teams plan scaling strategies and load tests.
Monitoring checks follow. These checks track data quality, distribution changes, input drift, output stability, and model health. Each check is described with the source of the metric, the alert rule, and the actions teams should take when an alert triggers. Clear monitoring reduces confusion during incidents and keeps responses consistent.
Rollback steps belong in this section. Rollbacks often restore stability faster than incremental fixes. Documenting the process prevents mistakes during high-pressure moments. The description includes the version used for fallback, the systems affected by the rollback, the steps needed to complete it, and the conditions required before starting.
Ownership is the final part of operational control. This section lists the teams responsible for updates, monitoring, reviews, and incident response. Clear ownership prevents gaps in responsibility. A review schedule keeps the documentation current.
Real Example
A fraud detection model evaluated a large volume of transactions. The model used several features provided by upstream sources. One field tracked user movement across regions. The documentation noted the source of this field, its expected range, and the known delays during heavy traffic.
A rise in false declines appeared in one region. The behavior looked random until the team reviewed the documentation. The input behavior section pointed to the movement field as a high-risk input during peak load. The team reviewed upstream logs and found a delay large enough to move the value outside its normal range. The model assigned higher risk scores because of the shift. The rollback process restored normal behavior quickly. The documentation reduced investigation time and protected the rest of the workflow.
Integration Into Team Workflows
This method can be added to any software development process. Teams can begin by creating a template with the sections described above. Filling the template requires accurate information. Once created, the document becomes part of the model release process.
After deployment, the document supports audits, updates, incident reviews, and training for new engineers. It reduces maintenance cost because changes are easier to evaluate. When teams work with a shared reference, they spend less time debating assumptions and more time improving quality.
Conclusion
AI systems become more predictable when teams understand how the model behaves in real conditions. Clear documentation makes that possible. It supports audits. It reduces incident impact. It improves communication across teams. A simple template is enough to begin. Use this structure on one active model in your environment and refine the process with each new release.






{kind=link}