
We’ll demonstrate an end-to-end data extraction pipeline engineered for maximum automation, reproducibility, and technical rigor. Our goal is to transform unstructured PDF documentation—like the official Python manuals—into precise, structured, and queryable tables, using the open-source CocoIndex framework and state-of-the-art LLMs (like Meta’s Llama 3) managed locally by Ollama.
If this tutorial is helpful, star the repo! https://github.com/cocoindex-io/cocoindex
Flow Overview
-
Document Parsing: For each PDF file in your collection, the pipeline automatically converts binary content to markdown using a custom, modular parser. This enables flexible ingestion of diverse manual formats—using CPU or GPU accelerators for scalable performance.
-
Structured Data Extraction: Utilizing built-in ExtractByLlm functions from CocoIndex, each markdown is processed by an LLM (served locally via Ollama, Gemini, or LiteLLM), yielding a fully-typed Python dataclass (ModuleInfo) with classes, methods, arguments, and doc summaries.
-
Post-Processing & Summarization: The flow applies a custom summarization operator, counting and annotating structural aspects of the extracted module, enabling instant insights and downstream analytics.
-
Data Collection & Export: All structured outputs are collected by the indexed PostgreSQL backend, supporting fast analytical queries and robust reporting for every processed manual.
This highly extensible pipeline pattern supports new formats, more complex schemas, or alternative LLM providers with minimal friction, leveraging CocoIndex’s comprehensive type and function system.
Prerequisites
- If you don’t have Postgres installed, please refer to the installation guide.
- Download and install Ollama. Pull your favorite LLM models by:
ollama pull llama3.2
Add Source
Let’s add Python docs as a source.
@cocoindex.flow_def(name="ManualExtraction")
def manual_extraction_flow(
flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope
):
"""
Define an example flow that extracts manual information from a Markdown.
"""
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="manuals", binary=True)
)
modules_index = data_scope.add_collector()
flow_builder.add_source will create a table with the following subfields:
filename(key, type:str): the filename of the file, e.g.dir1/file1.mdcontent(type:strifbinaryisFalse, otherwisebytes): the content of the file
Why This Matters for Automation and Scale
By abstracting file input at this level, you future-proof the flow for ingestion of extremely diverse documentation formats. CocoIndex ensures that each file is indexed, versioned, and queryable, while separating content from structure. This design lays the foundation for highly modular, repeatable end-to-end data pipelines in any technical archiving or document understanding project.
Advanced users can extend this source to pull from S3 buckets, GitHub releases, or enterprise drives—just by swapping the source operator and keeping the rest of the flow logic unchanged.
LocalFile
Parse Markdown
To do this, we can plug in a custom function to convert PDF to markdown. There are so many different parsers commercially and open source available; you can bring your own parser here.
class PdfToMarkdown(cocoindex.op.FunctionSpec):
"""Convert a PDF to markdown."""
@cocoindex.op.executor_class(gpu=True, cache=True, behavior_version=1)
class PdfToMarkdownExecutor:
"""Executor for PdfToMarkdown."""
spec: PdfToMarkdown
_converter: PdfConverter
def prepare(self):
config_parser = ConfigParser({})
self._converter = PdfConverter(
create_model_dict(), config=config_parser.generate_config_dict()
)
def __call__(self, content: bytes) -> str:
with tempfile.NamedTemporaryFile(delete=True, suffix=".pdf") as temp_file:
temp_file.write(content)
temp_file.flush()
text, _, _ = text_from_rendered(self._converter(temp_file.name))
return text
You may wonder why we want to define a spec + executor (instead of using a standalone function) here. The main reason is that there’s some heavy preparation work (initialize the parser) that needs to be done before being ready to process real data.
Custom Function
Plug in the function to the flow.
with data_scope["documents"].row() as doc:
doc["markdown"] = doc["content"].transform(PdfToMarkdown())
It transforms each document to Markdown.
- Leveraging a custom parser within the CocoIndex flow, each binary PDF file is ingested as-is, preserving original fidelity. The use of
binary=Trueensures compatibility with both text and image or scanned PDFs. - The parser is modularized via a
FunctionSpec/executor class design pattern, where resource-intensive model loading (Tesseract, PyMuPDF, or commercial OCR) is performed in initialization, and PDF -> markdown logic is encapsulated in an efficient, deterministic transformation for reproducibility. - GPU acceleration and caching are seamlessly supported for high-throughput settings.
- The choice of the executor class and not a simple function allows:
- Heavyweight resource preloading (OCR models, custom dictionaries, GPU contexts)
- Distributed/cache-aware deployments where workers share model memory
- Hot-swapping parsers (for testing Tesseract vs. PyMuPDF) without changing flow logic
- Transformation results are always markdown, which is LLM-friendly and carries hierarchical semantic cues for reliable extraction.
Extract Structured Data From Markdown Files
Define Schema
Let’s define the schema ModuleInfo using Python dataclasses, and we can pass it to the LLM to extract the structured data. It’s easy to do this with CocoIndex.
@dataclasses.dataclass
class ArgInfo:
"""Information about an argument of a method."""
name: str
description: str
@dataclasses.dataclass
class MethodInfo:
"""Information about a method."""
name: str
args: cocoindex.typing.List[ArgInfo]
description: str
@dataclasses.dataclass
class ClassInfo:
"""Information about a class."""
name: str
description: str
methods: cocoindex.typing.List[MethodInfo]
@dataclasses.dataclass
class ModuleInfo:
"""Information about a Python module."""
title: str
description: str
## Overview: Extracting Structured Data from Python Manuals with Ollama and CocoIndex
In this section, we’ll demonstrate an end-to-end data extraction pipeline engineered for maximum automation, reproducibility, and technical rigor. Our goal is to transform unstructured PDF documentation—like the official Python manuals—into precise, structured, and queryable tables, using the open-source CocoIndex framework and state-of-the-art LLMs (like Meta’s Llama 3) managed locally by Ollama.
### Flow Architecture
1. **Document Parsing**: For each PDF file in your collection, the pipeline automatically converts binary content to markdown using a custom, modular parser. This enables flexible ingestion of diverse manual formats—using CPU or GPU accelerators for scalable performance.
2. **Structured Data Extraction**: Utilizing built-in ExtractByLlm functions from CocoIndex, each markdown is processed by an LLM (served locally via Ollama, Gemini, or LiteLLM), yielding a fully-typed Python dataclass (ModuleInfo) with classes, methods, arguments, and doc summaries.
3. **Post-Processing & Summarization**: The flow applies a custom summarization operator, counting and annotating structural aspects of the extracted module, enabling instant insights and down-stream analytics.
4. **Data Collection & Export**: All structured outputs are collected by the indexed PostgreSQL backend, supporting fast analytical queries and robust reporting for every processed manual.
This highly extensible pipeline pattern supports new formats, more complex schemas, or alternative LLM providers with minimal friction, leveraging CocoIndex’s comprehensive type and function system.
classes: cocoindex.typing.List[ClassInfo]
methods: cocoindex.typing.List[MethodInfo]
- Once converted to markdown, each document is piped into the CocoIndex
ExtractByLlmoperator, which takes the markdown as a rich, contextually annotated prompt.
- The LLM (e.g., Llama 3 served by Ollama on your own hardware) is instructed to extract information based on a Python dataclass schema, ensuring type safety and standardization across runs.
- This design decouples the LLM provider from the downstream flow, so you can swap out Llama for Gemini or OpenAI, and standardize output regardless of LLM vendor differences.
Extract Structured Data
CocoIndex provides built-in functions (e.g., ExtractByLlm) that process data using LLM. This example uses Ollama.
with data_scope["documents"].row() as doc:
doc["module_info"] = doc["content"].transform(
cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(
api_type=cocoindex.LlmApiType.OLLAMA,
# See the full list of models: https://ollama.com/library
model="llama3.2"
),
output_type=ModuleInfo,
instruction="Please extract Python module information from the manual."))
ExtractByLlm
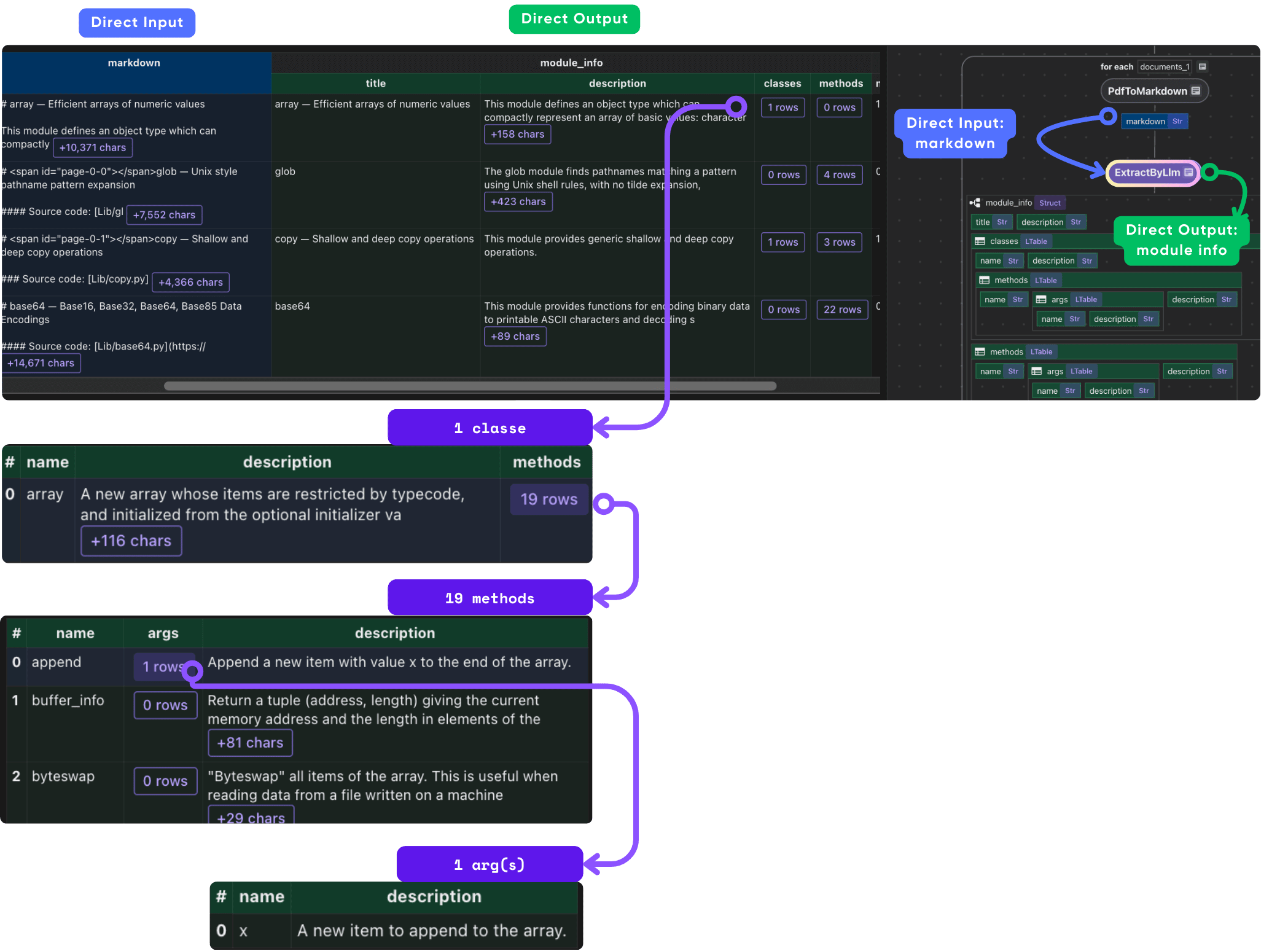
- Use Python dataclasses (
ModuleInfo,ClassInfo, etc.) so that output is always typed and minimally ambiguous. LLM instructions (as a prompt) reinforce extraction fidelity. - This approach allows easy validation (with unit/integration tests), strong contract-driven extraction, and automated upstream/downstream compatibility checks.
Add Summarization to Module Info
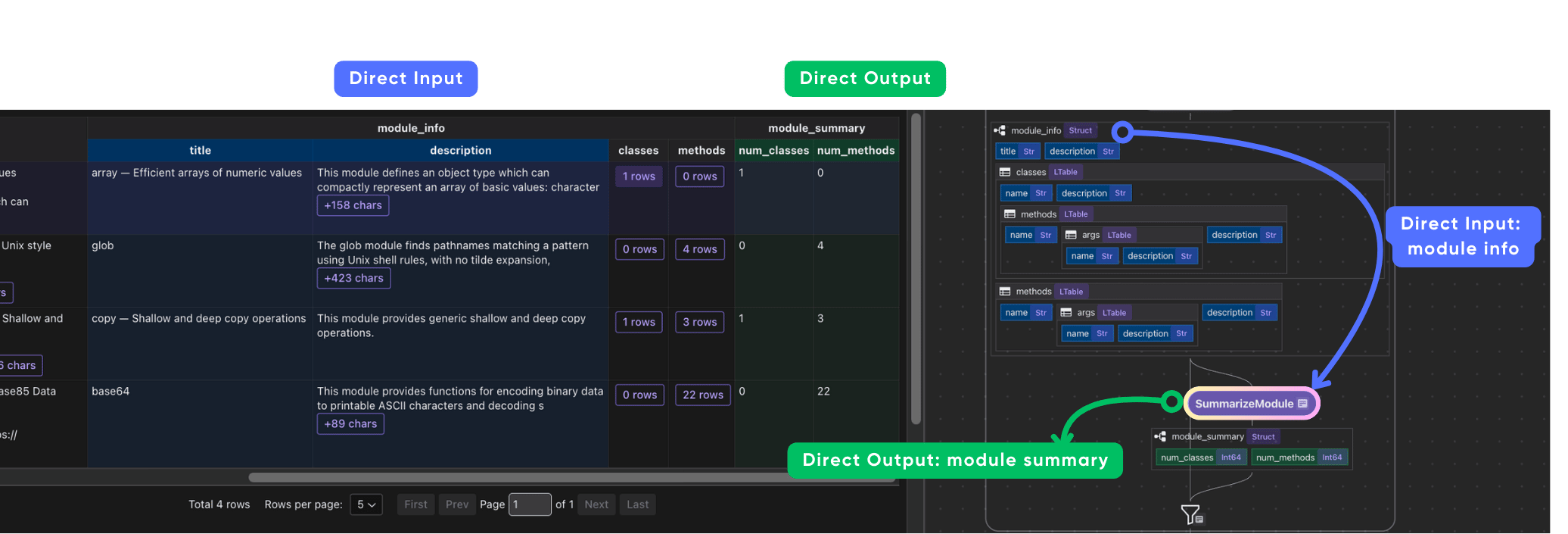
Using CocoIndex as a framework, you can easily add any transformation to the data and collect it as part of the data index. Let’s add a simple summary to each module – like the number of classes and methods, using a simple Python function.
Define Schema
@dataclasses.dataclass
class ModuleSummary:
"""Summary info about a Python module."""
num_classes: int
num_methods: int
A simple custom function to summarize the data.
@cocoindex.op.function()
def summarize_module(module_info: ModuleInfo) -> ModuleSummary:
"""Summarize a Python module."""
return ModuleSummary(
num_classes=len(module_info.classes),
num_methods=len(module_info.methods),
)
- By injecting custom functions (plain Python or accelerated), you can perform inline analytics—such as counting modules, classes, methods—right after LLM extraction, embedding summaries or metadata into the data index itself for instant observability and pipeline health checks.
- This approach allows you to combine weak supervision, LLM output, and classic post-processing in a unified, traceable DAG.
In this way,
- Summary transformation functions provide instant metrics—how many classes, methods, etc.—that can be further used for monitoring, reporting, or pipeline debugging.
- All summary logic can be written in pure Python or tuned for custom use: e.g., filtering on class count, flagging missing docstrings, or computing code complexity at extraction time.
Plug the function into the flow.
with data_scope["documents"].row() as doc:
# ... after the extraction
doc["module_summary"] = doc["module_info"].transform(summarize_module)
Custom Function
Collect the Data
After the extraction, we need to cherry-pick anything we like from the output using the collect function from the collector of a data scope defined above.
modules_index.collect(
filename=doc["filename"],
module_info=doc["module_info"],
)
Finally, let’s export the extracted data to a table.
modules_index.export(
"modules",
cocoindex.storages.Postgres(table_name="modules_info"),
primary_key_fields=["filename"],
)
- All results are indexed and versioned in a Postgres backend, supporting direct SQL analytics, audit trails, or integrations with visualization and BI tools.
- CocoIndex’s collectors enable cherry-picking and normalization of outputs, e.g., only capturing core module info or including full/partial markdown content for additional review.
Query and Test Your Index
Run the following command to set up and update the index.
cocoindex update -L main
You’ll see the index updates state in the terminal.
After the index is built, you have a table with the name modules_info. You can query it at any time, e.g., start a Postgres shell:
psql postgres://cocoindex:cocoindex@localhost/cocoindex
And run the SQL query:
SELECT filename, module_info->'title' AS title, module_summary FROM modules_info;
CocoInsight
CocoInsight is a really cool tool to help you understand your data pipeline and data index. It is in Early Access now (Free).
cocoindex server -ci main
CocoInsight dashboard is here https://cocoindex.io/cocoinsight. It connects to your local CocoIndex server with zero data retention.
This sort of advanced doc extraction pipeline—spanning OCR, LLM-driven type-safe extraction, post-processing, indexing, and visualization—is a blueprint for modern, scalable technical knowledge engineering initiatives.
For production, continuous integration and snapshot versioning are recommended, ensuring the entire pipeline is reproducible, observable, and adaptable to new standards or models.







{kind=link}