
Table of Links
-
Abstract and Introduction
-
Background & Related Work
2.1 Text-to-Image Diffusion Model
2.2 Watermarking Techniques
2.3 Preliminary
2.3.1 Problem Statement
2.3.2 Assumptions
2.4 Methodology
2.4.1 Research Problem
2.4.2 Design Overview
2.4.3 Instance-level Solution
2.5 Statistical-level Solution
-
Experimental Evaluation
3.1 Settings
3.2 Main Results
3.3 Ablation Studies
3.4 Conclusion & References
2 Background & Related Work
2.1 Text-to-Image Diffusion Model
In general, a text-to-image model is a type of conditional generative model that aims to create images based on textual descriptions through generative models. They are trained with data in the form of image-text pairs. In this paper, we take the currently state-of-theart text-to-image model, i.e., Stable Diffusion (SD) [17], to prototype our method. However, note that our approach can be applied to protecting other types of models. Stable Diffusion (SD) [17] is a typical latent diffusion model (LDM). SD mainly contains three modules: (1) Text encoder module 𝑊 : it takes a text prompt 𝑃, and encodes it into the corresponding text embedding 𝑐 = 𝑊 (𝑃); (2) Autoencoder module including an image encoder 𝜀 and decoder 𝐷: 𝜀 transforms an image 𝑥 into a latent representation space where 𝑧 = 𝜀(𝑥), while 𝐷 maps such latent representations back to images, such that 𝐷(𝜀(𝑥)) ≈ 𝑥; (3) Conditional diffusion module 𝜖𝜃 parameterized by 𝜃: a U-Net model [18] trained as a noise predictor to gradually denoise data from randomly sampled Gaussian noise conditioned on the input text embedding.
The objective for learning such a conditional diffusion model (based on image-condition training pairs (𝑥, 𝑐)) is as follows:
After the denoising, the latent representation 𝑧 is decoded into an image by 𝐷.
2.2 Watermarking Techniques
Recent studies suggest the use of watermarking techniques as a defense against misuse of generated data. These techniques help identify copy-paste models [11, 28] or models subjected to extraction attacks [8, 13]. Typically, these watermarks are embedded either in the model during the training phase or in the output during the generation stage.
Watermarking during the training phase. One common approach involves using backdoor triggers as watermarks. This helps identify models that directly reuse source model weights [1]. Recent studies have also shown that text-to-image diffusion models can be vulnerable to backdoor attacks [4, 5, 11, 24, 28]. However, these trigger-based watermarks may be easily removed under model extraction attacks due to weight sparsity and the stealthiness of the backdoor. To combat this, Jia et al. [8] suggested intertwining representations extracted from training data with watermarks. Lv et al. [13] advanced this idea for self-supervised learning models, loosening the requirement for victim and extracted models to share the same architecture.
Watermarking during generation phase. It involves modifying the model outputs to embed the unique watermarks of the model owner. For LLM-based code generation models, Li et al. [10] designed special watermarks by replacing tokens in the generated code with synonymous alternatives from the programming language. Consequently, any model resulting from an extraction attack will adopt the same coding style and produce watermarked code traceable to the original data source.
Currently, watermarking techniques have not yet been explored for their potential to tackle the training data attribution task (See Section 4.1). Additionally, applying these techniques can lead to a drop in the quality of data generated by the model [28]. Moreover, these techniques could reduce the quality of the data generated by the model [28], and they often require specialized security knowledge for implementation during model development. Our approach seeks to address these issues without compromising the quality of generated data or requiring developers to have a background in security.
2.3 Preliminary
2.3.1 Problem Statement
Source model. We denote the well-trained text-to-image source model as M𝑆 . The source model is trained with a large amount of highquality “text-image” pairs, denoted as {TXT𝑡 , IMG𝑡 }. During the inference phase, it can generate an img, given a text prompt txt, i.e.,
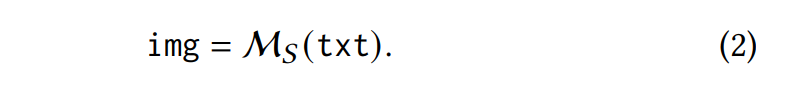
Aggressive infringing model. An aggressive adversary might aim to train its text-to-image model to offer online services for economic gain. The adversary can easily obtain an open-source model architecture, which may be the same as the source model or may be not. The adversary does not have enough high-quality “text-image” pairs to train a satisfactory model. It can prepare the training dataset in the following manner. The adversary prepares a set of text TXT𝐴, and it queries the M𝑆 with the set of text, and collects the corresponding IMG𝐴 generated by M𝑆 . Then, the adversary trains its model M𝐴 with the generated data pairs. As the user terms reported in Figure 2, the adversary abuses the generated data, and the right of the source model is violated.

Note that when 𝜌 equals 1, the inconspicuous adversary becomes the aggressive adversary. Therefore, for simplicity, we use the following notations to represent these two types of adversaries, i.e.,

Innocent model. For the sake of rigorous narration, we define an innocent model, denoted as M𝐼𝑛, which provides similar services as the source model, but its training data has no connection whatsoever with the data generated by the M𝑆 .

2.3.2 Assumptions
Here we make some reasonable assumptions to better illustrate our working scenario.
About the source model and its owner. The model architecture and training algorithm of model M𝑆 can be open-source. The owner of the source model M𝑆 does not have any security knowledge, so it neither watermarks any training data during the model training nor modifies the model output in the inference phase for watermarking purposes. The question of utmost concern for the model owner, as shown in Figure 2 is whether the data generated by M𝑆 has been used to train another model. The source model owner has full knowledge of the model architecture and parameters and can access all training data of the M𝑆.
We hypothesize that the training process of the source model might involve both public-accessible data and private data. Consequently, the generated data may contain examples related to both public and private data. This paper discusses the attribution of generated data relevant to private data.
About the suspicious model. The suspicious model M is in a black-box setting. The suspicious model may share the same model architecture as the source model. The functionality of the suspicious model is also provided, which is necessary for an ordinary user to use the suspicious model. It only offers a query-only interface for users to perform the investigation.
2.4 Methodology
2.4.1 Research Problem
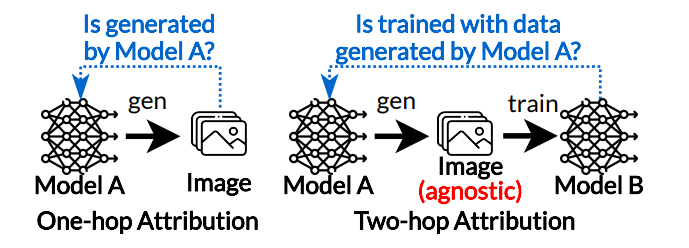
We define the task of “determining whether a piece of data is generated by a particular model” as a one-hop data attribution. This idea is illustrated in Figure 3. The one-hop data attribution is gaining attention in both academia [11, 28] and industry circles [16, 17]. Checking the presence of a certain watermark on the generated data is a common one-hop data attribution procedure.
Our work focuses on two-hop attribution, that is, we aim to determine if Model B has been trained using data generated by Model A. In this setting, the data generated by Model A cannot be enumerated, and the generated data is not embedded with watermarks. This task has caught recent attention, and Han et al. [6] made an initial exploration on whether the training data of a classification model is generated by a specific GAN model in the aggressive infringing setting as defined in Section 3.
Compared to the existing effort, our work addresses a more challenging task under a real-world generation scenario. First, we investigate a more realistic threat model. We consider not only the aggressive infringing model but also an inconspicuous setting. We argue that the inconspicuous setting is more prevalent, especially when many developers can only collect a small amount of data to fine-tune their models instead of training from scratch. Second, we examine more complex subjects. Previous studies explored source models with simple GAN networks, and the suspicious model was a closed-vocabulary classification model. However, in our study, both the source model and the suspicious model are unexplored text-to-image diffusion models capable of managing open-vocabulary generation tasks, which makes them tougher to analyze.
2.4.2 Design Overview
As illustrated in Figure 3, within the two-hop attribution context, the generated data used to train Model B is agnostic. Therefore, to solve the two-hop data attribution, we must establish a connection between Model B and Model A. This is similar to works in the field of model extraction attacks [12, 19, 27].

where 𝑥 ∼ X is any input from the distribution X, and 𝜖 is a small positive number, signifying the extraction error.
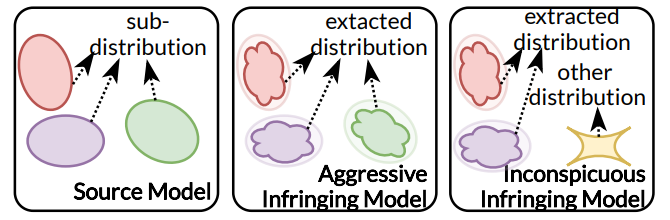
Inspired by the model extraction tasks, we describe the two-hop attribution task in Figure 4. An infringing model might either completely (i.e., aggressive setting) or partially (i.e., inconspicuous setting) duplicate the source model’s distribution. Our primary insight in addressing this concern is to identify the extracted distribution present in the suspicious model. To achieve this, we assess the relationship between the behaviors of the source and suspicious models, both at instance and statistical levels.
At instance level, we aim to identify an infringing model through measuring the attribution confidence on a set of instances. Guided by Equation 5, we use a set of key samples to query both the source and suspicious models, subsequently measuring the similarity of their responses. The challenge lies in the selection of key samples. We will elaborate on this in Section 4.3.
At statistical level, we aim to measure the behavior differences between the innocent model and infringing model. We hypothesize that, given inputs from the source model’s distribution, there will be a significant performance gap between the infringing and innocent models. The challenge here is to develop a technique that accurately measures this difference. We will delve into this in Section 4.4.
The performance of the instance level solution relies on the ability to find samples that can accurately depict the distribution of of the source models’ training data. It has superior interpretability. While the statistical level solution falls short in interpretability, it enables a more comprehensive attribution, and hence a superior accuracy. Therefore, in practice, we recommend users choose according to their specific requirements.
2.4.3 Instance-level Solution
The core of the instance-level solution is to capture the shared sub-distributions between the source and suspicious models (Refer to Figure 4). In this context, we use {X1, . . . , X𝑛} to denote sub-distributions of the source model. The suspicious model’s subdistributions, which are shared with the source model, are represented as {X1, . . . , X𝑚}. It’s important to note that when𝑚 equals 𝑛, the suspicious model is considered an aggressive infringing model. If 𝑚 is less than 𝑛, it signifies an inconspicuous infringing model. Conversely, if 𝑚 equals 0, implying the suspicious model shares no sub-distribution with the source model, it is deemed an innocent model. As assumed in Section 3.2, the training data of the source
model is private to the model owner, meaning others cannot access these data or any data from the same distribution through legitimate means.
The instance level solution can be formalized follows:
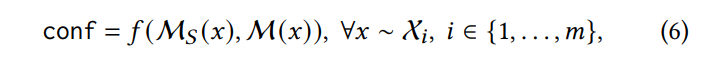
where conf is the confidence of whether the suspicious model M is an infringing one. The formulation indicates two problems: 1) how to prepare the input 𝑥, since sampling from the distribution X𝑖 cannot be exhaustive. 2) how to design the attribution metric 𝑓 . Next, we introduce two strategies to prepare the attribution input, and the detailed design of the attribution metric.
Attribution Input Preparation. The idea behind preparing input data is if a set of instances 𝑋 can minimize the generation error of the source model M𝑆 , then these instances 𝑋 are most likely to belong to a sub-distribution learned by M𝑆 . Consequently, if these instances 𝑋 also minimize the generation error on a suspicious model, it suggests that this model has also been trained on the same sub-distribution. This leads to a conclusion that the suspicious model infringe on the source model, as we assume that only the source model owner holds data in this sub-distribution. This assumption is reasonable and practical. If an instance is easily obtained from a public distribution and not private to M𝑆 ’s owner, there is no strong motivation to trace the usage. Since our instancelevel approach provides good interpretability, we can manually select those private instances from the instances prepared by our method for further investigation. We term these instances as key samples
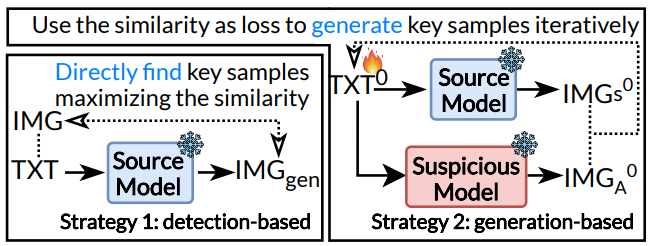
We develop two strategies to prepare key samples, namely, a detection-based strategy and a generation-based strategy. We illustrate these two strategies in Figure 5. The detection-based strategy aims to identify a core set within the training dataset of M𝑆 that minimizes generation error, which serves as representative samples of the model’s distribution. This strategy is quick and does not require any training. The generation-based strategy focuses on creating samples from the source model M𝑆 that can minimize the generation error. that can minimize the generation error. This strategy offers a broader sample space and superior accuracy compared to the detection-based strategy. Let’s detail how these strategies work.
Detection-based strategy. In this strategy, we start by feeding all text prompts TXT from the source model’s training dataset into the source model M𝑆 . From this, we generate images IMG𝑔𝑒𝑛. Next, we use the SSCD score [15] to compare the similarity between IMG𝑔𝑒𝑛 and their ground-truth images IMG𝑔𝑡. The SSCD score is the state-of-the-art image similarity measurement widely used in image copy detection[22, 23]. We select 𝑁 instances with the largest similarity scores as key samples:
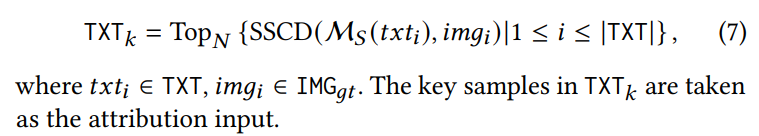
Generation-based strategy. In a text-to-image model, there are two components: the text encoder and the image decoder. For this particular strategy, we begin by randomly selecting a group of text prompts from the source model’s training dataset. We refer to these as seed prompts. Each selected text input (which we denote as txt) is comprised of 𝑛 tokens, i.e., txt = [𝑡𝑜𝑘1, 𝑡𝑜𝑘2, . . . , 𝑡𝑜𝑘𝑛]. The next step is to use the source model’s text encoder to convert each token of txt into an embedded form, producing c = [𝑐1, 𝑐2, …, 𝑐𝑛]. After this embedding phase, we optimize c over 𝑇 iterations to obtain an updated embedding, c′, The optimization’s objective is minimizing the reconstruction loss given by Equation 1 between the generated and ground-truth image.
Upon reaching convergence, we transform the optimized continuous text embedding c ′ back to discrete token embeddings. To do this, we find the nearest word embedding (referred to as c∗ in the vocabulary. However, because we carry out optimization at the word level, some of the resulting optimized embeddings may not make sense. To counteract this issue, we apply post-processing to the identified embeddings. We calculate the hamming distance between the located embedding c∗ and its matching seed embedding c. We then retain the top-𝑁 found embeddings, those with the smallest hamming distances. Lastly, using the one-to-one mapping between the word embedding and the token in our vocabulary, we generate the attribution input txt∗.
Attribution Metric for Instance Level Solution. Now we use the similarity between the output of the source and suspicious model conditioned by the key samples to instantiate the metric 𝑓 in Equation 6.

2.5 Statistical-level Solution

We leverage the shadow model technique from the membership inference attack [21] to gather the labeled training data for 𝑓𝐷 . It involves the following steps:

:::info
Authors:
(1) Likun Zhang;
(2) Hao Wu;
(3) Lingcui Zhang;
(4) Fengyuan Xu;
(5) Jin Cao;
(6) Fenghua Li;
(7) Ben Niu∗.
:::
:::info
This paper is available on arxiv under CC BY 4.0 license.
:::







{kind=link}