
The data center as we know it is being reimagined as an “AI factory” – a power- and data-optimized plant that turns energy and information into intelligence at industrial scale.
The tech stack is flipping from general purpose central processing unit-centric systems to graphics processing unit-centric accelerated compute, optimized for parallel operations and purpose built for artificial intelligence. Network fabrics are most critical to this transition with supporting elements that include disaggregated storage, governed data planes and a shift from app-centric operations to an intelligent, agentic control plane that orchestrates models, tools and process workflows. Simply put, investments in general-purpose computing are rapidly shifting to extreme parallelism, scale-up/scale-out/scale-across networking, as well as automated data governance built for AI throughput at massive scale.
In this Breaking Analysis, we delve into key aspects of AI factories. In this research note, we’ll:
- Define an AI factory
- Explain why now and the tectonic shift that’s occurring
- Put forth a reference architecture for the AI factory
- Drill down into networking
- Forecast and segment the market, looking at the gap between spending on AI factory builds and the revenue output from activities like token generation and other AI services
- Briefly touch on the economics of AI factories
- Explore the protocols and interoperability requirements
- Assess developer implications
- Close with a short view of some of the players that we see vying for dominance in this new era.
What is an ‘AI factory?’
TheCUBE Research defines an AI factory as a purpose-built system for AI production. Its job is to transform raw data into versatile AI outputs – for example, text, images, code, video and tokens – through automated, end-to-end processes. Those processes integrate data pipelines, model training, inference, deployment, monitoring and continuous improvement so intelligence is produced at massive scale.
In the definition, we emphasize “versatile outputs” because the factory spans modalities, not just token generation. The output is intelligence and we want the definition to reflect a broader set of outcomes that stand the test of time. The scope of our definition goes beyond hardware and encompasses the technical frameworks and practitioner architected workflows that orchestrate AI-optimized workloads.
In short, AI factories are large, specialized compute plants designed to create intelligence continuously, with quality and safety gates built into the loop.
AI factory reference architecture: Data in, intelligence out
The diagram below shows the flow of how AI factories convert raw data into intelligence. Think of power flowing in, data flowing through the system, and outcomes flowing out.
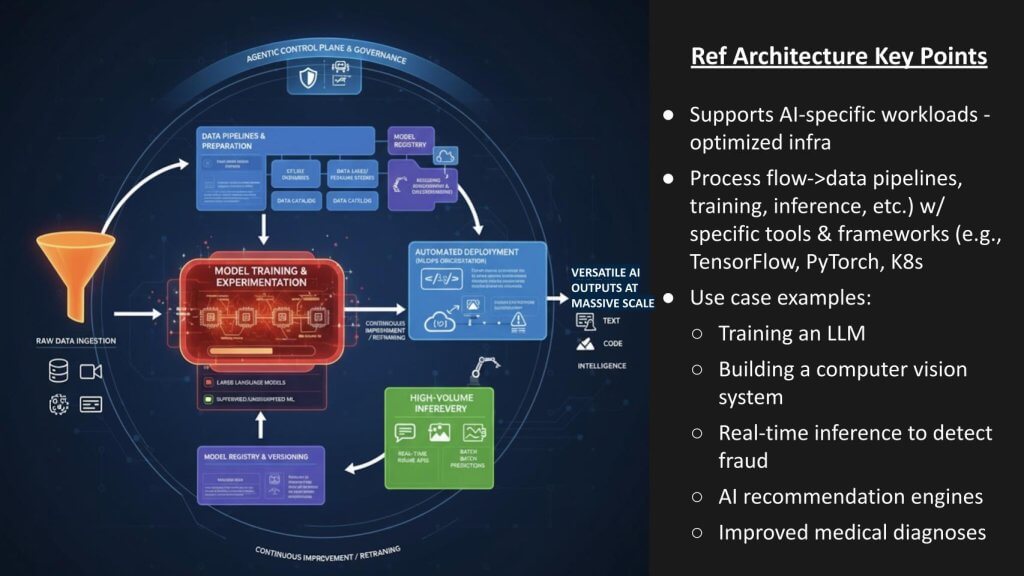
The workload is AI-specific and runs on accelerated, massively parallel infrastructure. The flow follows an automated process that uses AI pipelines → training/experimentation (You Only Look Once and others) → inference → deployment → monitoring → continuous improvement. Today this is built with TensorFlow, PyTorch, containers and standard containers, but those primitives will be abstracted from end users and potentially even developers.
Our view is that most enterprises won’t stand up these plants themselves unless they intend to be operators competing for token and other AI revenue. Rather they will consume application programming interfaces and software built on top by firms such as OpenAI, Anthropic PBC, other AI labs and cloud players. Return on investment will show up across a variety of industry use cases as shown above, including: large language model training, computer vision, real-time fraud detection with lower latency, recommendation engines, healthcare decision support and many others. The value is the real-time outputs, enabled by the plumbing.
Key takeaway: The factory architecture is complex. Today, every AI factory is a custom-built system and that may be the case in perpetuity. Our current thinking is enterprise AI will be adopted through access to mega AI factories via APIs and connectors with a software layer that hides underlying primitives and tools complexity that live under the hood.
A change in how work is done
We believe this infrastructure supports a profound change in business where the model of software as a service or SaaS evolves to service as-software or SaSo, meaning agentic-powered services will be delivered with limited human intervention (still human in the loop) to drive massive productivity gains.
As an example, imagine an autonomous financial adviser driven by AI. In this service-as-software model, a client simply feeds its financial data and goals directly to an intelligent agent. This agent instantly analyzes the data using machine learning, incorporating real-time market shifts, tax code changes and the client’s risk profile to generate and execute investment decisions or financial plans entirely on its own.
The human adviser is removed from the process until and unless the client wants additional human advice. An important nuance is the client pays not for the software itself, but only for the delivered outcome – such as optimized portfolio returns or a successfully managed retirement fund.
Key takeaway: This changes how wealth management businesses operate. There are thousands of examples across all industries that will be affected by these changes.
Stack flip: From traditional data center to AI factories
The graphic below is meant to depict the plate-tectonic shift occurring in infrastructure and software. Post-ChatGPT launch, the center of gravity moves from app-centric data centers to AI factories that manufacture intelligence.
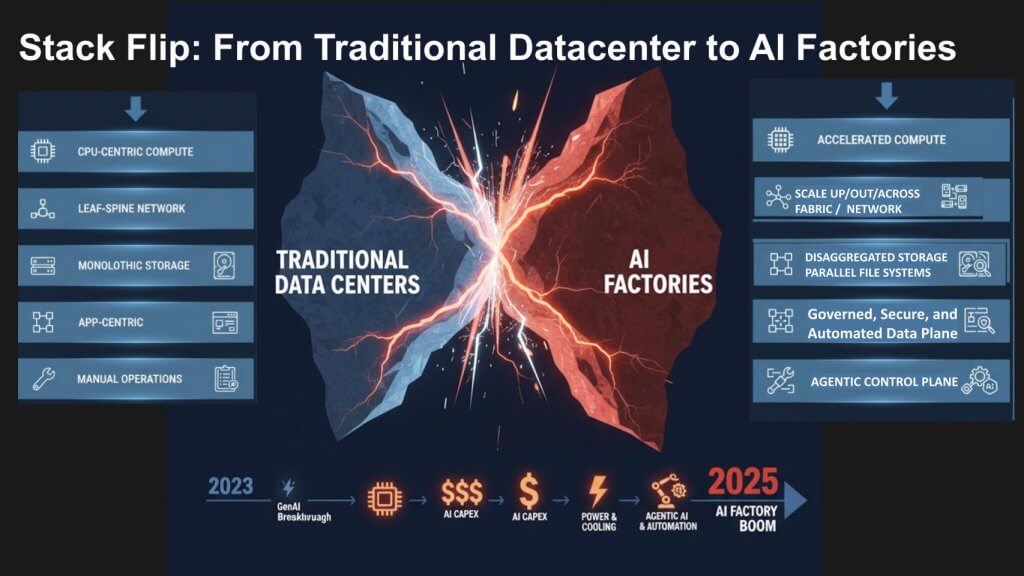
Traditional stacks were built top-down from the application then infrastructure was developed to support the app. In the future, infrastructure and software will be more pliable and able to support process flows that are built for purpose but more malleable. Think process LEGO blocks that are not static and rigid but rather can be developed in near real-time to suit a specific business objective.
Each layer of the stack is being rebuilt to manufacture intelligence, not just host applications.
The following points briefly describe some of the changes we see in the stack:
- Compute: The AI factory is built on on accelerated compute with extreme parallelism. Designs mix scale-up nodes for large models with scale-out clusters for throughput, stitched into scale-across pools for elasticity. Schedulers manage GPU utilization, memory bandwidth and interconnect saturation, and management transcends traditional CPU cores.
- Networking: Fabrics prioritize high bandwidth, ultra-low latency and loss avoidance. Features like adaptive routing, congestion control, quality of service, and topology awareness are tuned for collective operations in training and high-velocity burst flows to support inference. Traffic goes north-south, east-west and coast-to-coast. The network be considered to a degree as part of the compute.
- Storage: Disaggregated by default. High-performance I/O uses NVMe and parallel file systems for checkpointing and shard reads. Less active tiers use cheaper object stores for datasets, models and artifacts; archive tiers retain lineage and snapshot versions. Ultra-high-performance data movers prefetch and stage data to keep GPUs busy with small files and metadata prioritized to keep data flowing.
- Data stack (SoI): Above infrastructure sits a system of intelligence, or SoI, that models business state. It harmonizes data, metadata, features, vectors and process into knowledge graphs (or equivalent); tracks lineage and quality; and supplies policy-aware context to training and inference. This is the “high-value real estate” where perception, causality, and goals are encoded.
- Governance (automated): Policies feed into runtime controls that manage access, retention, privacy and audit trails. Observability monitors data, model access, provenance, prompts, tool calls and performance, enabling adjustments, rollbacks and continuous testing.
- Agent control frameworks: A control plane catalogs tools/actions, routes tasks, enforces guardrails, manages human-in-the-loop, and supports change management. It treats agents as fleets with versioning, service-level agreements and feedback loops tied back into the SoI; and guided by top down organizational key performance indicators.
Key takeaway: Most enterprises will not necessarily build these plants end to end; they will consume their services via APIs while integrating results into existing information technology. Regardless, we believe the stack is flipping from app-centric cost centers to intelligence factories accessed through APIs – separate plants that enterprises plug into for outcomes.
The critical role of networking
[Watch Bob Laliberte’s full analysis of the AI network and network for AI]
The slide below breaks networking into three dimensions – scale-up, scale-out and scale-across – because AI factories don’t work without bandwidth, determinism and low latency at every layer.
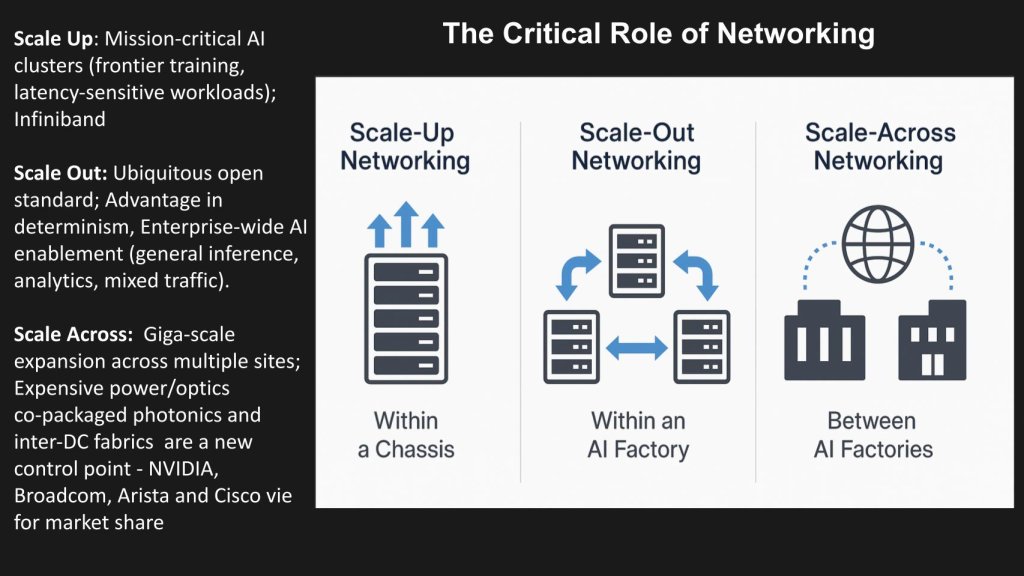
Networking is the second pillar after GPUs
- Scale-up (within a chassis): Intra-node acceleration focused on raw GPU performance and ultra-low latency. Technologies like NVLink/NVSwitch and PCIe Gen6 create a high-bandwidth fabric for frontier training and other latency-sensitive workloads.
- Scale-out (within a factory): Interconnects dozens to hundreds of thousands of GPU nodes in a datacenter. Ethernet and InfiniBand dominate, with vendors (Cisco, Arista, HPE, Juniper, Nvidia) delivering AI-tuned fabrics using RoCE v2, VXLAN EVPN, and rich telemetry. Recent silicon (for example, Broadcom Tomahawk 6, Thor Ultra 800G NIC) pushes clusters toward the 100,000-XPU range.
- Scale-across (between factories): Binds multiple AI sites/regions into a unified fabric for federated learning, cross-region inference and data-sovereign AI – while spreading power demand across locations. Nvidia, Cisco, Arista and new entrants (for example, LumaLens) are vying to deliver secure, deterministic, low-latency inter-factory links.
Key takeaway: Scale-up supports highest performance, scale-out delivers elasticity and scale-across enables regional AI factories. Together they form the backbone of distributed AI, connecting compute, data and agents within the bounds of tolerable latency.
Ethernet and InfiniBand: Where enterprise buyers find strategic fit (and why)
The slide summarizes our survey (done in collaboration with ZK Research) on fabrics for AI workloads and dovetails with Bob Laliberte’s analysis above. This fabric debate is much discussed in the networking community but we see it as an “and” not an “or” discussion.
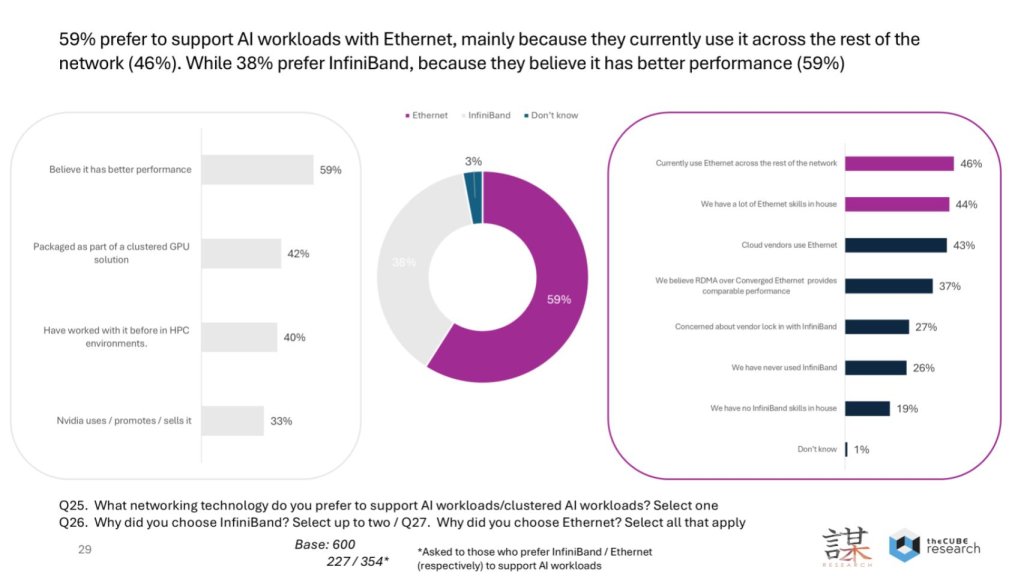
The data above shows 59% of organizations prefer Ethernet for AI, versus 38% for InfiniBand. The rationale is that Ethernet already underpins most environments (46% say it’s used across the rest of the network), teams have the skills (44%), and clouds standardize on it (43%). InfiniBand takes the performance high ground as nearly 60% of its adopters cite “better performance” – and it is often packaged with clustered GPU systems. It is also a staple of high-performance computing environments. But Ethernet is closing the gap on performance as AI-tuned implementations (e.g. RoCE v2, EVPN/VXLAN, rich telemetry) and new silicon push determinism and throughput higher.
Key points:
- Ethernet: Familiar, scalable, cloud-aligned, improving in performance
- InfiniBand: Best for the most performance-sensitive, tightly coupled training clusters
Key takeaway: We believe Ethernet will dominate the enterprise AI datacenter, while InfiniBand persists where absolute performance trumps everything else.
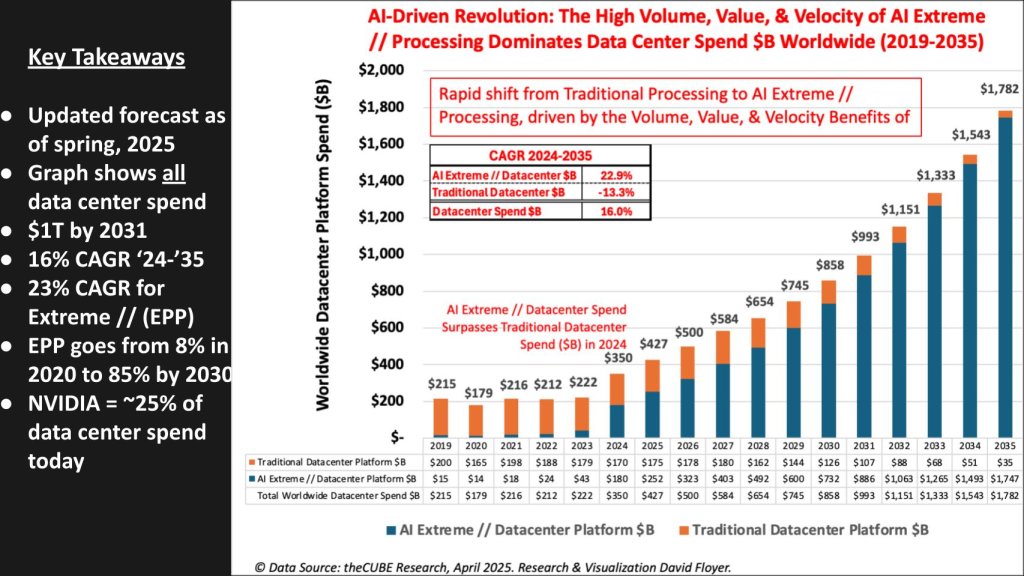
AI-driven revolution: Data center spend flips to accelerated compute
This forecast below (spring 2025 update) quantifies the build-out underway and includes building infrastructure, power, cooling, compute, storage, networking and core system software.
For a more in-depth analysis, readers may reference a previous Breaking Analysis with details on this data and further segmentation including on-premises/enterprise and cloud cuts.
For a many years, datacenter buildout spend hovered around $200 billion. In 2024 it jumped from $222 billion to $350 billion (+58% Y/Y) and, in our forecast, set a new trajectory. The model shows:
- Total DC spend compound annual growth rate ’24-’35: ~16% to $1 trillion by ~2031
- AI extreme/accelerated compute CAGR: ~23%
- Traditional compute CAGR: –13%, shrinking as budgets rotate to AI factories
- Mix shift: AI Extreme rises from ~8% of spend (2020) to ~85% by 2030
- Today, Nvidia captures ~25% of DC spend (and maintains share inside the model).
The stack flip is now visible in the profit-and-loss statements of hyperscalers, neoclouds and AI labs. CapEx focuses heavily on GPU systems and high-bandwidth networks, with disaggregated storage taking a smaller percentage than traditional data center spend, and includes power/cooling. Traditional general-purpose gear gives way quite dramatically to accelerated computing.
Key takeaway: We believe AI factories are converting traditional datacenter models from steady cost centers into growth engines, with accelerated compute driving the curve for the next decade and beyond.
Worldwide revenue from AI factories: Who captures the upside?
The chart below depicts the revenue generated by AI factories through 2030. It deliberately contrasts with the prior CapEx slide where spend approaches ~$1 trillion by 2030 while revenue produced from the AI factory is just under ~$500 billion – not unexpected but big numbers and a big gap.
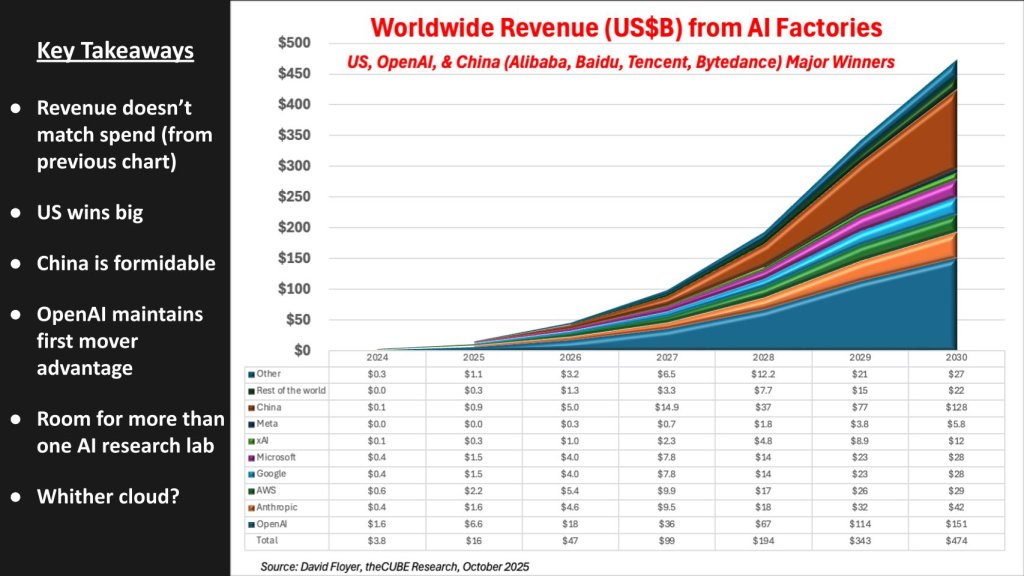
Revenue accrues not from selling base models but from software built on top via factory APIs. The premise is that factories expose connections that let vendors package outcomes and bill for usage.
- United States wins big; China is formidable. The U.S. leads near-term, but China “enters with a bang” – standing up national factories on domestic hardware/software. Even if done with brut force scale and plentiful energy sources, the scale yields meaningful revenue in this forecast.
- OpenAI retains first-mover advantage. Counter to our January 2023 prediction, it is estimated OpenAI will do ~$6.6 billion in 2025 revenue, growing with consumer/prosumer traction and expanding enterprise API adoption; the model places OpenAI at ~$150 billion by 2030, assuming it executes and avoids major missteps. Though this pales in comparison to the CapEx commitments it has made, the company seems to be on track to maintain its first-mover advantage.
- Anthropic shows momentum with strong corporate interfaces; our view is there’s room for more than one AI research lab, but all must evolve a durable business model beyond “foundation models.” In other words, it’s not the LLMs that matter it’s the software built on top.
- Google LLC and Meta Platforms Inc. monetize internally first (ads/engagement). That supports huge P&L impact, but while meaningful, less shows up as external “model revenue.”
- Microsoft Corp. is “fine” on two fronts – software franchises and operating factories. Its vast software estate, we believe, will protect it from massive disruption.
- Clouds (“whither cloud?”) stay large, but the upside shifts to platforms that convert APIs into software businesses. Amazon Web Services Inc. must transition a massive base of general-purpose compute to AI economics; execution from leadership (Amazon.com Chief Executive Andy Jassy, AWS CEO Matt Garman) is a key watch item.
Key takeaway: Revenue lags CapEx but accelerates toward players that turn factory APIs into repeatable, outcome-centric software. The U.S. leads, China surges and first movers – especially OpenAI – benefit from enterprise AI, with room for multiple labs if they land sustainable models.
Revenue by sector from US-owned AI factories
The chart below isolates U.S.-based corporations’ worldwide revenue from AI factories. It’s directional; “other” and China’s long tail could ultimately be larger. We don’t currently have good visibility and confidence to forecast the contribution from China and rest of world, which could be substantial and increase these figures by 3% to 50%, or more.
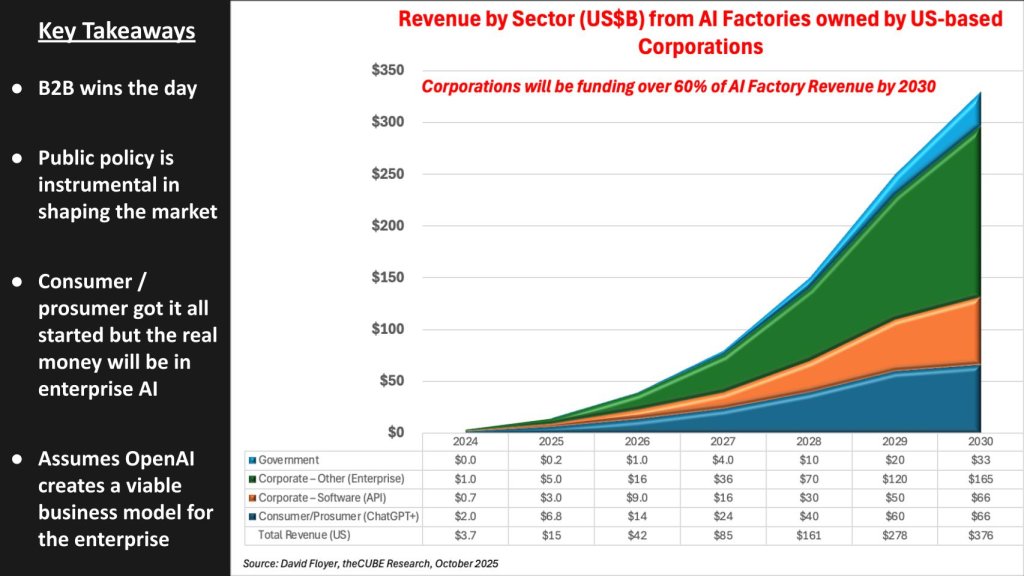
We believe business-to-business wins the day. Consumer/prosumer got it all started, but the go-forward dollars flow from enterprise APIs and services. The thesis is that traditional data centers decline as production moves to AI factories; corporate IT will consume intelligence via APIs (many won’t run factories), so vendors that expose reliable, governed interfaces will capture the spend. This view assumes OpenAI (and peers) develop a viable enterprise model – turning early traction in chatbots and coding into trusted, billable services for enterprises.
Government contributes a meaningful amount, but grows more slowly; procurement cycles and prior restrictions (for example, broad ChatGPT bans) delay uptake. Policy will still shape the market where security, data residency, export rule matter, but corporations will fund the majority of revenue by decade’s end. Trust remains a gating factor as enterprises will demand controls before sending proprietary data to third-party factories.
Key takeaway: In our opinion, the real money is enterprise AI: APIs first, services next, with B2B outpacing consumer while public policy sets the guardrails.
Interoperability: Open standards as a gateway to AI factories
[Watch Scott Hebner’s full analysis on interoperability standards]
The slide below from theCUBE Research’s Agentic AI Futures Index shows what enterprises will prioritize for interoperability in the next 18 months. The argument is generative AI is a gateway – like browsers were to the internet – but the value flows through AI factories on the back end.

The premise is that AI factories scale more easily if they’re open – but there’s divergence on this opinion in the community. On the one hand, history suggests that the “browser wars” ended when open protocols standardized the internet. Likewise, generative AI front doors (ChatGPT, Claude, Gemini, Grok) must pass through open models, protocols and APIs so intelligence can be widely consumed and integrated.
Enterprises don’t want fragmentation or lock-in; they want safety, determinism, and portability. Survey data suggest that 59% of respondents prioritize open models/protocols/APIs; 58% extensible adapters/connectors; 55% agent integration/collaboration; 52% composable workflows (any agent); 52% common semantic layers (N=625).
On the other hand, because every AI factory buildout is a “snowflake,” requiring high degrees of customization, the counter-argument suggests that de facto standards or even proprietary elements of the AI factory stack may emerge as viable and even winning. In many ways, Nvidia represents the epitome of this debate. On the one hand, its proprietary hardware and software kit have powered this new era of AI. At the same time, the company has embraced open standards like Ethernet and it open sources many of its innovations in AI, robotics, data science graphics and more.
Generally our view is standards are the like the “grid” – the circuits, breakers and regulators – for the intelligence pipeline, making agent communication and an agentic control plane practical. Vendors (Nvidia, Advanced Micro Devices Inc., Intel Corp., others) are taking steps, but, as indicated most AI factories are only semi-open – and risk fragmentation, like the cloud. As Scott Hebner phrased it: “95% healthy with 5% rat poison still kills you; advocating the industry to go all-in on openness.”
Key takeaway: Our view is the history of IT waves has been won with de facto standards out of the gate, with open de jure standards proving to be the accelerant to ecosystem flywheels. For AI factories to deliver service as software at scale, we believe open standards will help intelligence flow safely and reliably across agents, apps and enterprises. But the starting point will necessarily require proprietary innovation and vertical integration to prove ROI.
Counterpoint: Abstraction may eclipse ‘visible’ standards
The previous survey shows enterprises want open models, protocols, and standards. That reflects how IT works today. The counterview is the layer most practitioners and users see will be abstracted by software leaders/innovators like OpenAI and its peers, and possibly clouds – that will compete by hiding complexity behind simplicity.
A reasonable argument is the client-exposed experience will converge to APIs and managed services, that hides plumbing. This is somewhat visible already in developer services with richer primitives, tighter integration and opinionated defaults bundled into a single offering. The possible outlook is:
- Bundle the model, tools, safety, data-plane hooks and the like into one service.
- Govern by automated policy controls, audit and compliance built into the API.
- Scale centrally: AI factories run in massive data centers; most corporations won’t operate them, they’ll consume them.
Nonetheless, providers earn enterprise trust with governance and transparency and open standards support that ethos. Timing-wise, we believe the abstraction layer must materialize by 2027-2028, when our forecast calls for OpenAI to cross a $40 billion to $50 billion run-rate and the service envelope becomes a “hardened top.”
Key takeaway: Open standards matter, but the visible interface may be simple APIs. In our view, a winning strategy is to wrap industrial AI factories in secure, governed abstractions that enterprises can adopt without having to touch the mechanics.
Accelerated computing and service as software: The AppDev perspective
[Watch Paul Nashawaty’s detailed analysis on the DevSecOps angle on AI factories]
This section frames how AI factories change day-to-day software work – what developers build, how platforms are run and where security lives.

Accelerated computing is resetting expectations for latency and scale. Specialized GPUs/tensor processing units/field-programmable gate arrays are driving ~46.8% YoY growth to ~$157.8 billion in 2025, enabling real-time analytics, AI-driven decisions and large-scale simulation. That performance comes with application modernization. Services tied to replatforming and continuous integration/continuous deployment or CI/CD expand from ~$19.8 billion (2024) to ~$39.6 billion (2029) as enterprises re-architect to cloud-native patterns.
The operating model moves with it. Platform engineering shifts focus from “deliver infra” to “deliver developer experience.” Our research indicates that co-managed platforms free 47% of developer time for innovation vs 38% for internally managed estates, driven by internal developer portals, self-service environments, infrastructure as code, containers and observability. Security is continuous, not a blocker. DevSecOps trends that stand out are: Shift-left testing, AI-assisted detection/response, and zero trust. These fuel a market tracking toward ~$41.7 billion by 2030 (~30.8% CAGR). Human-in-the-loop remains a key design point.
All of this leads to service as software – agentic, process-centric apps that run on governed platforms and monetize outcomes, not features. Winners will reduce friction (less glue code), expose safe self-service, and keep auditors and SREs whole while velocity accelerates.
Recommendations
- Assess readiness: Target modernization and acceleration where it pays; don’t refactor without a reason
- Invest in platform engineering: Stand up secure, self-service IDPs with strong observability and automation
- Embed DevSecOps: Make security a continuous control with AI-assisted workflows and zero trust
Key takeaway: We believe the convergence of acceleration, modernization, platform engineering, and DevSecOps is the operating act for AI factories— – and the practical path to service as software.
Market map: Who’s vying for mindshare
The Enterprise Technology Research scatter plots spending momentum (Net Score) on the y-axis against installed penetration/overlap on the x-axis across ~1,800 respondents, all sectors. It’s a cross-ecosystem snapshot – not a single category cut.
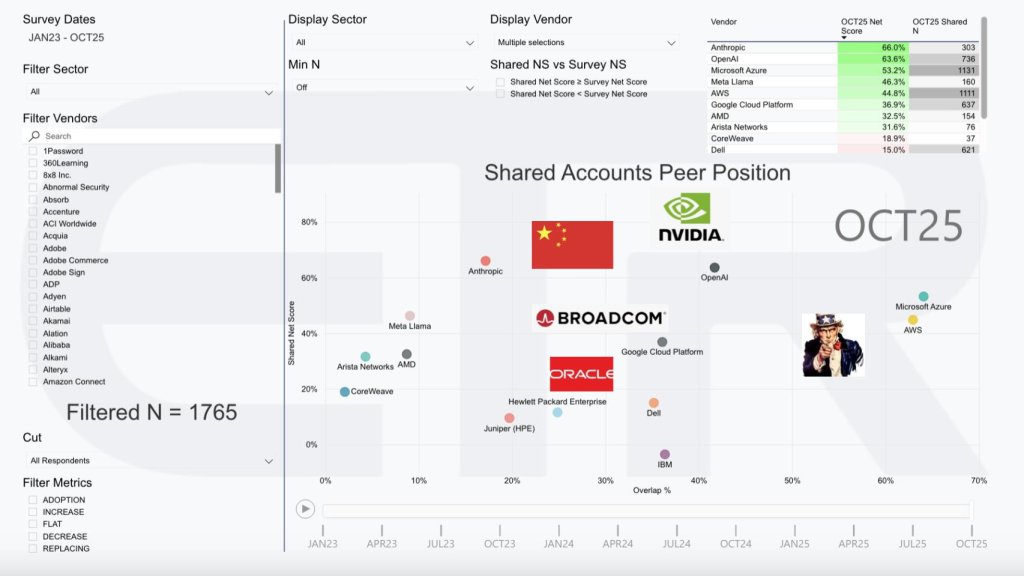
The upper-right is crowded with hyperscalers and leading AI platforms – Microsoft, AWS, Google, OpenAI – with other AI labs with less presence (Anthropic, Meta, etc.). – Nvidia sits on top with momentum, reflecting its central role in accelerated compute. Networking (Arista Networks Inc., Cisco Systems Inc., Juniper Networks Inc.), semis (AMD, Intel, Broadcom Inc.), infra OEMs (HPE, Dell), and “neoclouds” (CoreWeave Inc., Lambda Labs Inc. others) round out the group with Oracle Corp. playing a more prominent role in AI. We also flag public sector (Uncle Sam) and China (both its government and major AI players) as structural demand drivers and policy shapers, and note the expanding role of energy companies (not shown) as capacity and power become gating resources.
The message isn’t just who’s hot; it’s where enterprises plan to buy as they will continue enhancing their own datacenters with high-degree parallelism (feeding Nvidia et al.), but the most important partners will be (1) API providers exposing factory capabilities and (2) software vendors packaging those APIs into outcomes. That’s where spend converts into profit.
Key takeaway: Our view is that AI factories create a multitrillion-dollar opportunity, but value bifurcates: Picks and shovels win the build-out, while API + software providers win recurring revenue by turning manufactured intelligence into business outcomes.
Disclaimer: All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by News Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of theCUBE Research. None of these firms or other companies have any editorial control over or advance viewing of what’s published in Breaking Analysis.
Image: theCUBE Research
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
- 15M+ viewers of theCUBE videos, powering conversations across AI, cloud, cybersecurity and more
- 11.4k+ theCUBE alumni — Connect with more than 11,400 tech and business leaders shaping the future through a unique trusted-based network.
About News Media
Founded by tech visionaries John Furrier and Dave Vellante, News Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.






{kind=link}