
Our latest forecast indicates that it will take a decade or more for artificial intelligence factory operators and model builders to reach breakeven on their massive capital outlays.
Our projections call for nearly $4 trillion in cumulative capital spending outlays by 2030, with just under $2 trillion in cumulative AI revenue generated in that timeframe. We have the crossover point occurring early next decade (2032 on a run-rate basis) then gains far surpassing initial investments by the middle part of the 2030s. Though such projections are invariably subject to constant revision, we believe the size and speed of the initial investments, combined with the challenges of profitably monetizing AI at scale, will require patient capital and long-term thinking to realize durable business results.
Background
A short time after we published our first AI factories revenue outlook, OpenAI Group PBC Chief Executive Sam Altman and Microsoft Corp. CEO Satya Nadella introduced new data on the BG2 Pod. As well, on Nov. 4, The Information published projections from Anthropic in an article that also included financial projections on OpenAI based on multiple unnamed sources.
This fresh information gives us an opportunity to revisit our figures and do so in the context of economist Erik Brynjolfsson’s productivity J-curve, which explains why new general purpose technologies, like electricity, the steam engine, computing and AI, often experience limited productivity growth at first, because organizations must learn, adapt and reorganize in order to realize benefits. Over time, these innovations tend to outperform expectations.
Importantly, our forecasts focus on the business case for AI factory operators currently funding the massive AI buildout – specifically, the big CapEx spenders, including hyperscalers, neoclouds and AI research labs building today’s large language models. We do not attempt in this exercise to go down the “rabbit hole” of forecasting the investment and productivity output from enterprises consuming AI services. These are, however, related as the pace of both consumer and enterprise AI adoptiion will ultimately fuel monetization that AI factory operators will realize.
In this Breaking analysis, we analyze these new data points and debate the shape of the AI factories economic curve. We’ll briefly introduce the productivity J-curve, share snippets from the Sam and Satya statements that in many ways speak to the AI productivity paradox. We’ll then revisit our AI factories forecast and assumptions; discuss some of the headwinds the industry must overcome to reach our projections and close with a vision of the future of AI and service as software.
The productivity J-curve
The productivity J-curve is a phenomenon where traditional measures of productivity growth initially dip before rising after the adoption of a new general-purpose technology or GPT. This occurs because a novel technology, such as AI, requires significant, but hard-to-measure, intangible investments in areas like employee training and business process redesign. These initial investments can cause temporary negative productivity impacts, but once organizations learn to productively apply the technology, full benefits are realized and productivity growth appears, often in quite dramatic fashion.
The concept of the productivity J-curve was developed and modeled by the economists Erik Brynjolfsson, Daniel Rock and Chad Syverson. Recently, on theCUBE at UiPath Fusion, we asked Erik Brynjolfsson to explain the productivity J-curve in the context of today’s AI boom:
[Watch Stanford economist Erik Brynjolfsson describe the productivity J-curve and how it relates to AI]
Back when I was a young student in Boston, where I guess, I think we first met over there, I was working with Bob Solow, the Nobel Prize winner, and he pointed out that the computer age was everywhere, except the productivity statistics. So he asked me to look into this, and one of the things we saw was that all these companies were investing in these really amazing technologies, but nothing very valuable was coming out. And then later, as we know, in 1995, things started really taking off. And so I did some research, and the same pattern happened with lots of earlier technologies. With electricity, it was like 30 years, in fact, before you had a big boom. The steam engine. And so when I analyzed it, what we see is that these cool technologies, to really get the benefit of them, you have to rethink your business processes. You have to invest in human capital training, and so forth, and all that takes time and energy. And while you’re doing that, there’s not a lot of new output.
So you’ve got more input, not a lot of output. By definition, that’s lower productivity. But then once you figure that out, things really take off. So to me, it kind of looks like a J, and we plot it. We did a paper in the American Economic Journal about that, to kind of work out the math of it. And now we’re seeing, I think, the same thing with AI.
In our view, the productivity J-curve, at least in part, explains today’s AI return-on-investment paradox. Early adoption of general-purpose technologies is messy, utilization is uneven, workflows and data aren’t ready, and traditional measures of productivity often show dips before durable gains appear in the macro. The latest MIT and recent Enterprise Technology Research data points suggest only modest near-term ROI impact – single digits to low teens of enterprises seeing sustained ROI at scale.
We’ve often said that agentic AI will take most of a decade to mature and permeate enterprises broadly. If we count inputs as AI CapEx and outputs as AI factory revenue, current productivity is negative, which helps explain market jitters and bubble talk. We believe near-term skepticism is unsurprising and the payoff depends on raising utilization, improving data quality and putting governed and secure agents into operation so that spend translates to tokens, and token production converts to revenue.
Sam Altman gets defensive about OpenAI revenue numbers
Industry consensus had OpenAI revenues at about $13 billion. In a conversation with Altman, Brad Gerstner asked the obvious question: “How can a company with $13 billion in revenue make $1.4 trillion in spend commitments?” This raised Altman’s ire to the point where he spilled some revenue estimates that hadn’t been previously shared.
[Watch Altman bristle at the criticisms]
Specifically Altman said:
- OpenAI is doing “well more” than $13 billion; and
- Altman suggested they would hit $100 billion in revenue by 2027, not ’28 or ’29 as most estimates have indicated.
Our further research indicates that both of these estimates are run-rate revenue projections. As such, we put OpenAI 2025 revenue at $15 billion. Moreover, in the clip above, Nadella lends credibility to Altman’s statements by claiming he’s never seen a business plan from OpenAI that the company hasn’t met or exceeded.
Jackie McGuire of theCUBE Research had the following takeaways on Altman’s and Nadella’s comments:
I think their tone tells you a lot about the message. To me, Sam actually sounded a little bit defensive in the “We’re doing well more than 13 billion.” It sounded to me like on one side that we’re doing way better than that. And on the other side, “I’m telling you guys, this is a sure bet. Take the Dodgers in the World Series. I’ve never seen them not lose a game.” There was an article last week in Wired that was called AI is the Bubble to Burst Them All. And it was talking about what the different things are that characterize a bubble, how people talk about it as one of them. And yeah, I don’t know. I just found the tone to be very more defensive than I would expect for somebody that feels really, really secure in the amount of revenue they’re doing.
This narrative, as the Wired article reminds us, echoes the hype around RCA in the 1920s. Andrew Ross Sorkin in promoting his new book, “1929,” makes similar comparisons, with OpenAI as today’s analog. But it has faster execution, a bigger installed base and a much more mature communications infrastructure in its favor. Pulling OpenAI’s revenue projections forward suggests a meaningfully higher trajectory for the company.
Nadella’s commentary frames OpenAI as an “execution machine” and is encouraging. Coupled with about 800 million monthly active users and what the company claims is 1 million enterprise API customers, demonstrates a blistering cadence and a glimpse of what the next great software company may look like.
Updating the AI factory forecast
In the graphic below, we update our earlier AI factory forecast which reframes the datacenter buildout at an accelerated pace. The relevance is this represents the CapEx that ultimately foots the AI bill. Datacenter investments require land, power, water, distribution, thermal systems, and the accelerated stack itself – compute, storage and networking. The AI piece of the forecast (dark brown bars) is astounding and forcing a stack flip to extreme parallelism.
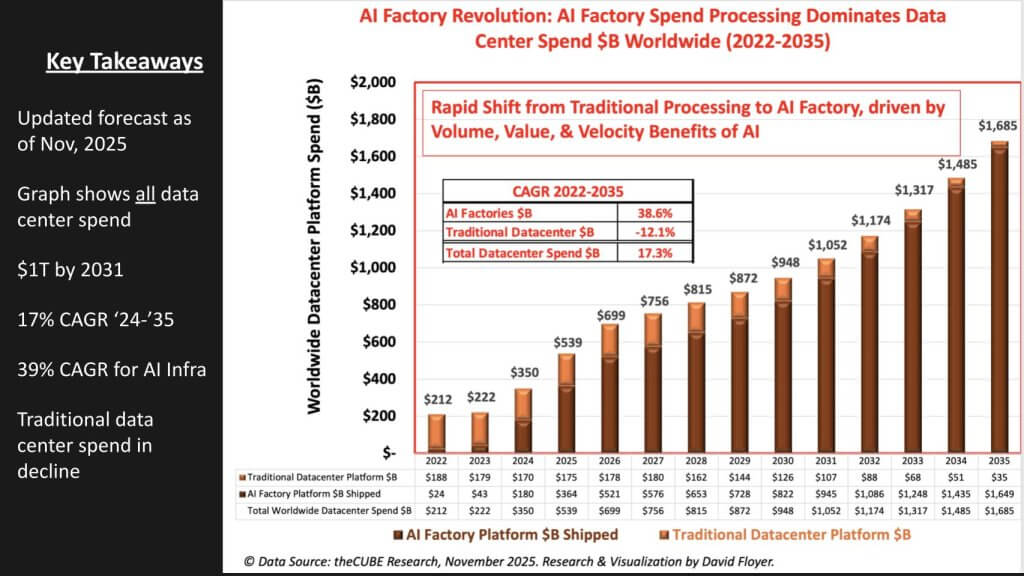
The following key additional points are notable:
- Total data-center platform spend accelerates to ~$1 trillion by 2031 and $1.69 trillion by 2035, implying a ~17% CAGR (’24-’35);
- AI factory spend overtook traditional data center in 2024 (~$180 billion vs. ~$170 billion) and dominates thereafter, reaching ~97% of total by 2035;
- AI factory spend grows at ~38.6% CAGR (’22-’35), while traditional DC spend declines ~12.1% CAGR, evidencing a wholesale stack flip;
- By the late decade (2030-2031), traditional DC becomes a small residual slice (low-hundreds to double-digit billions of dollars) as AI platforms drive nearly all growth;
- The shift is volume, value and velocity-driven: sustained double-digit total growth is almost entirely explained by the AI factory ramp rather than legacy platforms.
The pace of the buildout steepens relative to our April forecast reflecting disclosures from recent earnings prints and deal signings that indicate OpenAI has secured a disproportionate share of advanced package/graphics processing unit capacity, while Google LLC has stepped up commitments, along with other hyperscalers and Meta Platforms Inc. Taken together, these inputs justify pulling forward AI-factory outlays. As we’ll show below, revenue ramp lags in the model when assessing cumulative spend vs. cumulative revenue.
The most recent forecast implies that although hyperscalers, neoclouds and specialist providers will operate much of the capacity, enterprises will ultimately need to underwrite a majority of the economics over time via consumption. This will happen extensively through cloud, neoclouds and colo channels as well as selective on-premises deployments, especially as edge AI matures.
While Wall Street rightly notes the hyperscaler and neocloud GPU estates are “lit up,” enterprises running clusters of 1,000-plus GPUs often sit below 30% utilization because of thin parallel-computing muscle memory, immature workflows and data friction. That underutilization is stressed by rapid hardware depreciation; unlike dark fiber in 2000, GPUs lose value fast. In our view, if enterprises cannot translate capacity to tokens and productivity, ROI will accrue elsewhere in the value chain until operating discipline catches up.
Endpoints are a potential tailwind as an AI PC refresh cycle will push more inference to the edge, and a return to pragmatic hybrid is likely as organizations balance economics, latency, privacy and the practical limits of data movement. The operational reality is we live in a 12- to 18-month replacement cycle with e-waste and labor challenges implying a perpetual “paint-the-Golden-Gate-Bridge” refresh cadence applied to rows and racks of infrastructure.
Hybrid AI will also be deployed by enterprises. As such, choice and flexibility across on-prem/colo/public will matter and upgrade timelines will vary, which argues for architectures that let teams “tap the public” while local capacity evolves (the labor and talent constraints are visible in the workforce data we present later).
Data gravity and storage economics are also at play. We expects a meaningful share of cost to sit in storage and data management, not just GPUs. We will likely see renewed interest in deep, economical tiers (including tape) and a storage-vendor arms race to live closer to the accelerators, because data readiness, lineage and metadata for agentic workflows are gating factors to scale. The net is the spend is real and earlier, but breakeven will stretch beyond a decade with improvements in utilization, fabric efficiency and governed data pipelines taking time.
In our opinion, the operating agenda is raise money, do deals, build fast, secure power and GPUs, increase utilization, compress network latency, harden governed data planes and sequence hybrid capacity so depreciation curves don’t outrun value realization.
Forecasting revenue generated by AI factories
The data below represents revenue output from AI factory operators. It does not represent the value created by mainstream enterprises driving productivity and contributing to the macro gross domestic product uplift. Forecasting that impact is a separate exercise that requires assumptions about firm level productivity impacts. Rather this forecast is meant to help us model the revenue return on the massive CapEx buildup happening with AI, which will power a massive productivity boom in our view.
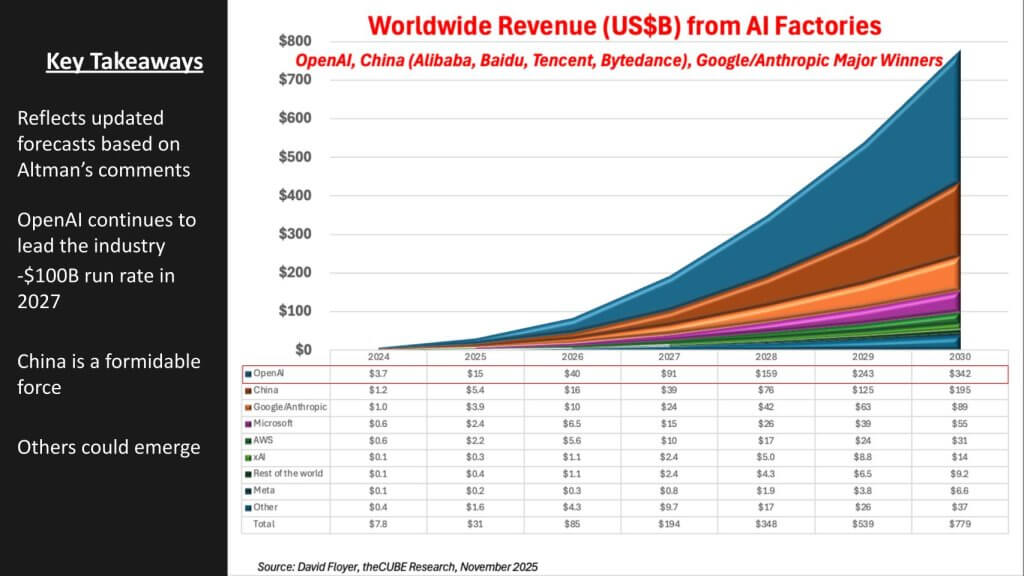
The following five key messages are conveyed in the data:
- AI factory revenue growth: An incredible 115% CAGR (’24→’30);
- AI-factory revenue explodes to ~$780 billion by 2030 (from ~$8 billion in 2024), with the curve steepening sharply after 2026 as deployed capacity commercializes;
- OpenAI dominates the leader board, rising from ~$4 billion (2024) to ~$342 billion by 2030 and crossing a ~$100 billion run rate in 2027, driven by superior funding/compute access, deep partnerships and high-quality software on top of frontier models;
- China emerges as a formidable bloc, scaling from ~$1 billion (2024) to ~$195 billion by 2030, reflecting national champions (Alibaba, Baidu, Tencent, ByteDance) converting domestic demand into large AI-factory businesses;
- Google + Anthropic act as a combined growth engine: Google’s tensor processing unit and platform moat plus Anthropic’s model/software prowess produce a strong joint trajectory (to ~$130 billion by 2030). Microsoft, Amazon Web Services Inc., xAI Holdings Corp. and others grow, but at smaller absolute scales in this scenario;
- Mainstream enterprise revenue is largely indirect: Most organizations consume AI via application programming interfaces rather than building out massive AI factories; revenue concentrates with factory operators (hyperscalers, neoclouds, OpenAI, Chinese majors and a handful of others).
Our updated revenue forecast reflects a steeper commercialization curve for AI factories, with OpenAI’s trajectory set higher based on the new information. The near-term ~$20 billion run rate this year and a path to ~$100 billion by 2027, is based on growth initially fueled by consumer/prosumer demand and then accelerated by a rapid cadence of APIs and software that connect to enterprise data. We group Google and Anthropic as a combined partnership because TPU capacity and tight technical alignment make joint scaling plausible even as each maintains distinct channels; and Anthropic has a close partnership with AWS. We assume China’s block rises on restricted access to U.S. technology, which concentrates domestic investment and demand.
A core debate from theCUBE Research team is whether a vertically integrated, more “closed” approach can sustain leadership versus an “open grid” that standardizes inter-factory integration. On one side, we argue that without open standards and protocols, multicompany business-to-business workflows risk fragmenting into a patchwork of proprietary adapters, repeating early cloud pain and slowing the “intelligence economy.”
Trust requirements (transparency, accountability) and the cost of data movement and governance reinforce the case for openness; unified enterprise data will be the gating factor and creates room for data mobility vendors to grab a piece of the market. On the other side, we note that de facto standards have repeatedly led markets – IBM/360, Windows on commodity PCs, AWS primitives, iPhone, CUDA and the like – where proprietary control plus ecosystem gravity created the interoperability that matter in practice. In that view, surviving factories will define interfaces bilaterally and at scale, then formal standards follow.
Key assumption: Enterprises will mostly consume AI via APIs; interoperability will improve through a mix of de facto interfaces and selective open standards; unified, governed data is the real prerequisite to value capture.
Netting it out, the forecast supports OpenAI as the current favorite in the race. Advantaged by funding, compute access, fast software/API velocity and deep partnerships, we see this compounding into share gains even if the posture is more closed than purists would like. We acknowledge the risk that openness wins the long game; however, history suggests that de facto standards often dominate first, with formal openness catching up later.
Our base case therefore keeps OpenAI in the lead, while watching for evidence of durable open protocols that would shift share toward more open operators.
The decade-long J-curve: CapEx runs ahead of AI factory revenue
The chart below shows our cumulative CapEx forecast required to build AI factories (orange line) and the token revenue from those factories green line. As you can see, this business is not for the faint of heart, as described by the points below.
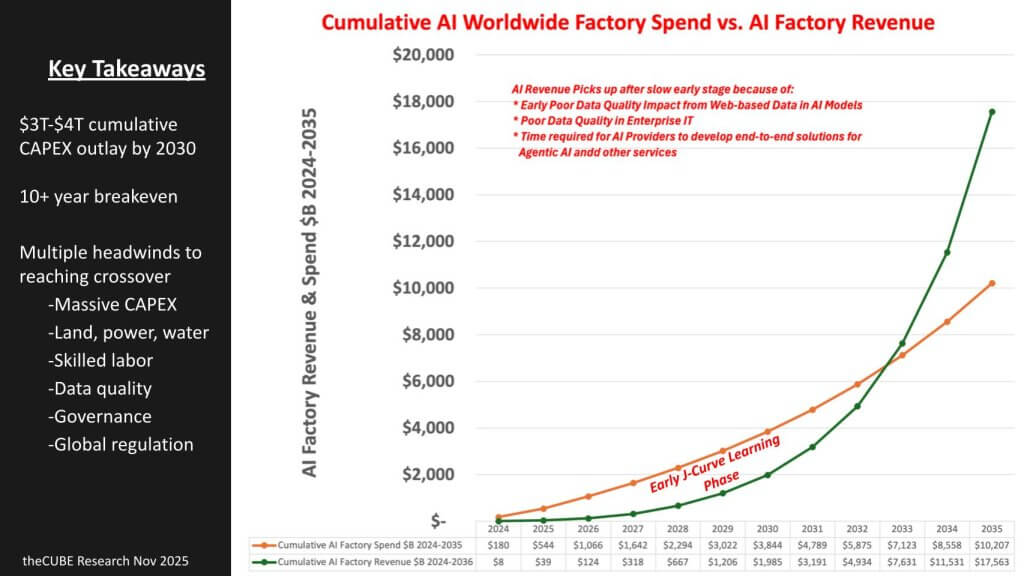
- A massive gap opens up: Cumulative AI-factory CAPEX hits ~$3 trillion to $4 trillion by 2030, while cumulative revenue lags materially through the decade;
- Breakeven is a long way out: The curves don’t cross until ~2032 on a run rate basis – (10-plus years from the start of the build), underscoring a protracted J-curve;
- Early J-curve drag: Revenue starts slow due to learning curves, poor enterprise data quality and time-to-solution for end-to-end agentic services;
- Physical and operational headwinds: Power/land/water constraints, skilled labor, governance and regulation slow time-to-tokens and keep utilization below potential;
- Operator discipline determines payoff: Utilization, fabric efficiency and governed data pipelines at the end-customer level are the factors that compress the gap;
- Big rewards for those operators which can cross over breakeven. The slope of the green curve represents our assumptions that broad productivity improvements will begin to show up in the macro and show sustained durability – powering the most significant tech wave ever.
We believe the cumulative-spend vs. cumulative-revenue forecast underscores the AI productivity paradox in that a multitrillion-dollar CapEx wave begins in 2024, but revenue trails for a decade-plus, yielding an early J-curve where measured productivity looks low or even negative. The spend line reflects the full factory build – land, power, water, distribution, thermal and accelerated stacks – while the revenue line captures commercialization that starts slowly and steepens only after end-to-end solutions mature.
In our analysis, three inhibitors dominate the early years: 1) Weak data quality – web data is noisy and enterprise data is also challenging – requiring time-consuming cleanup, harmonization and policy controls; 2) The need for the industry to package and ship a unified, trustworthy agentic software layer that enterprises can adopt without bespoke integration; and 3) The sheer denominator problem – so much CapEx goes out up front that catching up takes time even as utilization improves.
There is broad agreement that value creation ultimately skyrockets as the operating leverage kicks in; the open question is pace. Some argue the crossover could come sooner for targeted, high-value workflows rather than blanket enterprise adoption, while others maintain that the scale of CapEx alone pushes breakeven out ~11 years.
Headwinds we see: Land/power/water constraints; skilled labor and operational cadence; poor/fragmented data and governance; evolving regulations (and geopolitical frictions) that complicate data movement; and the learning curve to stand up agentic control planes. Netting it out, the forecast dovetails with our key takeaways – a large near-term gap, a long breakeven, early J-curve headwinds, heavy physical/operational constraints and a path to compress the gap by securing energy, lifting utilization, tightening fabrics and hardening governed data pipelines.
Power, water and the geography of AI factories
We believe Deloitte’s “Can US infrastructure keep up with the AI economy?” report articulates a central constraint to our thesis: Energy and water availability – and the speed of grid expansion – will set the pace of the buildout.

AI racks run hotter and denser than legacy estates, pushing a structural shift from evaporative to liquid/mechanical cooling and forcing operators to site facilities where dual utility feeds are feasible for redundancy. That is driving builds toward inland markets with favorable land and interconnects but limited local talent pools, while creating visible, localized electricity price inflation in the two to three years following large deployments.
In the near term, backup generation remains largely diesel and the grid mix still leans on fossil sources; corporate power purchase agreements and new renewables help, but lead times are long. Nuclear is re-entering the conversation as one of the few scalable, round-the-clock options capable of matching multigigawatt AI clusters over the decade.
In our view, this energy reality dovetails with the J-curve economics in that even if capital is available, the tempo of power procurement, water rights and cooling retrofits slows time-to-tokens and represents a headwind to revenue realization. The practical takeaway is that breakeven moves with infrastructure, not just silicon.
Implications: Operators will prioritize sites with dual-feed capacity and water sources; lock long-dated PPAs while exploring nuclear options; expect localized utility rate pressure; plan for liquid cooling skills and supply chains; treat energy procurement as a first-class program office alongside networking and data governance.
Who actually builds the AI factory? The acute talent constraint
The Deloitte study lays out many challenges and solutions to building out AI infrastructure. Perhaps one that is most underappreciated is skilled labor. We believe a key blocker after power is people.
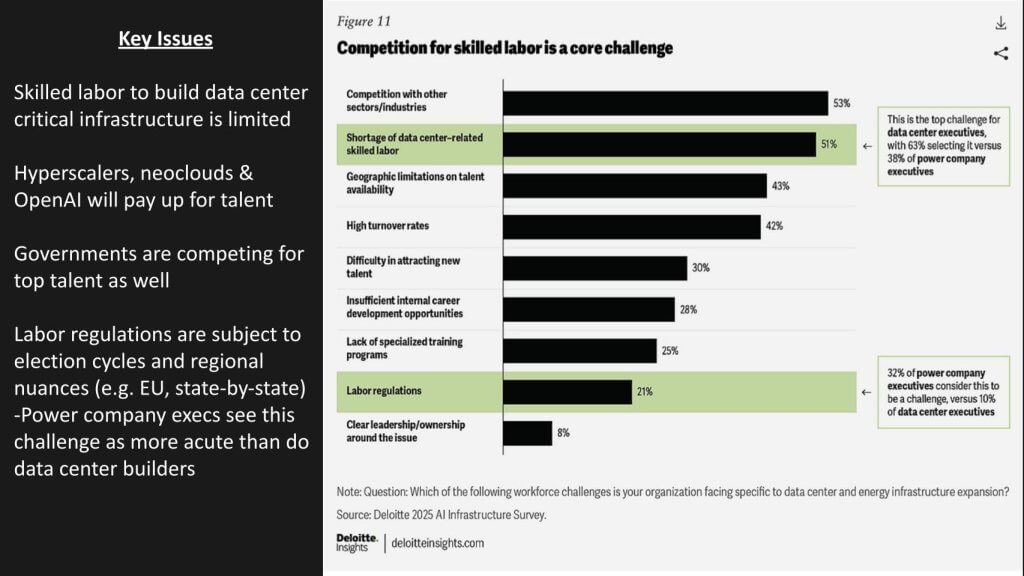
Deloitte’s survey shows competition for skilled labor and a shortage of data-center-specific skills as the top workforce challenges. Building and operating AI factories requires niche trades – nuclear engineers, diesel-gen technicians, high-capacity chiller mechanics and specialized welders – not generic information technology staff. These workers are scarce, unevenly distributed and often unwilling to relocate to inland locations where dual-feed power and water are available, pressuring wage inflation and scheduling risk.
The data underscores the point in that respondents cite competition with other sectors (~53%), a shortage of data-center–related skilled labor (~51%), geographic limits on talent (~43%), and high turnover (~42%) as primary obstacles. Labor regulation adds friction as well; notably, power-company executives flag regulation as a challenge far more often than data-center builders, reflecting state-by-state and EU-style variability. Against that backdrop, hyperscalers, neoclouds and well-funded operators will pay up for the best people, while governments are also in the hunt – tightening the market further.
In our view, solving the talent gap requires a multiyear effort – national and regional programs to retrain displaced workers; vocational pipelines starting in high school for advanced welding, mechanical and electrical trades, fluid engineers that understand advanced plumbing; and increased use of robotics to service multibuilding campuses measured in football fields. Without this workforce ramp, the CapEx-revenue crossover slips, regardless of how fast silicon ships.
Software: From zero marginal costs to service as software
Satya Nadella made the following statement:
So the new SaaS applications, as you rightfully said, are intelligent applications that are optimized for a set of evals and a set of outcomes that then know how to use the token factories output most efficiently. Sometimes latency matters, sometimes performance matters. And knowing how to do that trade in a smart way is where the SaaS application value is. But overall, it is going to be true that there is a real marginal cost to software this time around. It was there in the cloud era too. When we were doing CD-ROMs, there wasn’t much of a marginal cost. With the cloud, there was. And this time around, it’s a lot more. And so therefore, the business models have to adjust and you have to do these optimizations for the agent factory and the token factory separately.
AI is shifting the margin math again. The CD-ROM era drove marginal cost toward the price of plastic; SaaS reintroduced a cloud OpEx tax; AI adds the heaviest burden yet – rapidly depreciating GPUs, power and specialized labor – so headline gross margins compress even as volume potential explodes. Those dynamics align with recent comments about marginal cost pressure and sets the stage for what we view as the more important transition – George Gilbert’s service-as-software or SaSo thesis. In SaSo, factories expose agentic capabilities as programmable services, enterprises consume them through APIs and lightweight local runtimes, and the “software-like” economics accrue disproportionately to buyers (productivity) and to a handful of sellers that achieve scale, utilization, and distribution.
We see three forces accelerating SaSo despite near-term cost gravity. First, algorithmic and systems efficiency will complement brute-force scaling – better data selection, sparsity, compilation, and workload shaping can cut compute costs materially. Second, distributed AI will split work sensibly: pre- and post-processing at the edge (including on devices) with factory inference and training behind APIs; storage tiers (including tape) and robotics will lower the cost of operating massive campuses. Third, the factories with the deepest ecosystems will ship the systems of intelligence or SoI agentic control planes, software development kits and adapters that enterprises adopt “as-is,” rather than building bespoke stacks. In our view, this means most organizations will prioritize owning and governing their data while sourcing intelligence from a few high-volume factories that improve fastest.
Bottom line: The AI factory buildout is real, front-loaded, and subject to a decade-long J-curve. Power, talent and data quality/governance pace the crossover point. Revenue capture accrues to operators that 1) Drive utilization, 2) Win the networking and systems efficiency game, 3) Support the delivery of trustworthy agentic platforms as services, 4) mobilize developer ecosystems, and 5) Relentlessly work the supply chain.
Buyers of AI will see software-like marginal economics. That sets up a a winner-takes-most market. Today, the momentum and evidence place OpenAI and Nvidia Corp. in the lead, with hyperscalers and select partners close behind, fed by a supply chain ecosystem that is mobilizing for massive returns in the 2030s.
Disclaimer: All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by News Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.
Image: theCUBE Research
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
- 15M+ viewers of theCUBE videos, powering conversations across AI, cloud, cybersecurity and more
- 11.4k+ theCUBE alumni — Connect with more than 11,400 tech and business leaders shaping the future through a unique trusted-based network.
About News Media
Founded by tech visionaries John Furrier and Dave Vellante, News Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.

 Review: Subtle Enhancements, Steep Price")
 | HackerNoon")


{kind=link}