Much to the detriment of my peace of mind, I spend a non-trivial amount of time watching YouTube clips of right-leaning pundits. An opinion I see more and more of is that our country will be better off if we either go back to or adopt Judeo-Christian values and traditions. The insistence on using the term “Judeo-Christian” as opposed to just “Christian”, which would exclude Judaism, or “Abrahamic”, which would include Islam, is something I would like to explore at some point. This opinion manifests in different forms, such as mentioning that many of the founding fathers were Christian or that the ten commandments is the foundation of a moral society and therefore the foundation of a just government.
There are some that claim the US Constitution is a product of a Judeo-Christian culture, and some go further by claiming that the concept of democracy itself reached its mature state because of Christianity. One prevalent proponent of this is Jordan Peterson, as evidenced from 15:05 to 17:05 in this YouTube video.
If one brings up that many of the ideas in the constitution were inspired by writings produced during the enlightenment era, a proponent of a strong Christian influence might reply by saying these intellectuals arrived at these ideas because of their understanding of Christian theology. So it seems there are claims that Christianity had either a direct or transitive influence on the creation of the US Constitution. Similar opinions are expressed about the necessity of Christianity for the development of science or understanding morality, but this topic will be saved for another time. There is often no evidence to support the idea that the dogmas of Christianity led to the ideas of personal liberty and democracy. Rick Pidcock provides an excellent breakdown of these views [2]. I will do my best to avoid rehashing Pidcock’s insights, but I will offer my opinions when it is appropriate.
Here I am tackling the more straightforward problem of objectively comparing the ethics in the US constitution to those found in the old testament of the Holy Bible [4, 5-6]. The focus will be on what is known as the 613 commandments which make up a large part of the Mosaic law. I will be using these terms interchangeably and I mean no offense if this isn’t precise.
From my understanding, the Mosaic law comes from the first five books of the old testament. The analysis also includes 100 commandments from the Quran, the morals delineated in Jesus’s sermon on the mount, the morals delineated in Mohammend’s last sermon (also known as the farewell sermon), and laws and statements in the Hammurabi code [7, 8-9, 10, 11]. In the context of this analysis, an ethic can refer to a commandment, a law, or a personal moral aspiration.
I don’t see how anyone who is being intellectually honest can examine the Mosaic law and the US constitution and conclude these values intersect in a meaningful way. However, there are right-wing influencers who espouse Christian morality and celebrate the brilliance of the US constitution, so perhaps it is indeed necessary to show just how different these ethics are.
Note: As you may have guessed, I lean left politically and am an atheist. In regard to my views on metaphysics, it may be more appropriate to describe myself as a nontheist and a soft antitheist. I don’t want to debate the semantics too much, but I do want to be clear on my position. By “nontheist”, I mean I don’t subscribe to any of the theisms on offer, or at least the theisms I am aware of. I don’t deny the possibility that those who described revelations in scripture got something right about the spiritual aspects of existence. I’m a “soft antitheist” in the sense that I think religion holds us back from our true moral potential and understanding of the universe, but I don’t hold the view that theism only leads to harm. The only reason I bring this up about myself is to disclose my biases. However, as you will soon see, the objective approach I take in the analyses renders this bias irrelevant.
The Results section gives a high-level explanation of the data analysis and covers the main findings. The Discussion section goes over the implications of the results. For those who are interested, a more granular explanation of the data analysis and links to the open-source code can be found under the Approach section. The Supplemental results section covers how the results were validated. If you would like to dive more into the math behind the results, I encourage you to refer to the relevant Scikit-learn web pages or find relevant videos on the StatQuest YouTube channel [12, 13]. The Future Work section goes over my ideas for follow-up analyses.
Approach
Code
https://github.com/jdh33/secular-or-religious
Packages
|
Package |
Version |
Use |
|---|---|---|
|
Python |
3.12.9 |
General programing |
|
BeautifulSoup4 |
4.12.3 |
Website/HTML parsing |
|
Pandas |
2.2.3 |
Dataframe/table/matrix analysis |
|
Google-GenAI |
1.7.0 |
Text embedding |
|
Scikit-learn |
1.6.1 |
Clustering and dimensionality reduction |
|
Seaborn |
0.13.2 |
Visualization |
For a full list of packages, see: https://github.com/jdh33/secular-or-religious/blob/main/data/output/constitution_analyses/package_versions_13062025.txt
Data processing
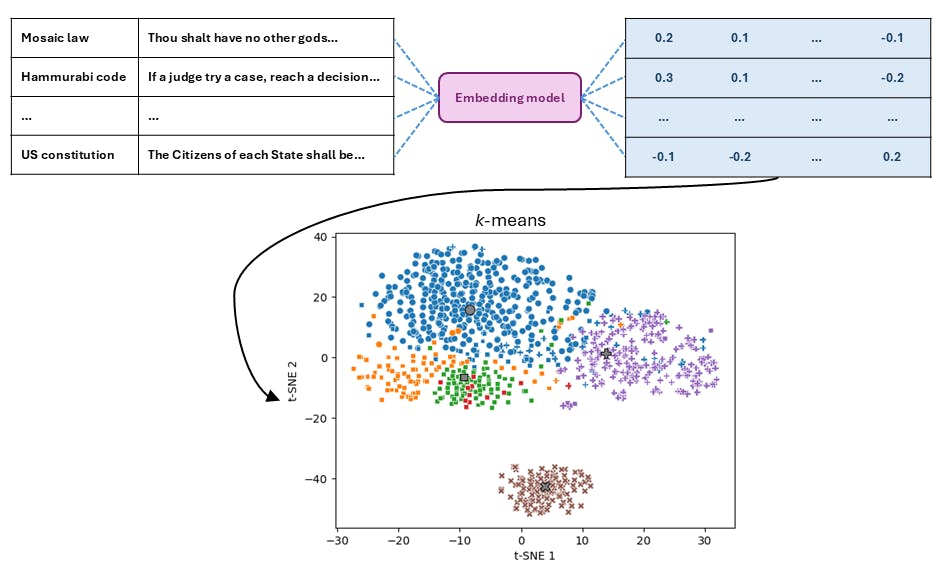
Several sources were used to build the table of ethics [4-11]. The data were extracted from these sources using a combination of URL requests, HTML parsing, and plain text parsing. For the 613 biblical commandments that represent the Mosaic law, some of the ethics spanned multiple verses. In these cases, the verses were concatenated to form a singular ethic. Other verses that are part of the 613 biblical commandments contained multiple commandments. There was not consistent punctuation that split up the commandments in these cases, so the verse was treated as a singular ethic. Because of this, the 613 commandments were condensed to 469 ethics. For the Sermon on the mount and the Quran, each referenced verse was processed as one ethic. For the Last sermon, each paragraph that was a quotation of Muhammad was processed as one ethic. For the Hammurabi code, each enumerated code was processed as one ethic and each paragraph of the epilogue was processed as one ethic. Some of the codes contained ellipses to indicate missing text and explanatory text within parentheses or brackets. These elements were retained when extracting the ethics. Some of the original codes are completely missing due to being removed from the stele. The US Constitution is composed of the Preamble, seven articles, and 27 amendments. The first 10 amendments make up the Bill of Rights. For simplicity, each paragraph was processed as one ethic, regardless of whether the paragraphs were in distinct numbered sections, for all of these components. As a result, an article and an amendment can span multiple ethics. All of the amendments that compose the Bill of Rights are a single paragraph, so the Bill of Rights are not affected by this. A total of 1,073 ethics were extracted from all sources.
Text embedding
The Gemini model text-embedding-004 was used to embed the ethics. This model has an input token limit of 2,048. About 60 to 80 words can be represented per 100 tokens. This puts the low-end of the maximum word count per ethic at 1,228. Every ethic was less than or equal to 1,228 words, therefore all of the ethics were embedded. The text-embedding-004 model produces a numerical representation of the text as output. Specifically, the output of each embedding is a 768 dimension array of floating point numbers called a vector. The “clustering” task type was specified when calling the embedding model, which produces embeddings that are optimized for clustering based on text similarity.
Clustering and visualization
The 1,073 by 768 embedding table was clustered using k-means. Several values of k (the number of clusters) were tested and compared. The elbow method and the V-measure metric were used to determine 4 as the optimal number of clusters. The k-means model returns the assigned clusters and the cluster center coordinates. t-distributed stochastic neighbor embedding (t-SNE) was used to map the 1,073 embedded ethics and the cluster center coordinates from 768 dimensions to 2 dimensions to visualize the results.
Important notes: 1) The t-SNE mapping of data with high dimensionality to a lower dimension space is relative to the data it receives as input. It is essential that the t-SNE model is fit with the ethics from all the data sources at the same time for proper visualization. If more data is added to this analysis, the newly embedded ethics should be appended to the table of currently embedded ethics, and then another t-SNE model must be fit with all of the embedded ethics at once. 2) Constant random state values were passed to both the Scikit-learnk-means and t-SNE models. Passing integer values makes the results reproducible.
Results
The ethics were gathered from the various sources and organized into a single table of 1,073 ethics, which can be viewed here <
Next, the resulting 1,073 by 768 table of text embeddings was modeled using the k-means method. It is necessary to test different numbers of clusters, or k, as the optimal number of clusters for a dataset is not known beforehand. The validation process, discussed in the Supplemental results section, indicated 4 to be the optimal number of clusters. To help visualize the results, t-SNE was used to map the text embeddings and cluster centers to a 2 dimensional space. t-SNE excels at preserving local structure and clusters while reducing dimensionality. However, the global distances can be distorted, so the distance between data points or cluster centers in the 2 dimensional plot should be taken with a grain of salt. For those that are unfamiliar with dimensionality reduction, a good analogy is shining a light on a 3-dimensional object and producing a 2-dimensional shadow. It is often possible to project high dimensional data onto a lower dimensional space without losing too much important information.
Figure 1


The assigned clusters are indicated by the marker shape and the cluster centers are larger and grey. Even with just this visualization, we can see how distinct the ethics of the US constitution are compared to all the others. If we look closely, we can see that some data points appear to be misplaced. For example, some data points belonging to cluster 3, indicated by “+”, look far away from other data points belonging to that cluster. This is an artifact of mapping the 768 dimension vectors onto a 2 dimension space. If we could somehow visualize 768 dimensions, these example data points would be closer to data points assigned to the same cluster.
Figure 2


Cluster 1 is purely made up of ethics found in the US constitution and all of the ethics of the US constitution are in cluster 1. This symmetry is one indication that the ethics of the US constitution are much different than the ethics from other sources. It is important to note that clustering results could change if additional ethics were included, such as additional verses from the Holy Bible or the Quran.
Table 1
|
Distances between cluster centers |
||||
|---|---|---|---|---|
|
Cluster |
0 |
1 |
2 |
3 |
|
0 |
0.000 |
0.613 |
0.361 |
0.399 |
|
1 |
0.613 |
0.000 |
0.605 |
0.610 |
|
2 |
0.361 |
0.605 |
0.000 |
0.434 |
|
3 |
0.399 |
0.610 |
0.434 |
0.000 |
The distance between 2 points in 768 dimensional space can be calculated just like the distance between 2 points in 2- or 3-dimensional space. The important takeaway from this table is that the center of cluster 1 is further away than any other cluster center when comparing the cluster center distances.
Discussion
Figures 1 and 2 and table 1 all tell the same story. The ethics found in the US constitution are much different than those found in the Mosaic law. We also see that they are much different than the ethics found in the selected verses of the Quran, Jesus’ sermon on the mount, the last sermon of Muhammad, and the Hammurabi code. All of the ethics from the US constitution belong to cluster 1, and no other ethic from other sources is even close to cluster 1. According to the results of this analysis, there is no direct connection between the Mosaic law and the US constitution.
Like I stated in the introduction and motivation section, my goal was to make this analysis as objective as possible. I did not summarize or truncate any of the referenced verses or laws. The ethics were processed as is; they were not subject to my interpretation. Someone may disagree with my decision to treat specific verses as 1 ethic instead of multiple ethics, or think that articles of the constitution should be treated as 1 ethic regardless of if an article spans more than 1 section and/or paragraph. I can definitely modify the code to extract the ethics from the source texts if anyone raises concerns such as this. I am not claiming that this is a comprehensive analysis, as there are also other ways to calculate text similarity. I am working on part 2 of this project which will include additional ways to analyze similarity.
Future work
If you examined some of the verses from the Bible and Quran websites I referenced, you may have noticed that some of the egregious verses are missing. These range from controversial to outright horrific. The website I referenced for the 613 commandments includes Exodus 21:20, which states the punishment if someone kills their slave, but excludes Exodus 21:21, which many agree is stating that a slave is their owner’s personal property. I have also read that the version of Muhammad’s last sermon I referenced is fraudulent, and the authentic version contains a passage indicating when it is appropriate for a husband to beat their wives and another passage that likens women to domestic animals. I opted not to add these to the analysis for two reasons. First, I wanted to bias the verses from these religious texts towards the positive to combat any unconscious bias I may have. Second, I think most proponents of theology would say something to the effect of “God was meeting his people where they were at” and dismiss such verses as not applicable to today’s society. Although, there is a clip of Charlie Kirk responding to someone talking about how Jesus taught us to love our neighbors regardless of sexual orientation. He smugly points out a verse that commands us to stone a man to death if they have sex with another man [14]. As I don’t want to give someone espousing this view any more attention, the reference is a link to a response video. With that said, I plan on compiling and extracting these types of verses from the relevant religious texts for analyses down the road.
I plan on including verses like those alluded to in the preceding paragraph with the already compiled table of 1,073 ethics in future analyses. Future analyses will include calculating cosine similarities and developing ethics classification models using text embeddings.
It is possible that some specific words drive some of the differences we see in the clustering results. For example, verses from the Bible may use the term Yahweh and verses from the Quran may use the term Allah. Both of these are specific words for God. Of course, the US constitution brings up the United States and the Bible makes references to Israel. I am working on a way to standardize the extracted ethics and then performing the same analysis. Some examples: Yahweh, Father, and Allah could be replaced with a generic term for a god, and the United States and Israel could be replaced with a generic term for nation. This would be tricker for something like the Hammurabi code which refers to multiple gods.
Eventually, I plan on taking on the idea that Christian values, or Judeo-Christian values, are responsible for the prominent ideas of the enlightenment era and therefore the ideas in the US constitution. You can listen to Ben Shapiro and Jordan Peterson discuss this during an episode of “The Rubin Report” [15]. I anticipate this analysis will be more subjective because it will involve interpretations of the writings of the enlightenment figures and the forefathers of the United States. However, I will keep it as objective as I can. I may investigate the use of the relatively new Large Context Models to generate these summarizes, as they were developed to handle concepts better than Large Language models.
References
https://www.youtube.com/watch?v=aALsFhZKg-Q https://baptistnews.com/article/no-the-u-s-constitution-is-not-based-on-the-book-of-deuteronomy/ https://www.pewresearch.org/religion/2022/10/27/views-of-the-u-s-as-a-christian-nation-and-opinions-about-christian-nationalism/ https://constitutioncenter.org/the-constitution/full-text https://www.gotquestions.org/613-commandments.html https://www.bibleref.com/ https://www.biblegateway.com/passage/?search=Matthew 5-7&version=NIV https://messageinternational.org/100-commandments-and-doctrines-from-the-quran/ https://www.clearquran.com/ https://www.iium.edu.my/deed/articles/thelastsermon.html https://avalon.law.yale.edu/ancient/hamframe.asp https://scikit-learn.org/stable/about.html#citing-scikit-learn https://www.youtube.com/@statquest https://www.youtube.com/watch?v=QWKF5EU1Cig https://www.youtube.com/watch?v=1opHWsHr798
Supplemental results
Validating the number of clusters
The Scikit-learn k-means model accepts the number of clusters, k, as a parameter. I tested 2 to 7 clusters and chose the optimal number based on the elbow method and the V-measure metric.
Supplemental figure 1


The elbow method visualizes the inertia at a given k. Inertia, one of the more straightforward metrics, is the sum of squared distances between each data point and the centroid of the cluster that data point is assigned to. Smaller, relative inertia value means the data points are grouped around their respective centroids well. It is important to note that adding more clusters leads to reduced inertia, but the clusters become useless if there are too many, as the goal is to group similar data points together. With the elbow method, we want to visualize at what k the decrease in inertia slows down a considerable amount, i.e. find the “elbow”. For this dataset, k=4 is optimal. The elbow method is subjective, so it is imperative to utilize other metrics as well.
Supplemental table 1
|
Number of clusters |
V measures |
|---|---|
|
2 |
0.469 |
|
3 |
0.632 |
|
4 |
0.732 |
|
5 |
0.623 |
|
6 |
0.637 |
|
7 |
0.606 |
The V-measure metric also identified k=4 as optimal. I encourage the reader to refer to the Scikit-learn metrics page <





{kind=link}