
When I started learning AI and diving into frameworks like LangGraph, n8n, and the OpenAI APIs, I found plenty of great tutorials. They taught me how to build a simple chatbot, how to make my first LLM call, how to chain a few prompts together. Useful stuff for getting started.
Great for for learning. Less great for shipping.
After the first couple of weeks, I wanted to build an actual production-ready application which goes beyond standard POCs. Something which uses AI but involving dozens of routes, multiple features and services, database operations, caching layers. But those beginner tutorials weren’t enough. Where do the embeddings live? How do I structure my agent workflows? Should my API routes call AI directly, or is there supposed to be a layer in between?.
The documentation showed me how to use the framework abstractions and APIs. It didn’t show me how to organize them.
If you’re like me, coming from a JavaScript/TypeScript background, you know the language gives you a lot of freedom – no enforced folder structure, no prescribed architecture. You can organize your code however you want. But that freedom comes at a price.
Without clear patterns to guide where things should go, you might end up with working code in all the wrong places. Calls to OpenAI API scattered everywhere, business logic tangled with your routes, and you just know this is going to be painful to maintain later.
Here’s the thing: software architecture trends come and go. In 2015, everyone said microservices were the future. In 2018, serverless. In 2021, JAMstack. In 2023, every
one quietly went back to monoliths.
But you know what remained constant through all these trends? The fundamental principle of separating concerns. These same software development principles apply to AI and agentic AI applications. Whether you’re building traditional web apps or AI-powered systems, the need for clear architecture remains constant.
What Makes AI projects maintainable
Let’s establish what properties a good AI project should have:
Clear Ownership Boundaries
Clear ownership boundaries define which part of your system is responsible for what. Good boundary means when something breaks or needs extension, you immediately know which component to check.
Each distinct concern in your application should be handled by a single, well-defined module or component. This way, when something goes wrong or when you need to add a feature, you’ll immediately know which part of your codebase is responsible.
Clear boundaries mean each concern lives in an identifiable place. When something goes wrong, you immediately know which module to check. When you need to add a feature, you know which component to extend.
Reusability across entry points
Reusability means writing logic once and calling it from anywhere.
Your core business logic should work the same way regardless of how it’s triggered. Whether called from a web API, an AI agent, a scheduled job, a command-line tool, a message queue, or a test suite, the same functionality should be available without rewriting it.
Why it matters: Today it’s a chat API. Tomorrow you may want a Slack bot. Next week, batch processing. And who knows? Maybe you’ll discover that your users actually prefer the regular search over your fancy AI chatbot anyway. If your AI code is tied to say, your controllers, you might have to rewrite it each time.
Testability
Testability is the degree to which a piece of software can be tested easily and effectively. It describes how simple it is to check that the software works as intended. High testability means tests can be written quickly, run reliably, and give clear results, while low testability leads to tests that are difficult, slow, or unclear.
AI applications have many moving parts. Vector search slow? Cache not hitting? Agent hallucinating? Embedding generation failing? When you’re debugging, you shouldn’t have to hunt through your entire codebase to find the problem.
Provider Independence
Swapping from GPT-4 to Claude to Gemini shouldn’t require changing business logic.
Why it matters: AI models evolve weekly. Today’s best model is next month’s deprecated one. Providers change pricing. Features get sunset. Your architecture should make provider switching very straightforward.
If you’re a software engineer who has started building AI applications and you want to move beyond simple code snippets and demos, let me show you what worked for me. In the following sections, I’ll walk you through patterns I extracted from a real project – patterns that apply whether you’re building e-commerce, SaaS tools, content platforms, or any AI-powered application.
For illustration, I’ll use an AI-powered restaurant discovery application – think Yelp or Zomato with a conversational chat feature. Instead of just filtering by “Italian cuisine”, users can ask “I need a romantic spot with live music for an anniversary dinner”.
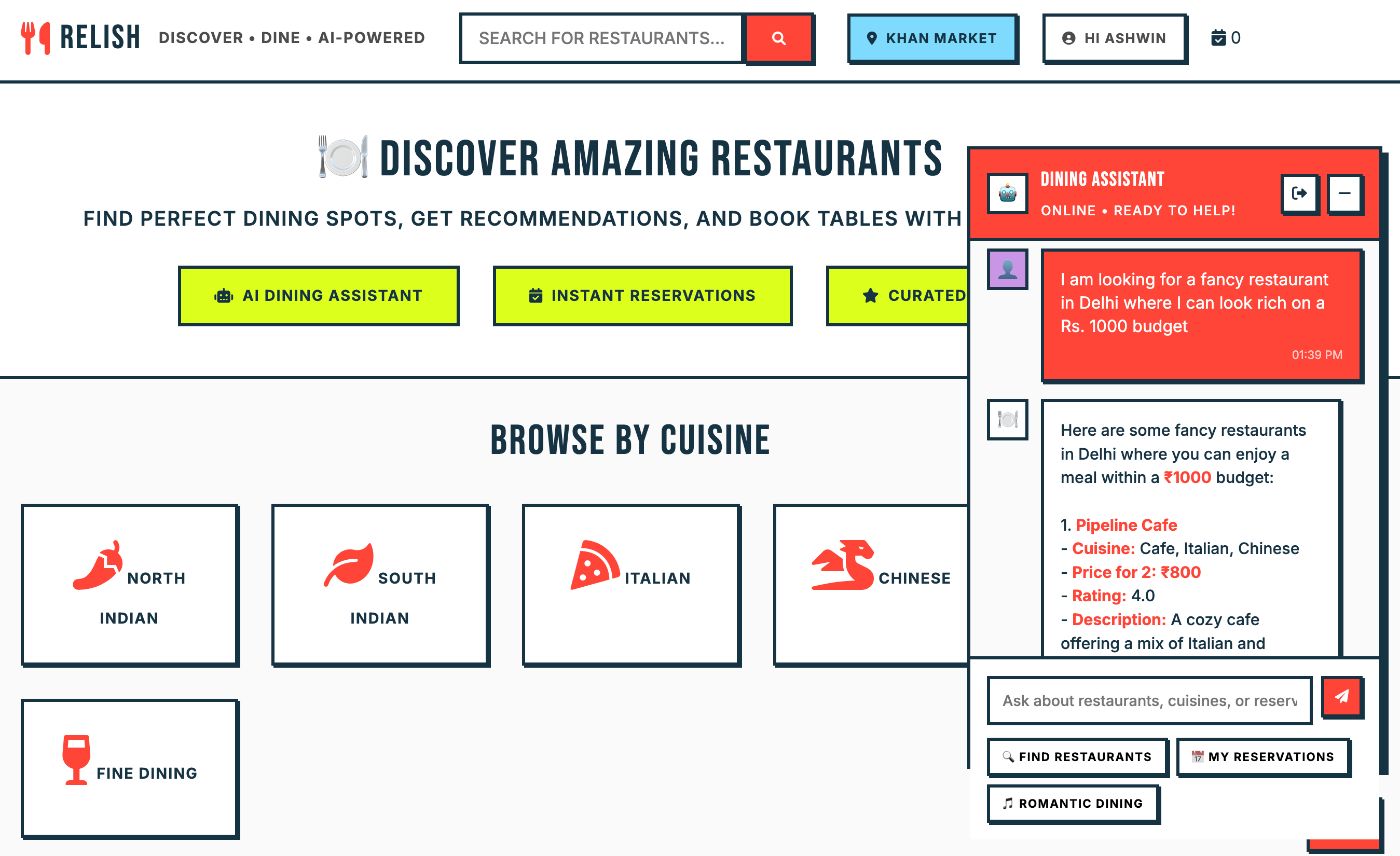
Chat-based conversational restaurant discovery and reservation app. View the implementation on GitHub
What this really comes down to:
How do you add these AI capabilities without major refactoring of your existing system? And without over-engineering a solution that’s way more complex than it needs to be?
Throughout the code examples, I will use Node.js / JavaScript as its syntax is widely familiar to anyone building apps for the web and generalizes well to other languages. But these architectural patterns apply equally to Python, Java, or any other language you’re working with.
Architectural patterns for AI apps
After some research and quite a few experiments and trying out different approaches, I settled on few patterns that actually work. Before we dive in, know that these aren’t necessarily AI-specific. They’re the same principles that make any large application maintainable. But when you build with these patterns from the start, adding and testing AI features later becomes straightforward.
Let’s look at what they look like:
Pattern 1: Structure by business components or modules
Rather than organizing code by technical function (all controllers together, all models together), organize by business components. Each module represents a bounded context with its own API, logic, and data access.
Why This Matters for AI:
AI applications typically have multiple distinct domains:
- Conversation management (chat history, session state)
- AI workflow orchestration (agents, tools, prompts)
- Business entities (restaurants, users, reservations)
- Data processing (embeddings, vector search)
Mixing these concerns creates cognitive overload and makes it hard to reason about the system and maintain it.
// ❌ Bad: Organized by technical layers
src/
├── controllers/
│ ├── chatController.ts
│ ├── restaurantController.ts
│ └── reservationController.ts
├── services/
│ ├── chatService.ts
│ ├── restaurantService.ts
│ └── reservationService.ts
└── repositories/
├── chatRepository.ts
├── restaurantRepository.ts
└── reservationRepository.ts
Problem: To understand the “chat” feature, you jump between three different directories. Adding a new feature touches files across the entire codebase.
Colocation: For a feature, put related code close together. Code that changes for the same feature should be neighbors and a short navigation away.
This is also popularly known as “Domain-driven design”
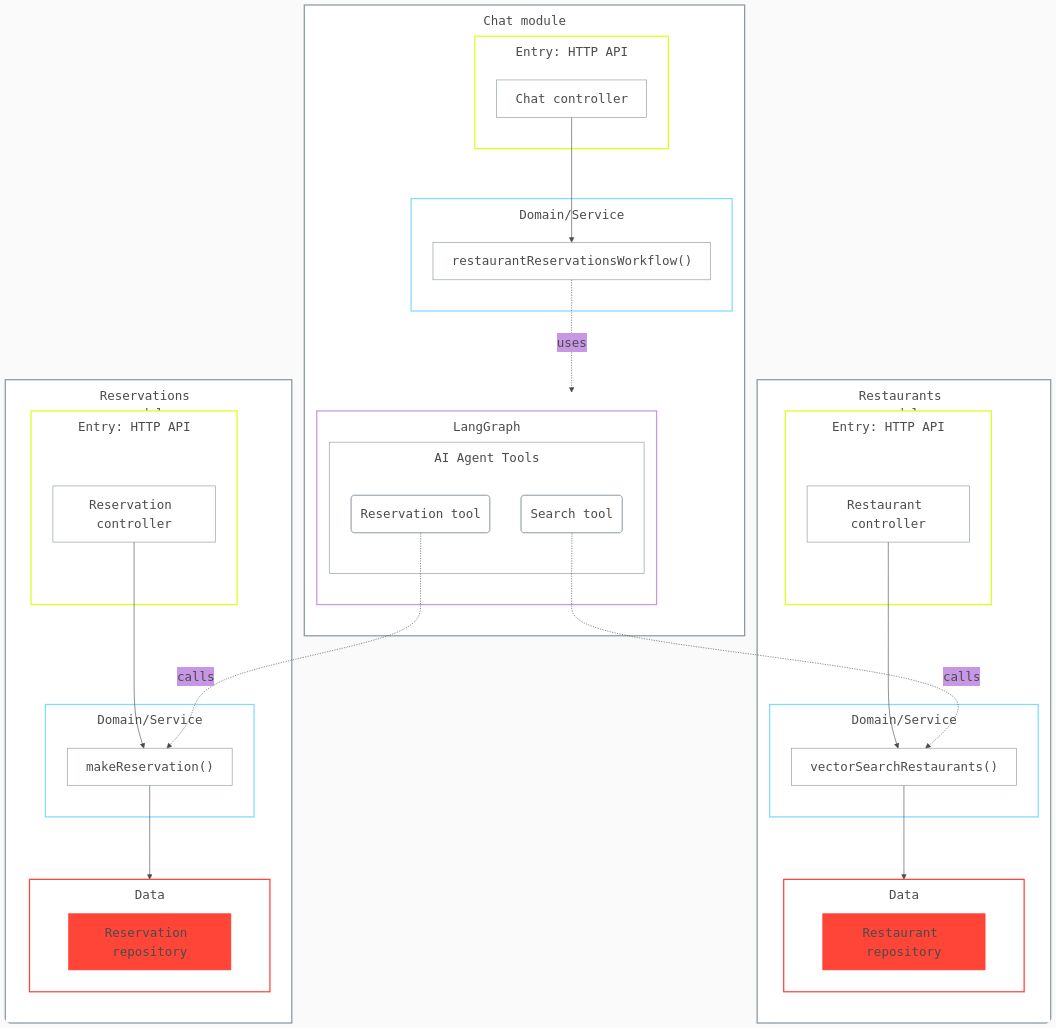
When you add a new feature to the chat system, you typically need to modify the API endpoint, update the business logic, and adjust the data access layer. With domain-driven design, all these files are in the same chat/ directory-you never leave that folder. Without it, you’re jumping between controllers/, services/, and repositories/ directories, trying to remember which pieces connect.

Each domain is self-contained with its own API, Domain, and Data layers
Benefit: Everything related to “chat” lives in one place. Each business component is self-contained.
// ✅ Good: Organized by business components
modules/
├── chat/
│ ├── api/chatController.ts
│ ├── service/chatService.ts
│ └── data/chatRepository.ts
├── restaurants/
│ ├── api/restaurantController.ts
│ ├── service/restaurantService.ts
│ └── data/restaurantRepository.ts
└── reservations/
├── api/reservationController.ts
├── service/reservationService.ts
└── data/reservationRepository.ts
When you need to modify how restaurants are searched, you go directly to modules/restaurants/. When you need to add a new AI tool, it goes in modules/ai/agentic/tools. There’s no guessing, no hunting through dozens of files.
This also means you could extract any of these services into a separate microservice later without major refactoring – the boundaries are already defined.
Pattern 2: Layer your feature modules with 3-tier architecture
While Pattern 1 is about grouping by business domain, Pattern 2 applies the same concept of colocation within each domain. The API, domain, and data layers for a feature stay together in the same feature module folder, not scattered across the codebase.

Within each module, maintain clear separation between three concerns:
-
Entry Points (API routes, message queue consumers, scheduled jobs)
-
Domain Logic (business rules, workflows, services)
-
Data Access (database queries, external API calls) – this is also called repository-pattern.
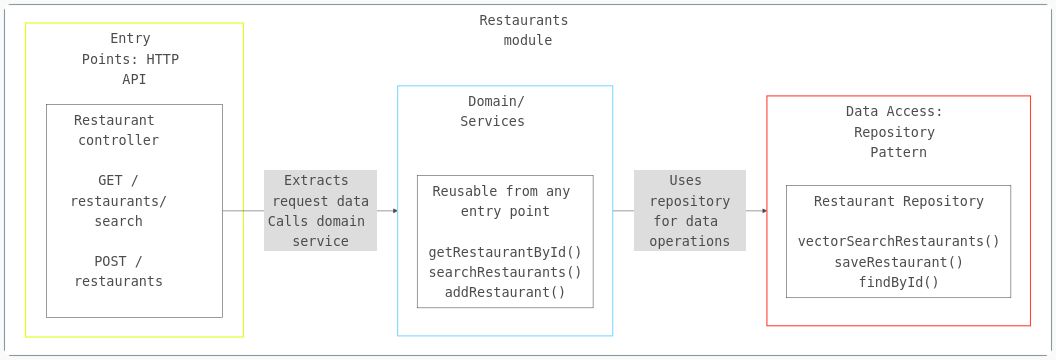
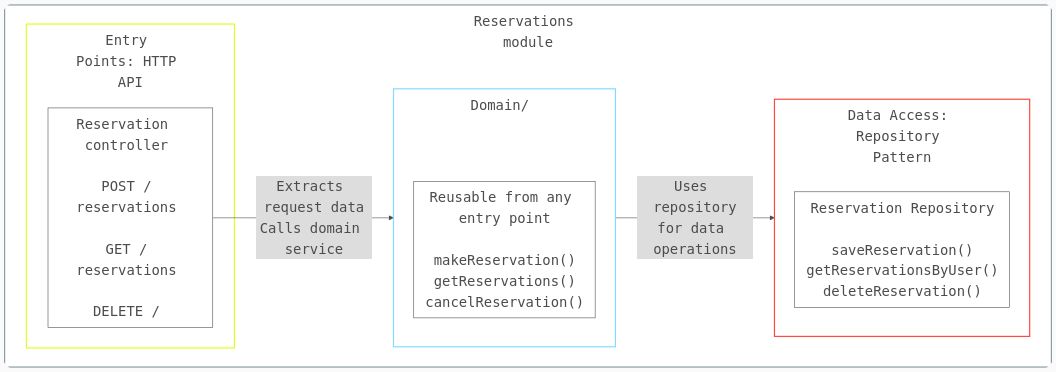
The Critical Rule:
Never pass framework-specific objects (Express Request/Response, HTTP headers, etc.) into your domain layer. Domain logic should be pure and reusable across different entry points.
// ❌ Don't do this: Domain logic coupled to Express
import { Request, Response } from 'express';
export async function handleChatMessage(req: Request, res: Response) {
const sessionId = req.cookies.sessionId;
const message = req.body.message;
// AI workflow logic mixed with HTTP handling
const result = await aiAgent.run(message);
res.json({ response: result });
}
The problem with the above code is that this function would only work with Express. But AI workflows often need to be triggered from multiple sources:
- HTTP API requests (user chat)
- Scheduled jobs (batch processing)
- Message queues (async workflows)
- Tests (validation)
If your AI logic is tightly coupled to your HTTP layer, you can’t reuse it elsewhere, and you won’t be able to call it from a scheduled job, test, or CLI tool.
Your AI workflow orchestration should be completely separate from the HTTP layer. Here’s an example:
// ✅ Good: Clean separation
import { Request, Response } from 'express';
import { getResponseFromAgent } from '@modules/chat';
export async function handleChatMessage(req: Request, res: Response) {
const sessionId = req.cookies.sessionId as string;
const message = req.body.message as string;
const result = await getResponseFromAgent(message, sessionId);
res.json({ response: result });
}
// ✅ business logic - no HTTP dependencies
export async function getResponseFromAgent(message: string, sessionId: string) {
const result = await aiAgent.run(message, sessionId);
return {
response: result.text,
toolsUsed: result.tools
};
}
Now, getResponseFromAgent() can be called from anywhere – HTTP endpoints, scheduled jobs, tests, or CLI scripts.
The API layer now focuses only on handling HTTP concerns – receiving the request, extracting the session ID and message, and returning a response – while delegating all business logic to the domain layer.
Similarly, use the Repository pattern to prevent database details from leaking into business logic:
// ❌ Don't put this in your services / domain logic
async function searchRestaurants(query: string) {
const redis = await redisClient.connect();
const results = await redis.ft.search('idx:restaurants', query);
// transform query response...
}
// ✅ Good
async function searchRestaurants(query: string) {
const queryEmbeddings = await generateEmbeddings([query]);
return restaurantRepository.vectorSearchRestaurants(queryEmbeddings);
}
// ✅ restaurant-repository.ts
export class RestaurantRepository {
async vectorSearchRestaurants(searchVector: number[]) {
// Redis-specific implementation hidden
const results = await redis.ft.search(/* ... */);
return this.transformToRestaurants(results);
}
}
The domain layer remains pure and independent of HTTP and database implementation, returning structured results. Now if you need to switch databases based on performance or cost, your domain services don’t change – only the repository implementation does.
Pattern 3: Tools and prompts should call domain logic, not implement it
When you’re building AI agents with LangChain, LangGraph, or similar frameworks, you define “tools” - functions the AI can call to perform actions. Need to search products? Create a tool for that. Add items to cart? Tool. Get user preferences? Tool.
There are two common anti-patterns where business logic ends up in the wrong place:
Anti-pattern 1: Business logic in prompts
const prompt = `
You are a restaurant discovery assistant. Follow these rules:
1. Only show budget-friendly restaurants (under ₹500 per person) for budget users
2. Apply member discounts on reservations for gold members
3. Suggest fine dining establishments to premium members
...
`
Problem: Your business rules now live in natural language. They’re non-deterministic, untestable, and invisible to code review.
Anti-pattern 2: Business logic in tools
It feels natural to write business logic directly in tool functions. During a conversation in the chat interface, the user wants to search products, so you write the search logic right there in the tool. You need database access, so you import the database client. You need to validate the search query, calculate relevance scores, apply business rules - all of it goes into the tool.
// ❌ Bad: Business logic inside AI tool
import { tool } from '@langchain/core/tools';
import { z } from 'zod';
import { createClient } from 'redis';
export const searchRestaurantsTool = tool(
async ({ query }) => {
// Database access directly in tool
const client = await createClient.connect();
const embedding = await openai.embeddings.create({ input: query });
const results = await redis.ft.search('idx:restaurants', ...);
// Business logic in tool
const filtered = results.filter(r => r.priceFor2 < 2000);
const sorted = filtered.sort((a, b) => b.rating - a.rating);
return sorted.slice(0, 5);
},
{
name: "search_restaurants",
description: "Search for restaurants",
schema: z.object({ query: z.string() })
}
);
The problem with the above code is that the core logic is locked in the AI tool. Few months later, you might realize you need that same search logic in a REST API endpoint, or in a scheduled job, or in a different agent. But it’s tightly coupled to the AI framework you used.
Tools should be thin wrappers that translate AI intent into domain service calls.
That’s it. The tool’s job is simple:
- Receive parameters from the AI
- Validate/transform them if needed
- Call the appropriate domain service
- Return the result in a format the AI understands
The actual business logic? That lives in domain services, completely independent of any AI framework.
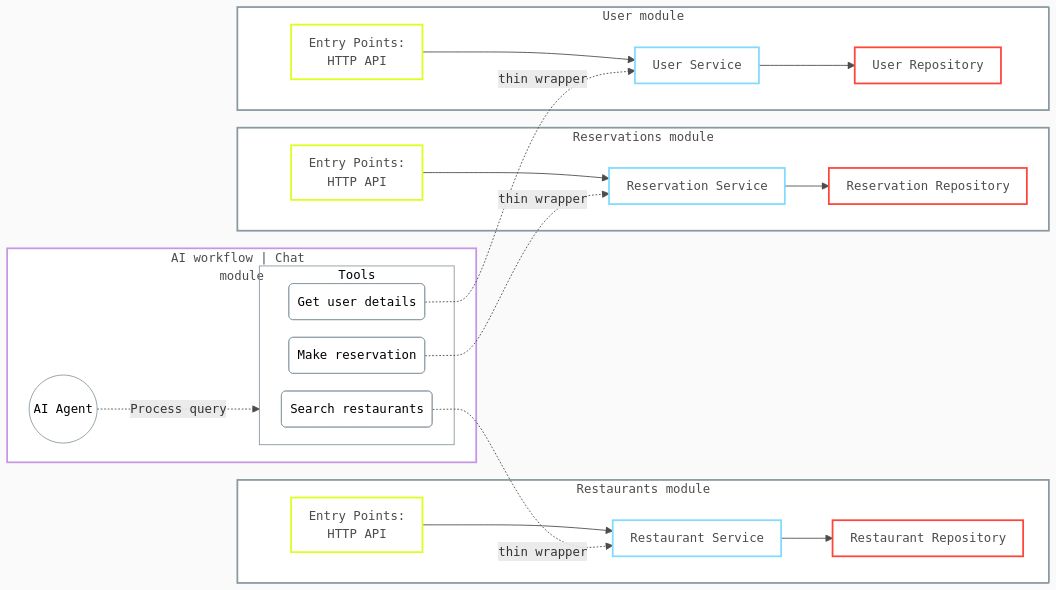
Here’s how you can write it:
// ✅ Good: logic lives separately
export async function searchRestaurants(query, limit) {
const queryEmbeddings = await generateEmbeddings([query]);
const searchVector = queryEmbeddings[0];
const restaurants = await restaurantRepository.vectorSearchRestaurants(
searchVector,
limit
);
return restaurants.sort((a, b) => b.rating - a.rating);
}
// ✅ Tool simply calls domain service
import { searchRestaurants } from '@modules/restaurants';
import { tool } from '@langchain/core/tools';
import { z } from 'zod';
export const searchRestaurantsTool = tool(
async ({ query }) => {
// Just a thin wrapper
const restaurants = await searchRestaurants({ query, limit: 5 });
return restaurants;
},
{
name: "search_restaurants",
description: "Search for restaurants",
schema: z.object({ query: z.string() })
}
);
Benefit: Your business logic is now independent, just plain functions that take input and return output – you can reuse it everywhere. searchRestaurants() can now be called from AI tools, HTTP endpoints, CLI scripts, or tests.
Ask yourself: “If I needed this logic in a REST API endpoint tomorrow, would I have to copy-paste code or could I just import a function?”
If the answer is copy-paste, your logic is in the wrong place.
When your tools are thin adapters to domain services, you can test the core behavior locally without calling the LLM at all. This makes tests fast, reliable, and deterministic. Your code becomes:
- Reusable across HTTP, CLI, scheduled jobs, tests
- Testable without AI framework mocking
- Maintainable because business logic lives in one place
- Flexible because you can change AI frameworks without rewriting business logic
Pattern 4: Dependency Inversion
High-level policy (your business logic) should not depend on low-level details (specific frameworks, providers, or databases). This follows the Dependency Inversion Principle from Robert C. Martin’s SOLID principles: your code should depend on abstractions, not on concrete implementations.
In simpler terms: when you use external services-whether it’s OpenAI, AWS Bedrock, LangChain, or Redis-hide them behind interfaces that match your domain’s needs, not theirs.
Why this matters for AI:
AI applications introduce volatile dependencies that change frequently:
- AI Providers switch constantly: Today’s OpenAI becomes tomorrow’s Anthropic or AWS Bedrock
- Models evolve rapidly: GPT-4 becomes GPT-4 Turbo becomes GPT-4o
- Frameworks shift: LangChain might become LangGraph, or you might switch to a different agentic framework entirely.
- Vector databases compete: Pinecone, Weaviate, Redis Vector Search – requirements change.
Without DIP, switching any of these requires changes across your entire codebase. With DIP, you change one file.
Real-world example: switching AI providers
Consider an embeddings service. Without DIP, you’d scatter OpenAI SDK calls throughout your codebase:
// ❌ Bad: Tightly coupled to OpenAI everywhere
import OpenAI from 'openai';
async function searchRestaurants(query: string) {
const openai = new OpenAI({ apiKey: process.env.OPENAI_KEY });
const embedding = await openai.embeddings.create({
model: "text-embedding-3-small",
input: query
});
// search logic using embedding...
}
Now imagine your company decides to switch to AWS Bedrock for cost savings. You’d need to find and modify every place that calls OpenAI’s embedding API.
With DIP, high level policy does not depend on low level details:
// ✅ Good: embeddings.ts
import OpenAI from 'openai';
export async function generateEmbeddings(texts: string[]) {
// Implementation hidden behind interface
}
async function searchRestaurants(query) {
// Generate embedding for the search query
const textEmbeddings = await generateEmbeddings([query]);
// Use repository for pure data operations
return restaurantRepository.vectorSearchRestaurants(textEmbeddings);
}
The implementation file changes based on your provider, but the interface stays the same:
import { BedrockEmbeddings } from '@langchain/aws';
export async function generateEmbeddings(texts: string[]) {
const embeddings = new BedrockEmbeddings({
model: process.env.model,
region: process.env.awsRegion
});
return await Promise.all(texts.map(text => embeddings.embedQuery(text)));
}
// openai-version/embeddings.ts
import OpenAI from 'openai';
export async function generateEmbeddings(texts: string[]) {
const openai = new OpenAI({ apiKey: CONFIG.openAiApiKey });
const response = await openai.embeddings.create({
model: "text-embedding-3-small",
input: texts
});
return response.data.map(item => item.embedding);
}
Your domain services import from the abstraction:
import { generateEmbeddings } from '@modules/ai/helpers';
export async function findRestaurantsBySemanticSearch(query: string) {
const queryEmbeddings = await generateEmbeddings([query]);
const searchVector = queryEmbeddings[0];
return await restaurantRepository.vectorSearchRestaurants(searchVector);
}
Switching providers now means changing one file, not hunting through your entire codebase. The LLM becomes just one dependency behind a clear interface, which we can replace with mocks or fixtures during testing.
Example: Abstracting agent frameworks
The same principle applies to agentic AI frameworks. Your business logic shouldn’t know whether you’re using LangGraph, CrewAI, or AutoGen.
Instead of spreading LangGraph-specific code everywhere, isolate your agentic AI workflow implementation in its own module:
// ✅ Good
import { HumanMessage } from '@langchain/core/messages';
import { restaurantReservationsWorkflow } from '@modules/ai/workflows';
export async function processUserQuery(query: string, sessionId: string) {
const result = await restaurantReservationsWorkflow.invoke({
messages: [new HumanMessage(query)],
sessionId
});
return {
response: result.result,
cacheStatus: result.cacheStatus,
toolsUsed: result.toolsUsed
};
}
With Dependency Inversion, you can experiment with different models without touching business logic and move between frameworks gradually as your needs evolve. It does introduce extra abstraction, which can sometimes feel like over-engineering, but it’s most valuable when dependencies are volatile, you’re evaluating multiple options, or vendor lock-in is a real risk.
Pattern 5: Use environment-aware, secure, and hierarchical config
AI applications have complex configuration needs:
- Multiple AI provider credentials (OpenAI, Anthropic, AWS), model identifiers and versions
- Rate limits and timeouts
- Feature flags for different AI capabilities
- Vector database connections
- Caching configuration
- Guardrail settings
So your configuration should be:
-
Environment-aware: Different values for dev/staging/production
-
Secure: Secrets never committed to version control
-
Validated: Fail fast on startup if config is invalid
-
Hierarchical: Organized for easy discovery
-
Type-safe (optional): Preferably with TypeScript or runtime validation
// ❌ Bad: Secrets hardcoded, scattered config const openai = new OpenAI({ apiKey: “sk-abc123…”, // Hardcoded secret! });
const bedrockModel = “anthropic.claude-v2”; // Magic string const redisHost = “localhost”; // Where’s production config?
The problem with the configuration above is that the configuration is scattered everywhere, and there’s no clean way to switch between models and environments.
// ✅ Good: Centralized, validated, environment-aware
// config.js
import dotenv from 'dotenv';
dotenv.config();
const requiredEnvVars = [
'OPENAI_API_KEY',
'AWS_ACCESS_KEY_ID',
'REDIS_HOST'
];
// Fail fast on startup if config is missing
requiredEnvVars.forEach(varName => {
if (!process.env[varName]) {
throw new Error(`Missing required environment variable: ${varName}`);
}
});
export default {
// AI Providers
openAi: {
apiKey: process.env.OPENAI_API_KEY,
model: process.env.OPENAI_MODEL || 'gpt-4o',
timeout: parseInt(process.env.OPENAI_TIMEOUT || '30000')
},
aws: {
region: process.env.AWS_REGION || 'us-east-1',
accessKeyId: process.env.AWS_ACCESS_KEY_ID,
secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY,
bedrockModelId: process.env.BEDROCK_MODEL_ID || 'anthropic.claude-v2'
},
// Databases
redis: {
host: process.env.REDIS_HOST,
port: parseInt(process.env.REDIS_PORT || '6379'),
password: process.env.REDIS_PASSWORD
}
};
# .env (never committed to git)
OPENAI_API_KEY=sk-abc123...
AWS_ACCESS_KEY_ID=AKIA...
REDIS_HOST=localhost
# .env.production (deployed separately)
OPENAI_API_KEY=sk-prod123...
AWS_ACCESS_KEY_ID=AKIA...
REDIS_HOST=redis.production.com
The benefit now is that all configuration lives in one place, it’s automatically validated on startup, switching between environments is easy, and secrets are no longer hardcoded in the codebase.
Pattern 6: Separate persistent data from agent memory
AI agents need to remember things during conversations, but not everything should live in your main database. User preferences? Database. The fact that someone just asked about “cozy sweaters” 30 seconds ago? Agent memory.
Why this matters for AI:
Mixing persistent and ephemeral data leads to bloated databases and slow AI responses. Different types of data have different storage requirements:
- Database: User profiles, restaurant catalog, reservation history – things that need to persist indefinitely
- Agent Memory: Conversation context, temporary preferences, session state – things that can expire
- Vector Store: Restaurant embeddings, semantic search indexes – specialized AI data structures
The Implementation:
services/
├── chat/
│ ├── services/
│ │ ├── workflow.js # LangGraph orchestration
│ │ └── memory.js # Session state, conversation context
│ └── data/
│ └── session-store.js # Fast, ephemeral storage
├── restaurants/
│ └── data/
│ ├── restaurant-repository.js # Persistent restaurant vector store
└── users/
└── data/
└── user-store.js # User profiles, preferences
Benefits:
- Faster AI responses (no database queries for temporary data)
- Cleaner main database (only persistent data)
- Automatic cleanup (session data expires)
- Better performance (right storage for each data type)
Getting the storage layer right is crucial for AI performance.
:::tip
Check out Redis for AI learning path for hands-on experience implementing these memory patterns and vector search capabilities.
:::
Your final project architecture could look something like this:
modules/
│
├── restaurants/ # Restaurants Domain
│ ├── api/ # HTTP layer
│ ├── service/ # Business logic
│ └── data/ # Data access
│
├── reservations/ # Reservations Domain
│ ├── api/
│ ├── service/
│ └── data/
│
├── chat/ # Conversation Domain
│ ├── api/
│ ├── service/
│ └── data/
├── ai/ # AI Domain
│ ├── agentic-restaurant-workflow/
│ │ ├── index.js # Workflow orchestration
│ │ ├── nodes.js # Agent definitions
│ │ ├── tools.js # AI tools
│ │ └── state.js # State management
│ └── helpers/
│ ├── embeddings.js # Embedding generation
│ └── caching.js # Cache logic
:::tip
[Check out the example implementation on Github!](https://Check out the example implementation on Github!)
:::
Next steps
Applied AI is quite fluid today – patterns, frameworks, and libraries are changing constantly. Teams are expected to deliver features fast. In this environment, your architecture needs flexibility. You can’t afford to lock your code into rigid structures that make change expensive.
I have been working with the patterns we discussed for quite some time and they really helped. Remember, these are not rigid rules. Learn what works for your project, and adapt. Think of your project not as a monolithic whole, but as independent, composable features with clear interfaces:
- If your code is scattered across technical layers, start grouping domains together grouping domains together.
- If your AI tools contain database queries, extract them into domain services.
- If you’re tightly coupled to OpenAI, add an abstraction layer.
If you’re working in the Node.js ecosystem, frameworks like NestJS can help you implement many of these patterns out of the box – modules, dependency injection, layered architecture. But here’s the thing: these patterns aren’t tied to any specific framework or even any specific language.
Choose the tools that work for your team, and these patterns will help you organize things in such a way that refactoring is something that is performed casually on a daily basis. It will also help pave the way to full-blown microservices in the future once your app grows. You’ll likely refactor anyway after you’ve built something real.


 Review: Same Look, Smarter Hookups")
 | HackerNoon")



{kind=link}