Authors:
(1) Yuwei Guo, The Chinese University of Hong Kong;
(2) Ceyuan Yang, Shanghai Artificial Intelligence Laboratory with Corresponding Author;
(3) Anyi Rao, Stanford University;
(4) Zhengyang Liang, Shanghai Artificial Intelligence Laboratory;
(5) Yaohui Wang, Shanghai Artificial Intelligence Laboratory;
(6) Yu Qiao, Shanghai Artificial Intelligence Laboratory;
(7) Maneesh Agrawala, Stanford University;
(8) Dahua Lin, Shanghai Artificial Intelligence Laboratory;
(9) Bo Dai, The Chinese University of Hong Kong and The Chinese University of Hong Kong.
Table of Links
Abstract and 1 Introduction
2 Work Related
3 Preliminary
- AnimateDiff
4.1 Alleviate Negative Effects from Training Data with Domain Adapter
4.2 Learn Motion Priors with Motion Module
4.3 Adapt to New Motion Patterns with MotionLora
4.4 AnimateDiff in Practice
5 Experiments and 5.1 Qualitative Results
5.2 Qualitative Comparison
5.3 Ablative Study
5.4 Controllable Generation
6 Conclusion
7 Ethics Statement
8 Reproducibility Statement, Acknowledgement and References
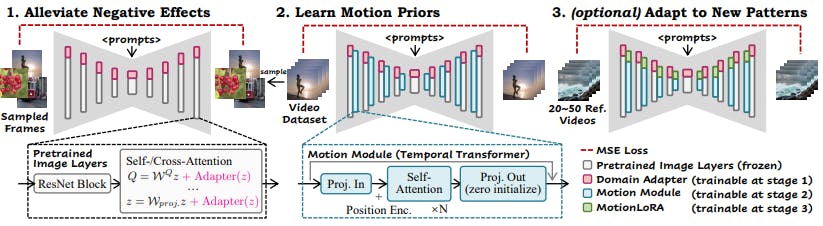
4.1 ALLEVIATE NEGATIVE EFFECTS FROM TRAINING DATA WITH DOMAIN ADAPTER
Due to the difficulty in collection, the visual quality of publicly available video training datasets is much lower than their image counterparts. For example, the contents of the video dataset WebVid (Bain et al., 2021) are mostly real-world recordings, whereas the image dataset LAIONAesthetic (Schuhmann et al., 2022) contains higher-quality contents, including artistic paintings and professional photography. Moreover, when treated individually as images, each video frame can contain motion blur, compression artifacts, and watermarks. Therefore, there is a non-negligible quality domain gap between the high-quality image dataset used to train the base T2I and the target video dataset we use for learning the motion priors. We argue that such a gap can limit the quality of the animation generation pipeline when trained directly on the raw video data.


To avoid learning this quality discrepancy as part of our motion module and preserve the knowledge of the base T2I, we propose to fit the domain information to a separate network, dubbed as domain adapter. We drop the domain adapter at inference time and show that this practice helps reduce the negative effects caused by the domain gap mentioned above. We implement the domain adapter layers with LoRA (Hu et al., 2021) and insert them into the self-/cross-attention layers in the base T2I, as shown in Fig. 3. Take query (Q) projection as an example. The internal feature z after projection becomes









{kind=link}