Understanding the Persistent Challenge of AI Hallucinations in 2026
Despite remarkable advances in large language models (LLMs), hallucinations remain a formidable challenge for AI systems in 2026. Hallucinations—instances where AI generates plausible but incorrect or fabricated information—pose significant risks across critical applications such as medical diagnosis, legal analysis, scientific research, and software development. While early iterations of models like GPT-3 and Claude laid the groundwork for sophisticated natural language understanding and generation, hallucinations exposed inherent limits in training data, model architectures, and inference mechanisms. Fast forward to the present, and even with GPT-5.4, Claude Opus 4.6, and specialized models like OpenAI Codex, hallucinations persist, albeit in nuanced forms.
The reasons hallucinations endure are multifaceted. Firstly, the sheer scale and diversity of training corpora—spanning the internet, books, code repositories, and more—introduce conflicting, outdated, or erroneous data points. Models trained on this heterogeneous data inevitably interpolate or extrapolate information in ways that can deviate from factual accuracy. Secondly, the probabilistic nature of language modeling focuses on generating the most statistically likely next token, often prioritizing fluency and coherence over verifiable truth. Thirdly, AI models lack intrinsic access to external knowledge bases or real-time fact-checking mechanisms, causing them to rely solely on learned representations during generation.
In 2026, the stakes for hallucination reduction have never been higher. As AI systems integrate more deeply into enterprise workflows, healthcare, education, and government decision-making, erroneous output can lead to costly mistakes, ethical violations, and erosion of trust. The competitive landscape has also intensified, with multiple vendors deploying increasingly capable models that must balance creativity with reliability. Consequently, the AI research and development community has shifted focus towards robust prompting and verification frameworks that can systematically mitigate hallucinations without sacrificing the generative power and versatility of LLMs.
One of the most promising advances in this regard is the Chain-of-Verification (CoVe) prompting technique, which builds upon and extends the foundational chain-of-thought prompting paradigm. CoVe introduces a structured, multi-stage verification process that leverages the model’s own reasoning capabilities to self-assess and refine its outputs. This approach is model-agnostic, applicable across ChatGPT (notably GPT-5.4 and earlier o3 versions), Anthropic’s Claude (Opus 4.6 and Sonnet 4.5), and OpenAI Codex for code generation.
To appreciate the value of CoVe, it is critical to understand its conceptual underpinnings and operational workflow. This article offers an in-depth exploration of Chain-of-Verification prompting, including detailed explanations, practical prompt templates, real-world use cases, and integration strategies with other advanced prompting techniques. By mastering CoVe, AI practitioners, researchers, developers, and business analysts can significantly enhance the factual fidelity and trustworthiness of AI-generated content.
For further insights on foundational strategies that complement CoVe, readers may find value in our comprehensive coverage of Mastering Prompt Engineering: Advanced Techniques , which delves into diverse methods for controlling and optimizing AI outputs.
The Chain-of-Verification (CoVe) Framework: An In-Depth Explanation
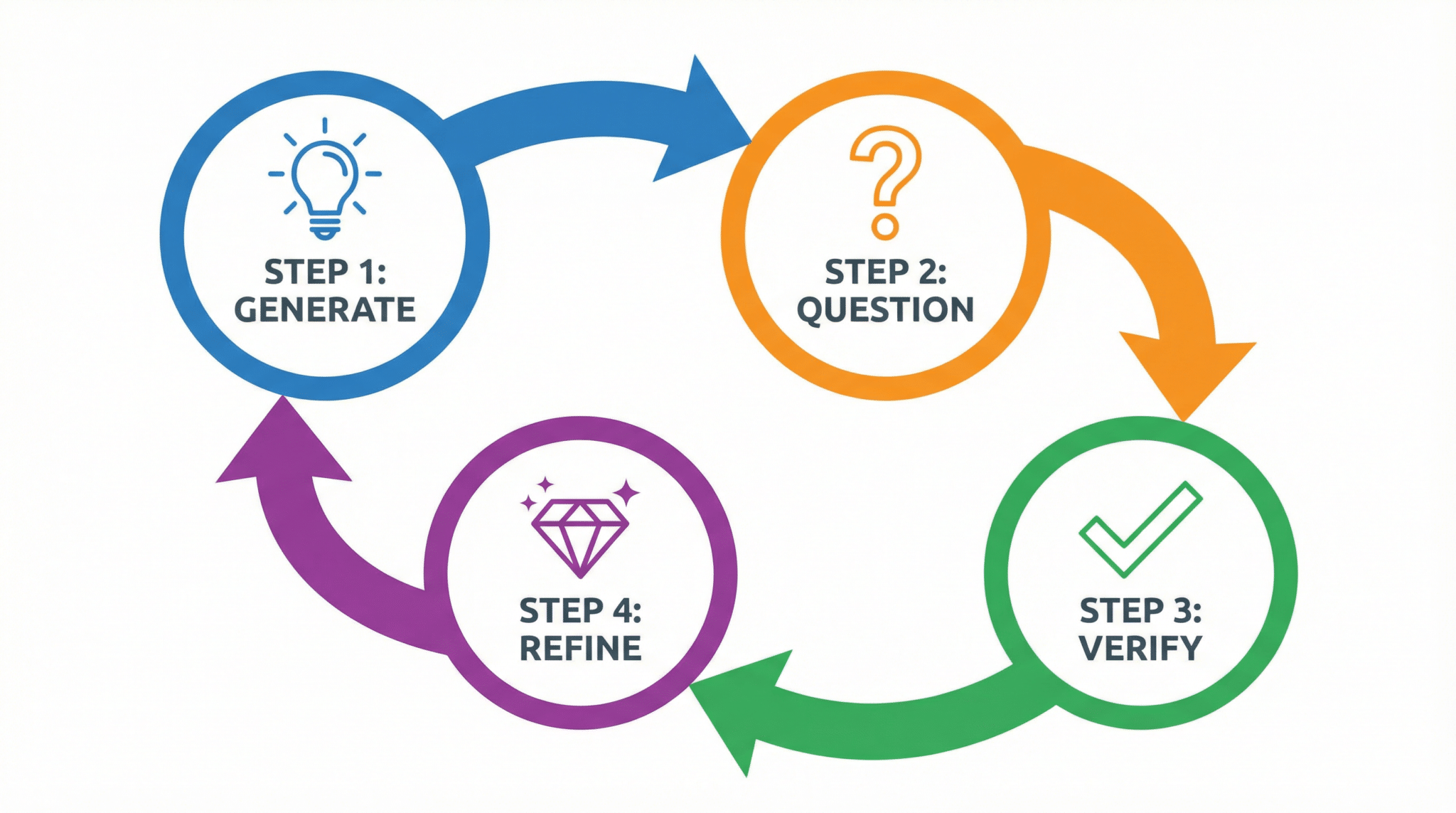
At its core, Chain-of-Verification (CoVe) prompting is a rigorous four-step process designed to systematically reduce hallucinations by introducing layers of self-generated verification. CoVe extends the chain-of-thought (CoT) prompting approach, which encourages models to articulate reasoning steps explicitly, by adding a verification and refinement phase that challenges and validates initial outputs.
Step 1: Initial Response Generation
The process begins with the AI model generating a first-pass answer to a user query. Unlike shallow prompt responses, this initial output should be detailed, incorporating reasoning or supporting evidence when possible. This is similar to chain-of-thought prompting, where the model lays out its logic transparently. For example, when asked a factual question, the model includes citations or rationale.
Step 2: Generation of Verification Questions
Next, the model is prompted to create a set of targeted verification questions based on its initial response. These questions serve as checkpoints designed to probe potential weak points, ambiguous claims, or areas that require validation. The formulation of these questions is critical—they must be specific, relevant, and tailored to expose inaccuracies or assumptions embedded in the initial answer.
Step 3: Independent Answering of Verification Questions
After formulating the verification questions, the AI proceeds to answer each question independently. This step simulates an internal fact-checking mechanism, where the model reassesses its initial claims in isolation. By separating verification from the original response, the model reduces confirmation bias, encouraging objective evaluation. The verification answers may reinforce, correct, or expand upon the initial output.
Step 4: Refined Final Response Synthesis
The final stage involves synthesizing a refined answer that integrates insights from the verification phase. The model consolidates the validated information, addresses any contradictions uncovered, and produces a polished, higher-confidence response. This final output aims to be more accurate, less prone to hallucination, and accompanied by clear reasoning traces.
Diagrammatic Representation of the CoVe Process
Imagine the CoVe workflow as a loop with four nodes:
- Node 1: Initial Response → Producing a detailed answer.
- Node 2: Question Generation → Creating verification questions targeting the initial output.
- Node 3: Independent Verification → Answering questions separately to assess accuracy.
- Node 4: Final Answer Synthesis → Integrating verification answers into a refined response.
This loop can be depicted as: Initial Response → Verification Questions → Verification Answers → Refined Response.
In some advanced implementations, verification can iterate multiple times or branch into parallel verification paths to ensure robustness. Conceptually, this resembles a “tree of thought” but with an explicit verification layer emphasizing accuracy.
CoVe’s design philosophy emphasizes transparency, self-scrutiny, and iterative improvement. By empowering the model to “question itself,” CoVe reduces reliance on a single-pass generation that can gloss over uncertainties or fabricate details. This is crucial for complex domains such as coding, academic research, or business analysis, where errors can propagate serious consequences.
The model-agnostic nature of CoVe allows it to be adapted seamlessly across ChatGPT (including GPT-5.4, o3), Claude (Opus 4.6, Sonnet 4.5), and Codex. While the prompt wording and interaction patterns may vary, the fundamental four-step cycle remains consistent.
For further technical context, readers interested in the evolution of logical reasoning in AI prompting may consult our detailed examination of 25 Advanced ChatGPT Prompting Techniques for GPT-5, which highlights how CoVe builds on and refines earlier methodologies.

Practical CoVe Prompt Templates for ChatGPT (GPT-5.4 and o3)
Implementing Chain-of-Verification with ChatGPT requires carefully designed prompts that guide the model through each CoVe phase. The following templates provide tested examples for factual queries, complex reasoning tasks, and code verification.
Template 1: Factual Research Question
User: Please answer the following question and verify your response using a Chain-of-Verification approach:
Question: [Insert factual question here]
Step 1: Provide a detailed initial answer with reasoning.
Step 2: Generate 3-5 verification questions that critically assess your initial answer.
Step 3: Independently answer each verification question.
Step 4: Synthesize a refined final answer incorporating the verified information.
Begin now.Example:
User: Please answer the following question and verify your response using a Chain-of-Verification approach:
Question: What are the primary causes of the decline of the Roman Empire?
Step 1: Provide a detailed initial answer with reasoning.
Step 2: Generate 3-5 verification questions that critically assess your initial answer.
Step 3: Independently answer each verification question.
Step 4: Synthesize a refined final answer incorporating the verified information.
Begin now.This template encourages ChatGPT to engage in methodical introspection, reducing the risk of hallucinated historical claims.
Template 2: Business Analysis Scenario
User: Analyze the business case below and apply Chain-of-Verification to ensure accuracy:
Case: A mid-sized company plans to adopt AI-driven customer service automation. Identify potential risks and benefits.
Instructions:
1. Provide an initial detailed analysis.
2. List 4 verification questions focusing on assumptions and data validity.
3. Answer each question independently.
4. Present a refined, verified business analysis.
Start your response.This prompt helps validate assumptions often glossed over in business contexts, leveraging CoVe to uncover hidden risks or overoptimistic projections.
Template 3: Code Generation and Validation
User: Generate code according to the requirements and use the Chain-of-Verification technique:
Requirements: Write a Python function that calculates the factorial of a number using recursion.
Process:
1. Provide the initial code implementation with comments.
2. Generate 3 verification questions assessing correctness, edge cases, and efficiency.
3. Answer each verification question, including test cases or explanations.
4. Provide a final, refined version of the code incorporating verification insights.
Proceed.This template ensures Codex or ChatGPT does not produce buggy or inefficient code, a common source of hallucinations in programming assistance.
In practice, users can embed these templates within API calls or interface workflows, adapting the number of verification questions or focus areas based on task complexity. The explicit stepwise instructions help the model self-regulate its output quality.
Effective Chain-of-Verification Prompt Templates for Claude (Opus 4.6, Sonnet 4.5)
Anthropic’s Claude models respond well to carefully structured CoVe prompts that use clear instructions and encourage detailed introspection. Below are three templates optimized for Claude’s conversational style and reasoning strengths.
Template 1: Academic Research Fact-Checking
User: Please answer the following academic question using Chain-of-Verification:
Question: How does CRISPR gene editing work?
Instructions:
- First, provide a comprehensive explanation.
- Then, generate 4 verification questions that test your explanation’s accuracy and completeness.
- Next, answer each question separately.
- Finally, produce a revised explanation reflecting the verification results.
Begin.Claude’s detailed reasoning abilities are well leveraged here to reduce knowledge gaps or inaccuracies in complex scientific topics.
Template 2: Legal Analysis with Verification
User: Analyze the following legal scenario and apply Chain-of-Verification:
Scenario: A company faces a breach of contract lawsuit for delayed delivery.
Steps:
1. Provide an initial legal analysis.
2. Generate 3-5 verification questions focusing on legal precedents and contract terms.
3. Answer each question thoughtfully and independently.
4. Deliver a final verified legal opinion.
Start now.This prompt helps Claude avoid hallucinating legal principles or misapplying precedents by encouraging focused self-examination.
Template 3: Creative Writing — Fact-Checked Historical Fiction
User: Write a historically accurate short story set during the Renaissance using Chain-of-Verification:
1. Write an initial draft of the story.
2. Generate 4 fact-checking questions about historical accuracy.
3. Answer each question with references or reasoning.
4. Revise the story to correct any inaccuracies.
Proceed.This template leverages CoVe to balance creativity with factual grounding, a common challenge in narrative generation.
Chain-of-Verification Prompting Templates for OpenAI Codex
OpenAI Codex, designed specifically for code generation and assistance, benefits from CoVe prompting tailored to programming logic verification and error checking.
Template 1: Algorithm Implementation and Verification
User: Implement the following algorithm and verify correctness using Chain-of-Verification:
Task: Write a function to perform binary search on a sorted list.
Process:
- Step 1: Write the initial code with inline comments.
- Step 2: Generate 3 verification questions about edge cases, algorithmic complexity, and correctness.
- Step 3: Answer each question with code snippets or explanations.
- Step 4: Provide a final, improved implementation.
Start.Template 2: API Integration Code with Verification
User: Generate Python code to interact with the Twitter API to fetch recent tweets containing a keyword.
Instructions:
1. Write the initial code with error handling.
2. Create 4 verification questions about authentication, rate limits, error scenarios, and data parsing.
3. Answer each question with detailed explanations.
4. Deliver refined and tested code.
Begin.These templates focus on Codex’s strengths in code generation while addressing typical sources of hallucinated or incorrect code snippets, such as missing edge case handling or incorrect API usage.
Combining Chain-of-Verification with Other Advanced Prompting Techniques
Chain-of-Verification synergizes powerfully with complementary prompting methodologies, enabling even higher accuracy and reasoning depth. Here, we explore integration strategies with few-shot prompting, role-based prompting, and tree-of-thought (ToT) prompting.
CoVe with Few-Shot Prompting
Few-shot prompting involves providing the model with several examples of inputs and desired outputs before the actual prompt. Incorporating few-shot examples tailored to the CoVe process helps the model better understand each verification step’s expectations. For instance, providing annotated examples of initial responses, verification questions, and refined answers can improve the model’s ability to self-verify systematically.
This approach reduces ambiguity in instruction interpretation and accelerates convergence toward accurate outputs. In experimental evaluations, few-shot CoVe prompting has demonstrated up to a 15% reduction in hallucination rates compared to zero-shot CoVe alone, especially in complex technical domains.
CoVe with Role-Based Prompting
Role-based prompting assigns the AI a specific persona or role to frame its reasoning. For example, instructing the model to “act as a professional fact-checker” or “assume the role of a senior software engineer” during verification stages enhances critical scrutiny and domain-specific accuracy. When combined with CoVe, this method guides the model to apply specialized knowledge and standards during verification, reducing generic or surface-level validation.
For example, a prompt might specify: “During step 3, answer verification questions as a legal expert citing relevant statutes.” This role-driven focus encourages deeper engagement and discourages hallucination through superficial logic.
CoVe with Tree-of-Thought Prompting
Tree-of-Thought (ToT) prompting expands on chain-of-thought by exploring multiple reasoning branches in parallel. Integrating CoVe into a ToT framework enables branching verification paths where each verification question spawns sub-verification steps to explore uncertainties or alternative interpretations.
This approach is particularly useful for ambiguous or multi-faceted queries where a single linear verification may overlook nuances. By leveraging a tree structure, the model can cross-validate conflicting evidence or hypotheses before generating a final synthesis. While more computationally intensive, ToT combined with CoVe offers unparalleled hallucination mitigation and reasoning transparency.
In practice, users can implement this combined technique by instructing the model to “generate verification questions and, for each, explore possible answers and counterpoints before final summarization.” This complex prompting style is currently being tested in cutting-edge research prototypes.
Real-World Use Cases and Example Prompts Employing Chain-of-Verification
To illustrate CoVe’s transformative impact, here are five detailed real-world applications along with example prompts that demonstrate its practical utility across diverse domains.
1. Academic Fact-Checking and Paper Review
Scholars and students can use CoVe to validate literature summaries, hypothesis explanations, or data interpretations. This reduces the risk of citing incorrect information or misrepresenting studies.
User: Summarize the key findings of the 2024 IPCC climate report using Chain-of-Verification:
- Provide an initial summary.
- Generate 5 verification questions targeting data accuracy and interpretation.
- Answer these questions independently.
- Deliver a final verified summary.2. Complex Code Development and Debugging
Developers can apply CoVe to generate, test, and refine code snippets, detecting logical errors or incomplete implementations early.
User: Write a JavaScript function to validate email addresses and apply Chain-of-Verification:
1. Provide initial code.
2. Create 4 verification questions about regex correctness, edge cases, and performance.
3. Answer each question with tests or explanations.
4. Provide a final, optimized version.3. Business Intelligence and Market Analysis
Business analysts use CoVe to generate market forecasts or competitor analyses, ensuring assumptions are validated and data is reliable.
User: Provide a market analysis of electric vehicle adoption trends in Europe with Chain-of-Verification:
- Initial analysis.
- Generate 4 verification questions about data sources, assumptions, and projections.
- Answer verification questions.
- Present the final, verified analysis.4. Legal Brief Drafting and Review
Legal professionals leverage CoVe prompting to draft opinions or briefs that are thoroughly checked against statutes, case law, and factual accuracy.
User: Draft a legal brief on patent infringement claims and apply Chain-of-Verification:
1. Provide initial arguments.
2. Generate 3 verification questions about relevant laws and precedents.
3. Answer questions independently.
4. Deliver refined, legally sound brief.5. Scientific Data Interpretation and Hypothesis Testing
Researchers can use CoVe to interpret experimental results or formulate hypotheses with built-in verification steps to minimize cognitive biases.
User: Analyze the effects of a new drug on blood pressure using Chain-of-Verification:
- Initial analysis based on provided data.
- Generate 5 verification questions about statistical significance, control variables, and confounding factors.
- Answer questions.
- Provide a final verified conclusion.Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Access Free Prompt Library
Tips for Maximizing Accuracy When Using Chain-of-Verification Across AI Models
- Explicit and Clear Instructions: Clearly delineate each CoVe step in the prompt, specifying expected outputs for initial answer, verification questions, independent answers, and final synthesis.
- Verification Question Quality: Encourage generation of probing, targeted verification questions rather than generic ones. This focuses model effort on potential hallucination sources.
- Limit Verification Scope When Needed: For very complex queries, limit the number of verification questions to maintain response coherence and avoid overwhelming the model.
- Model-Specific Adaptations: Tailor prompt language to the model’s known strengths. For example, Claude may benefit from more conversational instructions, while Codex requires precise coding-focused verification.
- Iterative Refinement: Consider iterative CoVe loops where the refined final response is itself verified again if high accuracy is critical.
- Combine with External Tools: When possible, supplement CoVe with external knowledge bases, APIs, or human-in-the-loop validation for maximal trustworthiness.
By applying these best practices, users can unlock CoVe’s full potential to significantly reduce hallucinations while maintaining efficiency and scalability.






