Table of Links
Abstract and 1 Introduction
2 Related Works
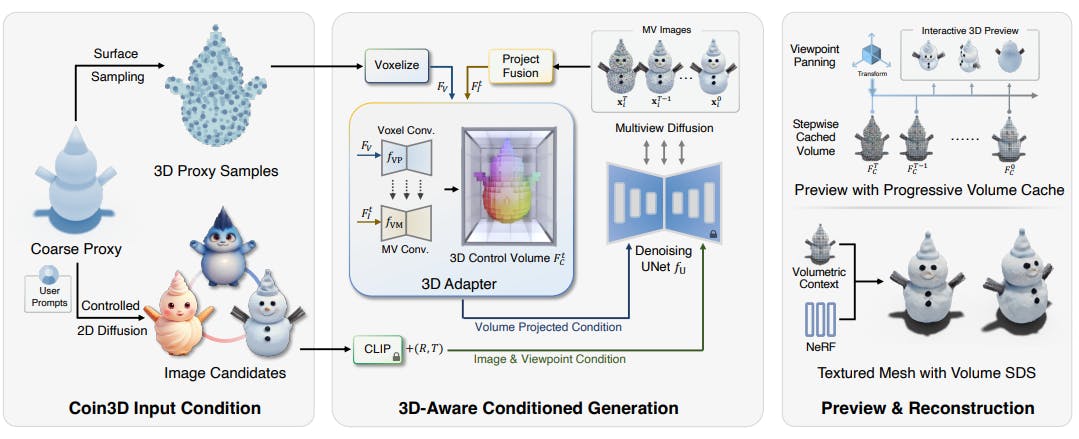
3 Method and 3.1 Proxy-Guided 3D Conditioning for Diffusion
3.2 Interactive Generation Workflow and 3.3 Volume Conditioned Reconstruction
4 Experiment and 4.1 Comparison on Proxy-based and Image-based 3D Generation
4.2 Comparison on Controllable 3D Object Generation, 4.3 Interactive Generation with Part Editing & 4.4 Ablation Studies
5 Conclusions, Acknowledgments, and References
SUPPLEMENTARY MATERIAL
A. Implementation Details
B. More Discussions
C. More Experiments
2.1 3D Object Generation
3D object generation is a popular task in computer vision and graphics. Early works [Achlioptas et al. 2018; Dubrovina et al. 2019; Kluger et al. 2021] mainly focus on natively generating 3D representations from models, such as polygon meshes [Gao et al. 2022; Groueix et al. 2018; Kanazawa et al. 2018; Nash et al. 2020; Wang et al. 2018], pointclouds [Achlioptas et al. 2018; Fan et al. 2017; Nichol et al. 2022; Yu et al. 2023], parametric models [Hong et al. 2022; Jiang et al. 2022], voxels [Choy et al. 2016; Sanghi et al. 2022; Wu et al. 2017; Xie et al. 2019], or implicit fields [Chan et al. 2022, 2021; Cheng et al. 2023a; Gu et al. 2021; Jun and Nichol 2023; Li et al. 2023b; Mescheder et al. 2019; Park et al. 2019; Skorokhodov et al. 2022], which learn from specific CAD database [Chang et al. 2015] and are often bounded by specific categories (e.g., chairs, cars,


and etc.) due to the limited network capacity and data diversity. Recently, with the rapid evolution in large-scale generative models, especially the great success in 2D diffusion models [Ramesh et al. 2022; Rombach et al. 2022; Saharia et al. 2022], methods like DreamFusion [Poole et al. 2022], SJC [Wang et al. 2023a] and their follow-up works [Chen et al. 2023a; Lin et al. 2023; Melas-Kyriazi et al. 2023; Raj et al. 2023; Seo et al. 2023; Tang et al. 2023a,b; Xu et al. 2023c] attempt to distill 2D gradient priors from the denoising process using score distillation sampling loss (SDS loss) or its variants, which guide the per-shape neural reconstruction following users’ text prompts. While being generic to unlimited categories and diverse composited results with prompt engineering, these lines of work often suffer from unstable convergence due to the noisy and inconsistent gradient signal, which often leads to incomplete results or “multi-face Janus problem” [Chen et al. 2023a]. Subsequently, Zero123 [Liu et al. 2023c] analyzes the viewpoint bias problem of the generic 2D latent diffusion model (LDM), and proposes to train an object-specific LDM with relative viewpoint as a condition using Objaverse dataset [Deitke et al. 2023], which shows promising results in the image-to-3D tasks, and has been widely adopted in the follow-up 3D generation works [Liu et al. 2023d; Qian et al. 2023]. While being fine-tuned on multiview images, Zero123 still suffers from the cross-view inconsistency issue as its resulting images cannot satisfy the requirements for reconstruction.
Hence, later works such as MVDream [Shi et al. 2023b], SyncDreamer [Liu et al. 2023a], Zero123++ [Shi et al. 2023a] and Wonder3D [Long et al. 2023] propose to enhance multiview image generation, which either trains with stacked views [Long et al. 2023; Shi et al. 2023a,b] or builds synchronized volumes online to condition the diffusion process [Liu et al. 2023a], and usually enables to produce highly consistent images or yields 3D reconstructions in few seconds. Very recently, LRM [Hong et al. 2023] and its variant methods [Wang et al. 2023b; Xu et al. 2023b] propose to train an end-to-end transformer-based model, which directly produces neural reconstruction given one or few perspective images. Nevertheless, existing 3D object generation methods primarily focus on using text prompts (text-to-3D) or images (image-to-3D) as the input, which cannot accurately convey exact 3D shapes or precisely control the generation in a 3D manner. By contrast, our method first adds 3D-aware control to the multiview diffusion process without compromising generation speed, which realizes interactive generation workflow with 3D proxy as conditions.
2.2 Controllable and Interactive Generation
Adding precise control to the generative methods is crucial for productive content creation [Bao et al. 2023; Epstein et al. 2022; Yang et al. 2022a, 2024, 2022b, 2021]. Previous generative works [Bao et al. 2024; Chen et al. 2022; Deng et al. 2023; Hao et al. 2021; Melnik et al. 2024] mainly learn a latent mapping of the attributes to add control to the generation, but are limited to specific categories (e.g., human faces or nature landscape). Recent progress in 2D diffusion models, such as ControlNet [Zhang et al. 2023] and T2I-Adapter [Mou et al. 2023], enables various 2D image hints (e.g., depth, normal, softedge, human poses, color grids, and etc.), to interactively control the denoising process of the image generation. However, similar controllable capabilities [Bhat et al. 2023; Cohen-Bar et al. 2023; Pandey et al. 2023] in 3D generation are far from applicable. For generative 3D editing, recent works [Cheng et al. 2023b; Li et al. 2023a] propose to constrain the text-driven 3D generation at the desired region, but cannot support controlling the exact geometry shape. For Controllable 3D generation, the most related works to our methods are Latent-NeRF [Metzer et al. 2023] and Fantasia3D [Chen et al. 2023a]. However, these two works cannot ensure steady convergence and the generated results are usually far from the given 3D shape (see Sec. 4.2), as they naïvely add control to the 3D representation regardless of altering the supervision of 2D priors (i.e., SDS loss).
Other works such as Control3D [Chen et al. 2023b] only add control from 2D sketches/silhouettes instead of 3D space. Moreover, all these methods require a long time of reconstruction (e.g., from dozens of minutes to hours) to inspect the effect of editing or controlling, which cannot fulfill the demand for interactive modeling. On the contrary, our method directly integrates the 3D-aware control into the diffusion process, which not only ensures faithful and adjustable control over the 3D generation but also allows to interactively preview the generated/edited 3D object in a few seconds.
Authors:
(1) Wenqi Dong, from Zhejiang University, and conducted this work during his internship at PICO, ByteDance;
(2) Bangbang Yang, from ByteDance contributed equally to this work together with Wenqi Dong;
(3) Lin Ma, ByteDance;
(4) Xiao Liu, ByteDance;
(5) Liyuan Cui, Zhejiang University;
(6) Hujun Bao, Zhejiang University;
(7) Yuewen Ma, ByteDance;
(8) Zhaopeng Cui, a Corresponding author from Zhejiang University.







{kind=link}