Datadog has launched Monocle, a new real-time timeseries storage engine written in Rust. The system unifies the company’s metrics storage infrastructure, delivering higher ingestion throughput and lower query latency while reducing operational complexity. Monocle replaces several generations of storage backends, addressing concurrency challenges and scaling limits that accumulated over time.
Earlier designs of Datadog’s storage infrastructure separated responsibilities across multiple systems. Metrics data was written into the Real-Time Database (RTDB), which stored <timeseries_id, timestamp, value> tuples, while an index database maintained identifiers and tags. A storage router directed metrics to RTDB nodes, and queries fanned out across RTDB and index nodes. Each node contained subsystems for ingestion, storage, snapshots, queries, and throttling, all coordinated through a shared control plane.
High-level overview of real-time metric storage architecture(Source: Datadog Engineering Blog)
This architecture of RTDB went through several iterations. The first generation relied on Cassandra for high write throughput but limited query flexibility. A Redis-based design followed, improving responsiveness but encountering durability and single-thread execution issues. MDBM, a memory-mapped key–value store, offered better use of operating system caching but ran into scalability bottlenecks. A subsequent Go-based B+ tree engine adopted a thread-per-core model, which added concurrency but also complexity. Later, RocksDB provided persistence and support for distribution metrics through DDSketch, though challenges in scaling remained.
Monocle consolidates these previous approaches into a unified Rust-based engine. It adopts a shard-per-core, worker-per-shard model, with each storage worker managing its own log-structured merge tree (LSM-tree) instance to ingest data, serve queries, and perform background tasks such as compactions.The design embraces early sharding beyond storage: each unit of data, identified by its timeseries key, is assigned to a shard, ensuring even load distribution across CPU cores.As Datadog engineers note, “This shard-per-core, async worker model is fundamental to RTDB.” The design eliminates locks and atomic operations on the write path, reducing contention, while Rust’s memory guarantees safety and concurrency.

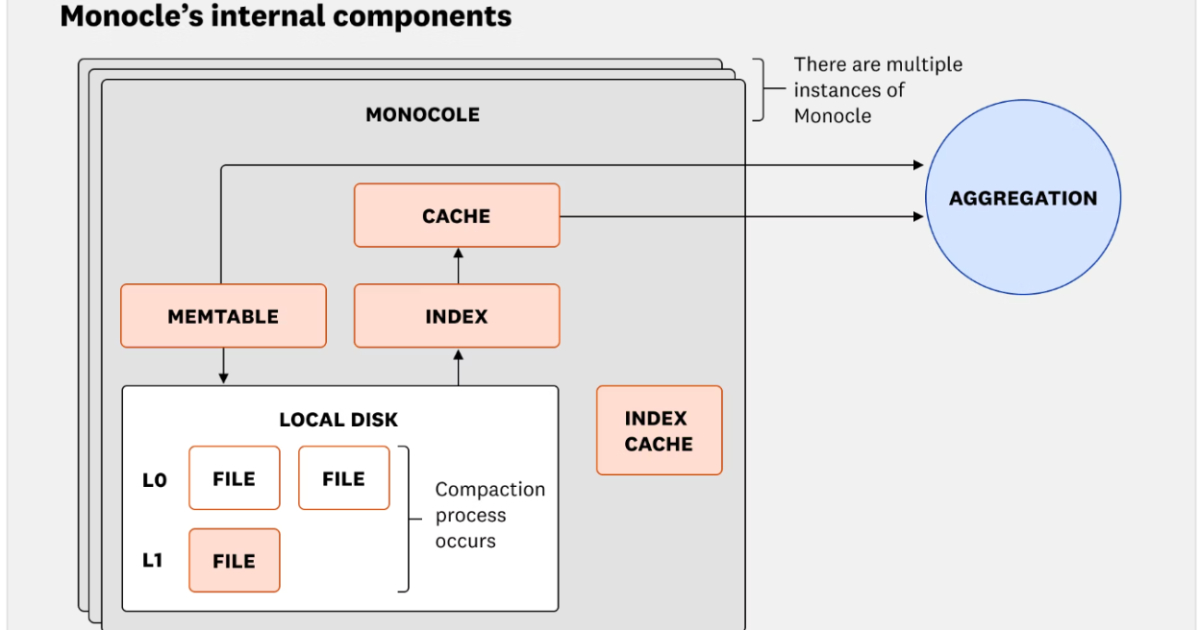
Monocle’s internal components (Source: Datadog Engineering Blog)
The engine integrates ingestion, storage, and query handling within a single system. Writes are buffered in memtables and persisted using LSM-tree-inspired compaction. Radix-tree buffers accelerate aggregations, while unified caches reduce query latency. Data is segmented by time with a least-recently-used (LRU) policy within each segment to evict stale queries while retaining the most relevant, ensuring freshness and responsiveness under load.
Performance benchmarks reported by Datadog show significant gains. Monocle achieved a 60x increase in ingestion throughput, a 5x reduction in query latency at peak scale, and twice the cost efficiency compared with earlier systems. These improvements are attributed to the shard-per-core concurrency model, Rust’s efficiency, and optimizations in both write and query paths.
Datadog’s engineers note that another key benefit of the Rust rewrite and modular design is that components developed for Monocle are now being repurposed across other systems at Datadog, improving both maintainability and platform-wide consistency.






{kind=link}