In 2024 Large Language Model (LLM), Neuro-Linguistic Programming (NLP), Artificial Intelligence (AI), and Value Creation seem to be the buzzword and a constant theme, but it can be overwhelming to Segway into the ecosystem, so, let’s dive into a single concept RAG (Retrieval Augmented Generation) to build our understanding and how we can utilize it for our digital products.
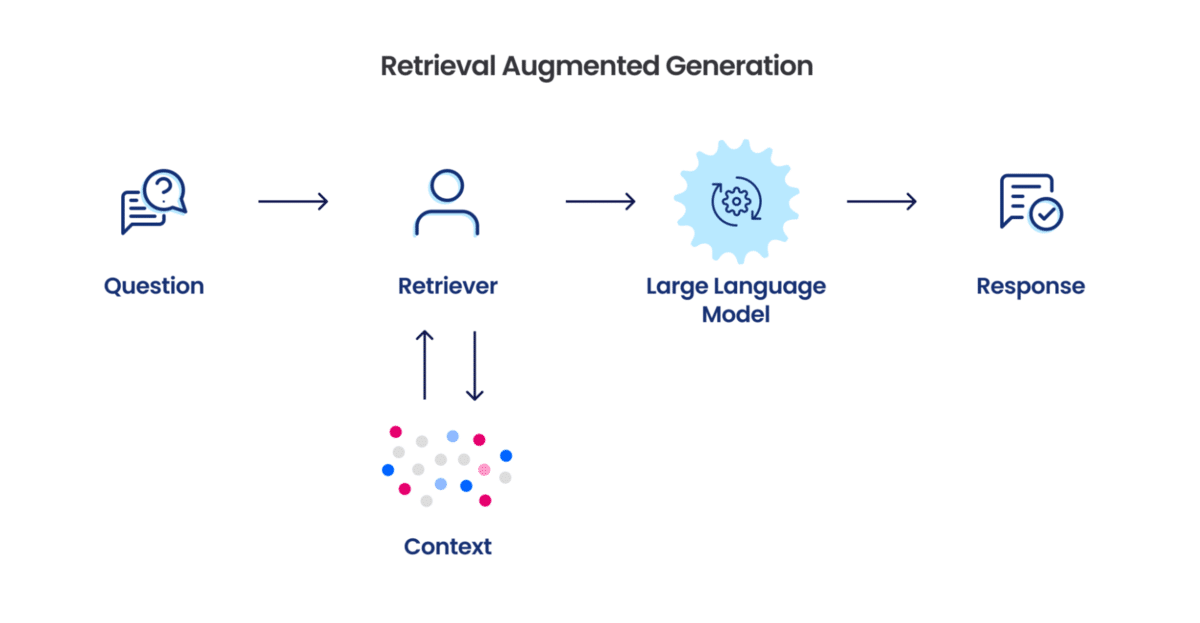
RAG is a revolutionary AI technology that advances the generation of text by the inclusion of external knowledge. It consists of a retriever, which finds relevant information within a large knowledge base, and a generator that will leverage this information to create a response with accuracy and consideration of context.
This model currently serves many use cases, from Q&A systems and Chatbots to Document summarizer making the response both reliable and informative. The greatest challenge large enterprises face is the fragmented data store which hibernates within their ecosystem. This fragmented data store grossly reduces an organizations efficiency and its ability to generate tangible insights out of this data. The advanced RAG systems give an extremely effective method for unification of fragmented data without compromising security and compliance standards and enables better visualization of information across multiple source channels of information.
1. Organizational Challenges and Data Introductions: The challenge of Data Fragmentation
Organizations have to deal with variety of challenges concerning data spread across several systems and data lakes, data could be stored in personal systems, SharePoint sites, one drive and the infamous Excel sheets which also spreads across multiple worksheets, extraction of information from this data store is murky and can be quite challenging and the loss to data veracity in the data also leads to inefficiencies and poor user experiences.
On a higher layer of abstraction, the data landscape can be categorized into two categories:
- Structured Data
- Unstructured Data
Both data categories are equally relevant for an enterprise ecosystem, though unstructured data contains 80% of the organizational data which is hard to access and generate insights from.


To expand further – A classic example with unstructured data is encountered across industries where data is fragmented and spread across different file structures such as PDF, WORD, XLSX, JPG, CSV etc.
Case in point is the behemoth of the data iceberg which resides within the financial sector ecosystems (Commercial and Private Banks, Private Equities, Insurance providers), where project and policy documents and their file management is an excruciating pain point. Transformation strategies to enrich the unstructured data are defined below so the data can be ingested in the systems for further processing/analysis and is captivating for the business audience who can immediately derive value from the unstructured data sources.


Consequently, RAG has become more relevant to solve this very problem within the enterprise ecosystem, to complement the retrieval of information from all these documents lying within the unstructured data lake inside the organization that enable better extraction of value out of information which is going to help in
- Fetch and Triangulate via customer and organizational data
- Improve the error rate in data insights generation.
- Improve analytics and reporting-dashboards for senior stakeholders and C-suite executives to make informed decisions.
2. Large Language Model (LLM) Customization Stages: The Foundation of Effective RAG
RAG technology enhances Large Language Models by enabling them to access and integrate information from custom knowledge bases and documents which are usually not part of a standard LLM Model, ensuring contextually relevant outputs which is aligned with specific document repositories relevant to the organization. To optimize LLM implementations, organizations can focus their customization efforts at three strategic points for development of a custom solution, with cost considerations driving the decision-making process at which stage the focus should be tailored to –
A. Input-Level Customization: This cost-effective approach achieves model performance optimization through either the usage of prompt engineering/prompt tuning or RAG implementation. Healthcare organizations demonstrate this effectively by tailoring their systems to process specialized medical terminology and clinical documentation which is context relevant and tailored to the specific geographical landscape.
B. Model-Level Customization: This intermediate approach focuses on refining vector databases and embedding techniques while training models on organization-specific data, Though the cost parameters increases at this stage, this may be more suitable for large players who can afford an R&D team. E-commerce platforms exemplify this strategy by integrating customer purchase histories with their recommendation systems to deliver personalized shopping experiences thus reducing customer churn and acquiring new buyers.
C. Output-Level Customization: While this approach is more resource-intensive, It ensures precise alignment with organizational objectives and proves particularly valuable for innovative applications. This level of customization provides the highest degree of control over system outputs, making it suitable for specialized use cases which require unique output formats or standards.
Each customization tier represents a different balance between implementation cost, operational complexity, and performance optimization, and the decision making process to adhere to a single stage is highly dependent on affordability, and based on the cost parameters organizations can select the most appropriate approach specific to their requirements.
While Input customization might be more suitable for a smaller enterprise or a limited use case, Model and Output customization take prevalence when the cost parameter could exceed millions of dollars.


Bearing in mind that the cost of model customization increases as you move away from input customization, the below outlines the level of complexity and cost parameter for an organizational ecosystem as one moves away from Input customization, Noteworthy in this sense is to build a RAG if the organization is small size.


3. Technical Architecture
A RAG model architecture might range from most simplistic vector store extraction to incrementally complex Agentic AI landscape, However, below is a representation of the minimalist architecture for RAG which can deal with heterogeneous data types to enable the system in taking user input and generating content relevant user output, This architecture can be further scaled to incorporate more complexity in terms of techniques, though the borderline skeleton remains the same.


A. Query Processing Module (Input)
The system initiates its function with query input processing, including advanced data preparation techniques. It consists of thorough data cleansing operations and advanced transformation processes that optimize the input for the subsequent stages of processing.
B. Retrieval Module-Processing Engine
This module is responsible for the major task of information retrieval on the basis of processed queries. The mechanism of retrieval uses various methods to extract accurate and relevant information from the knowledge base.
C. Output Module: Language Model Integration
The system uses the latest capability of the Language Model that typically integrates solutions such as OpenAI or Claude and further augments them with custom data to build contextually appropriate responses.
Vector Database Integration
The vector database acts as core infrastructure along the whole flow of RAG. Among its major features are storing and retrieving the vector embeddings for various types of data, including text, video, and audio.
Chunking mechanisms to segment information into contextual vectors, pattern recognition through linguistic clustering, and the use of K-Nearest Neighbors in making queries for information. The chunking of information into meaningful vector representations, subsequent clustering based on the linguistic pattern, and execution of a query with the help of the K-NN algorithm, which efficiently parses through large volumes of data, collaborate in synthesizing the most pertinent information for output generation with the help of the OpenAI engine.
A schematic for Vector DB pipeline and at what stage it is used in the RAG is represented below:


Process flow within RAG


Web based Pipeline interface of RAG


In short, RAG architecture enhances the capabilities of LLMs by incorporating external information through retrieval mechanisms, enabling them to generate more accurate and contextually informed outputs aligned with the user inputs.
4. RAG Use Cases


RAG Systems in Production: Current Use Cases and Applications
-
Enterprise Knowledge Management Integration: Organizations are using RAG-powered systems to enable natural language searches across their knowledge bases and provide access to critical information across departments. Major global organizations have already applied such systems to make policy documentation and organizational knowledge more accessible and efficient.
-
Enhanced Customer Support Operations: RAG-powered virtual assistants are breaking the ice by integrating a variety of data sources to help solve customer queries completely. Deploying such RAG-enabled chatbots is reported to reduce response time by 30% alone in the telecommunication firms, thus improving customer satisfaction metrics.
-
Financial Compliance and Audit Automation: Financial institutions are now adapting to RAG systems so as to automate processes concerning compliance and real-time processing of data. These have further enabled instant document retrieval, automated audit procedures, regulatory compliance, and minimized requirement of manual intervention.
-
Intelligent Sales and Content Recommendations: RAG systems will revolutionize product recommendations through advanced analysis of user feedback data. Examples include streaming services, which provide region-specific content recommendations based on extensive data analysis and lead to better user engagement and satisfaction.
5. Future Outlook
In Summary, RAG has the potential to change many fundamentals in AI applications by solving some of the most critical challenges in the field. The evolution of the technology will happen on many dimensions, major improvements in neural search models and retrievers will enable the scaling up of knowledge bases, while better integration with generative models will allow for finer contextual understanding.
In enterprise domain, RAG technology is all set to prove instrumental in several diverse applications-from uplifting customer support experiences to driving real-time decision-making systems and delivering personalized content at scale, the impact would be huge. Since RAG is Multi-modal it’s capabilities makes its utility larger by enabling meaningful interactions across text, image, and video functions.
While the knowledge bases continue to grow exponentially and the models get increasingly sophisticated and advanced, surpassing human intelligence, RAG will provide the basic architecture on which all knowledge-driven AI applications will be based, and AI Agents will be built to operate as your daily co-pilot, enabling asymmetric productivity within the organizations.

/cdn.vox-cdn.com/uploads/chorus_asset/file/25810931/lggram1.jpg)





{kind=link}