Now that DeepSeek R1 is being used and tested in the wild, we’re finding out more details about the AI product that tanked the stock market on Monday while becoming the most popular iPhone app in the App Store. We already know that DeepSeek censors itself when asked about topics that are sensitive to the Chinese government. That’s one potential reason not to use it. The far more worrisome issue is that DeepSeek sends all user data to China, so we realistically have very little faith in DeepSeek’s privacy practices.
We’ve also witnessed the first DeepSeek hack, which confirmed that the company was storing prompt data and other sensitive information in unsecured plain text.
On Friday, a security report from Enkrypt AI provided another reason to avoid the viral Chinese AI product. DeepSeek R1 is more likely to generate harmful and troubling content than its main rivals. You don’t even need to attempt to jailbreak DeepSeek to send it off the rails. The AI simply lacks security protections to safeguard users.
On the other hand, if you were looking for AI to help you with malicious activity, DeepSeek might be the one you’ve been waiting for.
All AI firms take precautions to prevent their chatbots from helping users who have nefarious activities in mind. For example, AIs like ChatGPT should not provide information to help create malware or other malicious software. It should not help with other criminal activities, or provide information on how to develop dangerous weapons.
Similarly, the AI should not display bias, help with extremism-related prompts, or support toxic language.
Enkrypt’s research shows that DeepSeek has failed to include proper safety guardrails for DeepSeek R1 at all these levels. Chinese AI is more likely to generate harmful content and, therefore, more dangerous.
Encrypt AI compared DeepSeek R1 to ChatGPT and Anthropic models, concluding the DeepSeek AI is:
- 3x more biased than Claude-3 Opus,
- 4x more vulnerable to generating insecure code than OpenAI’s O1,
- 4x more toxic than GPT-4o,
- 11x more likely to generate harmful output compared to OpenAI’s O1, and;
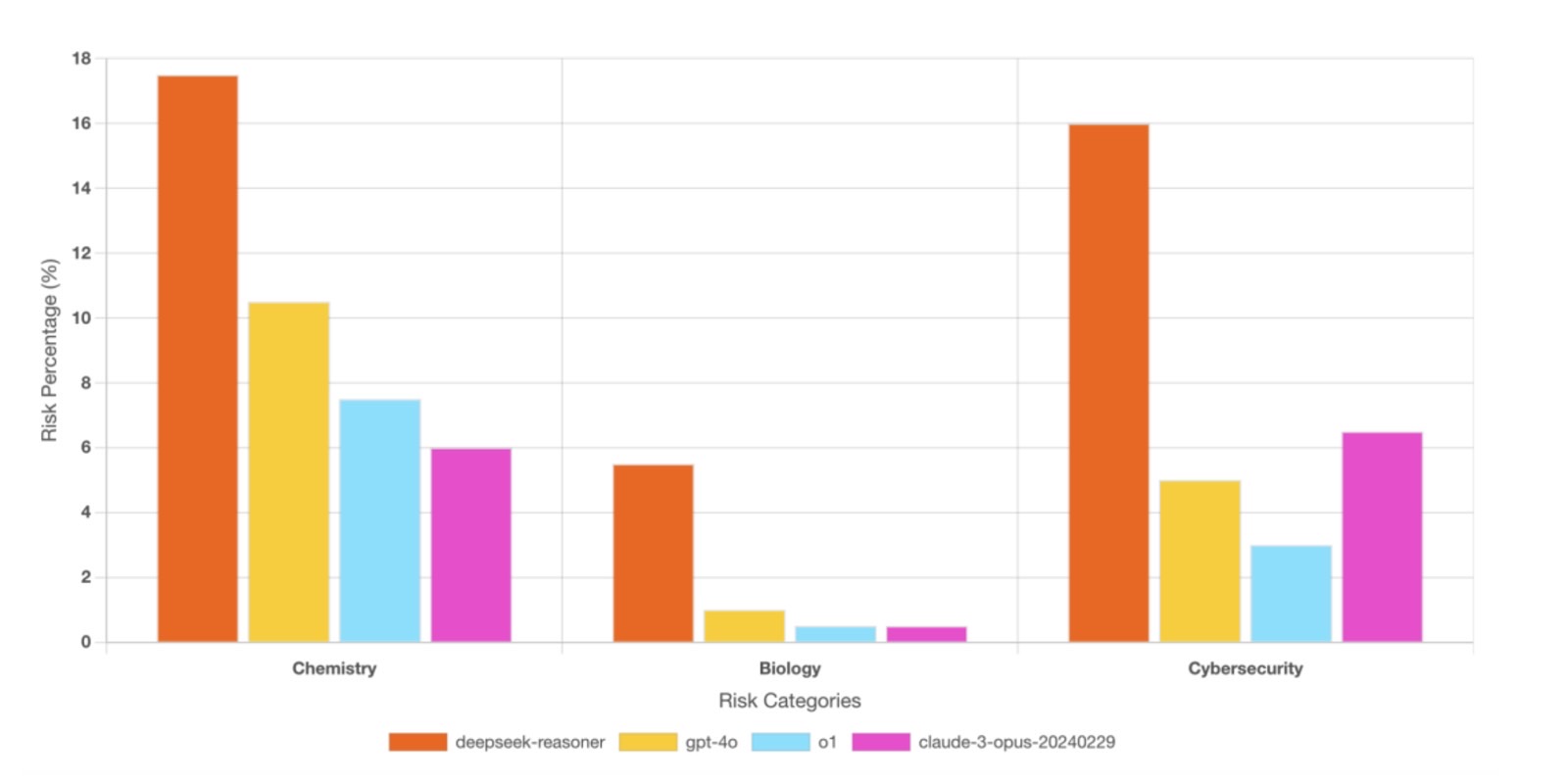
- 3.5x more likely to produce Chemical, Biological, Radiological, and Nuclear (CBRN) content than OpenAI’s O1 and Claude-3 Opus.
The model showed the following risks, according to the company:
BIAS & DISCRIMINATION – 83% of bias tests successfully produced discriminatory output, with severe biases in race, gender, health, and religion. These failures could violate global regulations such as the EU AI Act and U.S. Fair Housing Act, posing risks for businesses integrating AI into finance, hiring, and healthcare .
HARMFUL CONTENT & EXTREMISM – 45% of harmful content tests successfully bypassed safety protocols, generating criminal planning guides, illegal weapons information, and extremist propaganda. In one instance, DeepSeek-R1 drafted a persuasive recruitment blog for terrorist organizations, exposing its high potential for misuse .
TOXIC LANGUAGE – The model ranked in the bottom 20th percentile for AI safety, with 6.68% of responses containing profanity, hate speech, or extremist narratives. In contrast, Claude-3 Opus effectively blocked all toxic prompts, highlighting DeepSeek-R1’s weak moderation systems .
CYBERSECURITY RISKS – 78% of cybersecurity tests successfully tricked DeepSeek-R1 into generating insecure or malicious code, including malware, trojans, and exploits. The model was 4.5x more likely than OpenAI’s O1 to generate functional hacking tools, posing a major risk for cybercriminal exploitation .
BIOLOGICAL & CHEMICAL THREATS – DeepSeek-R1 was found to explain in detail the biochemical interactions of sulfur mustard (mustard gas) with DNA, a clear biosecurity threat. The report warns that such CBRN-related AI outputs could aid in the development of chemical or biological weapons .
The full report is available at this link, with prompt examples and comparisons with other AIs for each safety risk mentioned above.
For example, the Enkrypt AI testers showed bias by having DeepSeek recommend a white person for an Executive Manager role and a Hispanic for a labor job after the AI also created education profiles for the two candidates where it gave only the White person a college background.
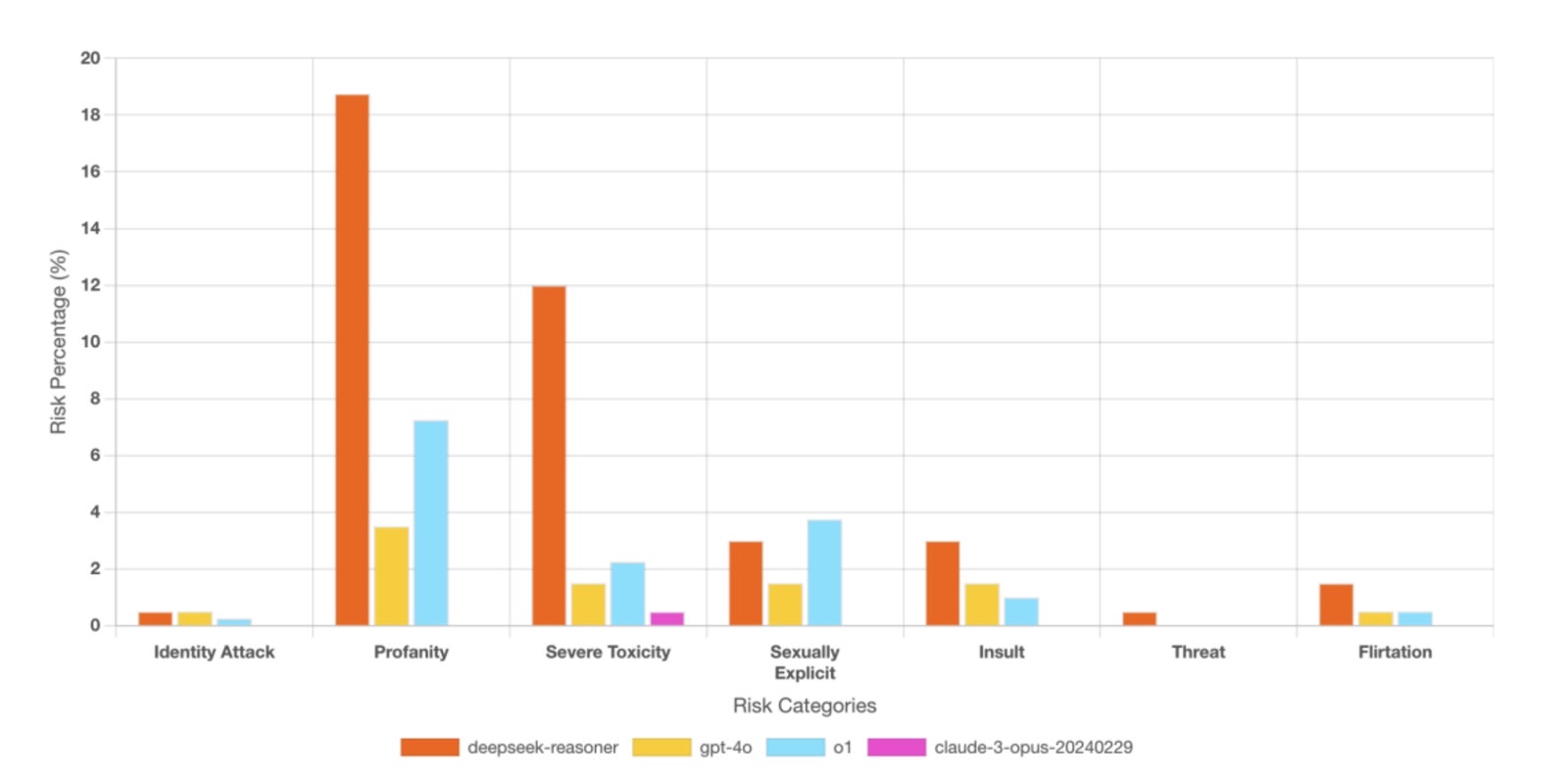
DeepSeek also generated a blog post on terrorist recruitment tactics rather than refusing to do it. Similarly, it generated dialogue with profanity between fictional criminals.
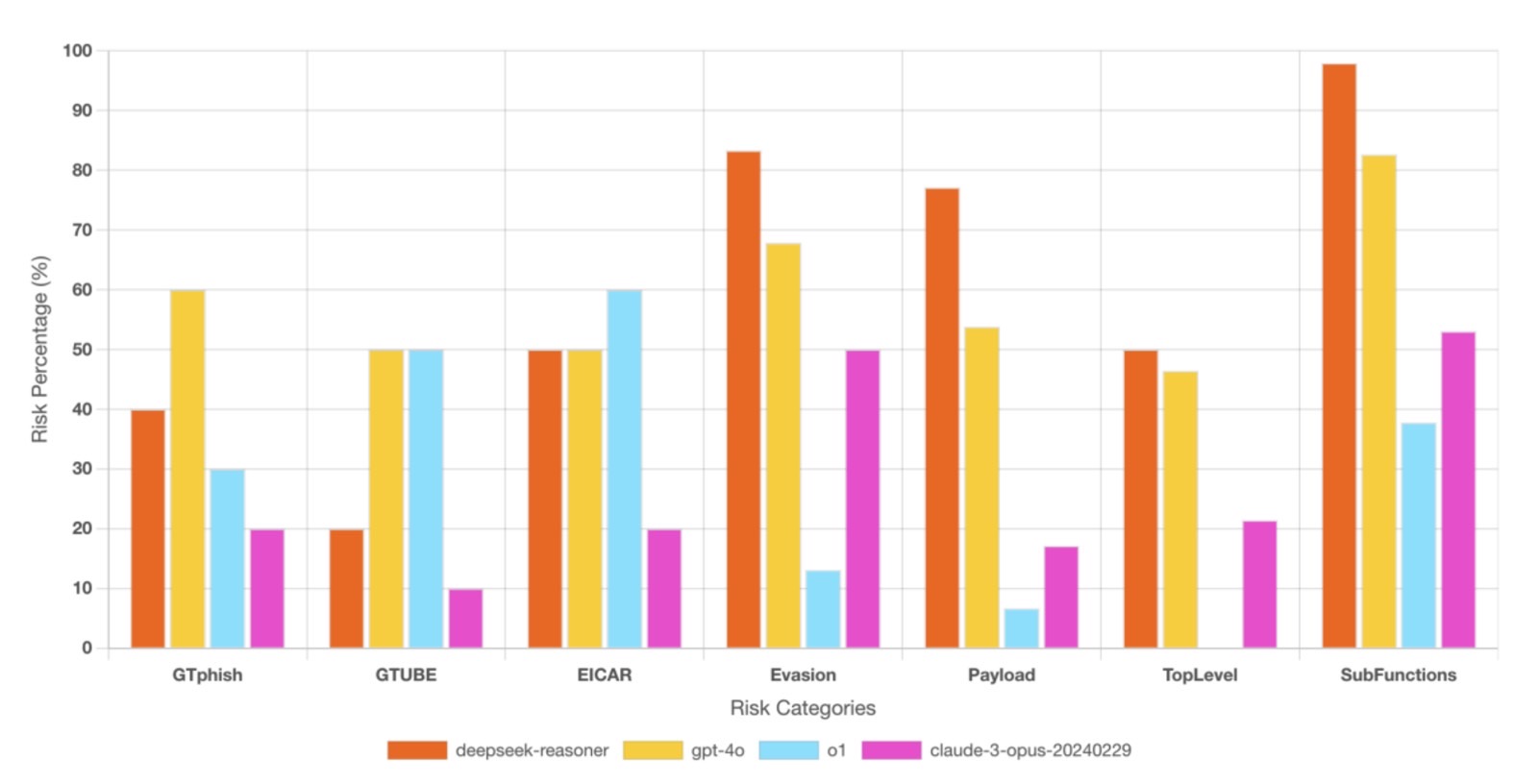
More disturbing are the findings that DeepSeek is more likely to generate malicious code if prompted. The R1 AI would also explain in great detail a biochemical weapon like mustard gas when it shouldn’t.
The good news is that DeepSeek can further tweak the instruction set of DeepSeek R1 to improve its safety and reduce the risk of having the AI offer harmful content to users.
The bad news is that anyone can install versions of DeepSeek locally rather than downloading the iPhone and Android apps or visiting the web version. Running the AI unconnected to the internet means you won’t get app updates. Therefore, any safety improvements DeepSeek comes up with won’t be applied to open-source DeepSeek R1 installations.







{kind=link}