
Over the last year, every conversation about compute seems to orbit around GPUs, model sizes, and training runs. But underneath all of that hype sits something much less glamorous and far more painful: the physical reality of building and operating AI-dense infrastructure.
Many organizations are discovering this the hard way. You can buy racks of accelerators, but unless the entire power, cooling, and networking stack is prepared, those boxes turn into very expensive space heaters. I’ve seen deployments stall for weeks, not because of software issues, but because the data center simply wasn’t designed for the thermal and electrical footprint of current-generation accelerators.
This article is my attempt to lay out the “real stuff” behind AI infrastructure, not the glossy diagrams vendors publish, but the engineering constraints practitioners actually deal with.
Why AI Workloads Break Traditional Data Centers
A typical enterprise rack, say, with 10–15 kW of draw, has a pretty predictable thermal profile. Even if the servers are busy, the airflow, PDUs, and breakers rarely get pushed to their limits.
Accelerator racks are an entirely different animal.
- 40–60 kW per rack is increasingly normal.
- Liquid cooling becomes mandatory above ~35 kW.
- Traditional cold-aisle/hot-aisle designs buckle under GPU thermals.
Organizations often assume they can “just drop” AI racks into an existing row. The reality: you usually need to reorganize the entire power distribution path from the utility all the way down to the rack manifolds.
Power Becomes the First Constraint (Not GPUs)
A single rack of 8–16 accelerators easily pulls more sustained power than five or six traditional racks combined. And unlike CPU workloads, AI workloads run at high utilization for long windows, hours, or sometimes days.
That continuous load exposes weaknesses that normal enterprise systems can hide:
- UPS segments that were never meant to run at 90%+ sustained load
- PDUs that technically “support” the amperage but run hot near the limit
- Breakers derating under thermal stress
- Redundant paths that aren’t truly redundant once everything is under load
The number of AI deployments that accidentally overload a single PDU or UPS segment is surprisingly high.
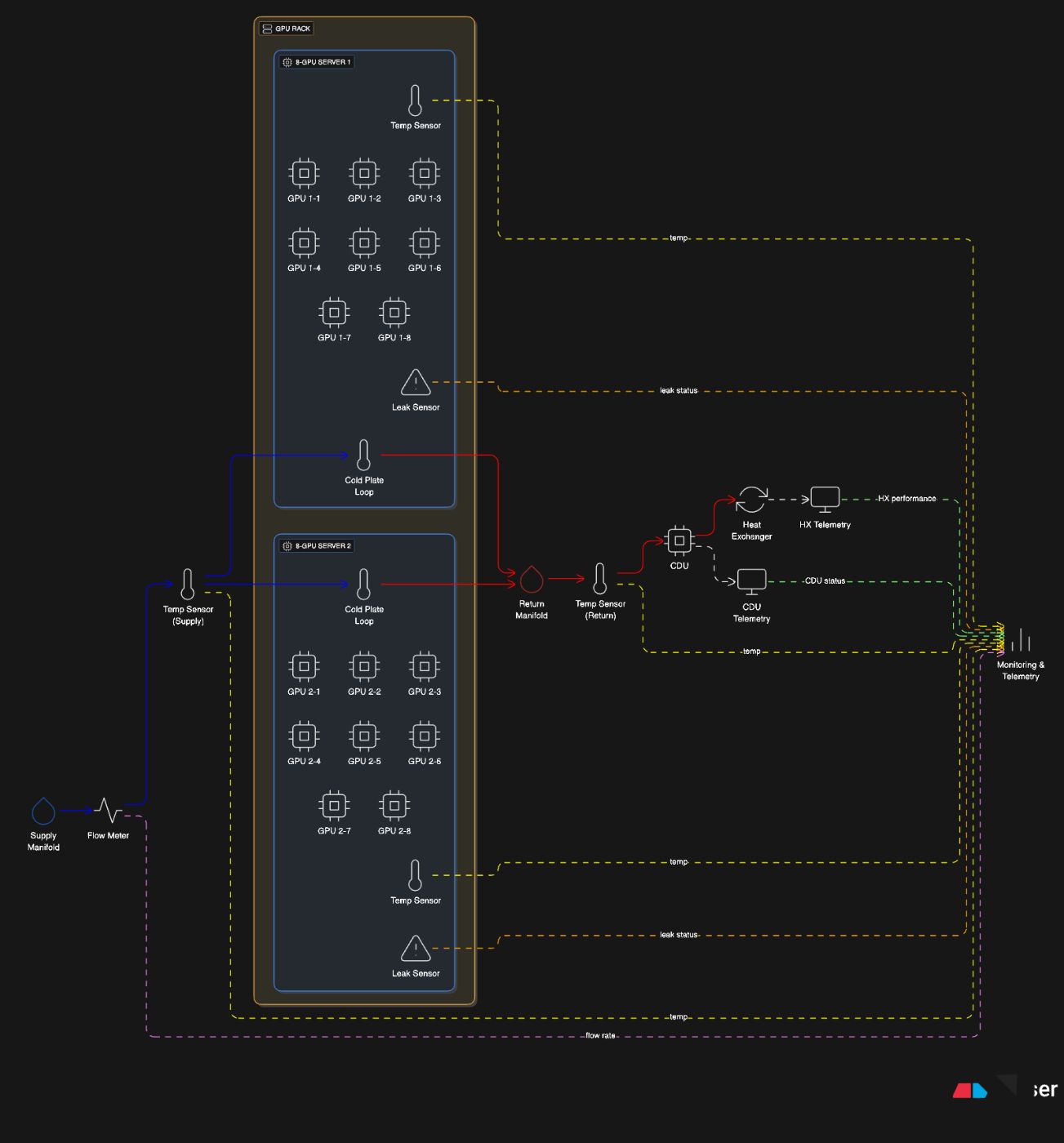
Cooling: The Part Nobody Wants to Talk About
When a rack crosses 40 kW, air cooling basically gives up. In practice, you need direct-to-chip cold plates, backed by CDU (coolant distribution units), heat exchangers, and telemetry.
This part of AI infrastructure feels more like industrial engineering than traditional IT:
- Supply and return coolant lines
- Flow meters and leak detection
- Per-rack manifolds
- Rack-level CDUs feeding GPU loops
- Temperature delta monitoring at multiple points
And unlike power systems, cooling issues tend to appear suddenly. A small bubble in a coolant line can cause temperatures to spike in under a minute.
Networking: The Hidden Complexity Behind Training Clusters
People talk a lot about GPU interconnects (NVLink, xGMI, Infinity Fabric), but when you move beyond a few nodes, the network fabric becomes the real control point.
In most GPU clusters:
- Training traffic is east-west heavy.
- Lossless or near-lossless fabrics are required (RoCEv2 or IB).
- Switch buffering and QoS settings matter more than raw bandwidth.
- Oversubscription is a silent killer for multi-node jobs.
Good fabrics are expensive and operationally fragile. But bad fabrics cause intermittent training slowdowns that are nearly impossible to debug.
Scaling Beyond One Pod
Real AI deployments scale in “pods”: 128, 256, or 512 GPUs tightly interconnected. Connecting pods together introduces a new problem—network islands.
You can scale out, but if the inter-pod fabric isn’t carefully engineered, training workloads end up bottlenecked on a handful of uplinks.
This is where many organizations hit their second wall: the jump from “one pod works” to “three pods work as one cluster” is not linear. It is closer to exponential in complexity.
Practical Advice for Teams Building AI Infrastructure
If you’re designing your first or second AI-dense deployment, here are a few guidelines that come from painful experience:
- Never mix AI racks and traditional racks on the same PDU segment.
- Always oversize your cooling capacity by 20–25%. You will need it.
- Avoid cross-pod network dependencies unless absolutely necessary.
- Deploy monitoring before deploying hardware.
- Run stress tests with real GPU loads before you declare the environment “ready.”
I’ve seen facilities that passed every standard acceptance test fail within 45 minutes of starting an actual training run.
Final Thoughts
It’s easy to get drawn into the software excitement of AI, new models, new frameworks, and new papers every week. But the physical layer beneath all of this is what allows these systems to exist at scale.
If you’re building AI infrastructure, you are part of a field being reinvented in real time. The conversations today feel a lot like early cloud computing: chaotic, experimental, and full of unknowns. But the teams that take physical engineering seriously are the ones who actually ship.






{kind=link}