
Table of Links
Abstract and 1. Introduction
-
Related Work and Background
-
Analysis
3.1 Limitations about Existing ReLUficatio
3.2 dReLU
-
Are Neurons in Expert still Sparsely Activated?
-
dReLU Sparsification
-
Experiments Results
6.1 Downstream Tasks Performance
6.2 Sparsity of Sparsified Models
-
Practical Inference Speedup Evaluation
7.1 Experiments Setting
7.2 Pure CPU Inference and 7.3 Hybrid GPU-CPU Inference
7.4 Deploy LLMs on mobile phones
-
Conclusion and References
A. Appendix / supplemental material
B. Limitation
C. Broader Impact
5 dReLU Sparsification
In the previous section, we have demonstrated that dReLU can be a better choice for ReLUfication. The main question now is whether dReLU based ReLUfication can recover the original model’s performance while achieving higher sparsity. The following sections will discuss the experiments that aimed at answering this question.
Experimental setup. We consider two representative models: Mistral-7B and Mixtral-47B. We substitute the original SwiGLU based FFN with dReLU based FFN and then continue pretraining.
Pretraining datasets. Due to the ReLUfication process, the restoration of model capability is closely related to the corpus used for recovery training. We collected as much corpus as possible from the open-source community for training, such as Wanjuan-CC [48], open-web-math [46], peS2o [54], Pile [19], The Stack [28], GitHub Code [1] and so on. The detailed mixture ratio is as shown in the following table 4:
SFT datasets. After pretraining, we utilize the high-quality SFT datasets to further improve our model’s performance, including orca-math-word-problems [43], bagel [27].
Hyper-parameters. The hyperparameters for our ReLUfication are based on empirical results from previous works [69]. We utilize the llm-foundry framework for training [44] and employ FSDP parallelism.
Our models are trained using the AdamW optimizer [38] with the following hyper-parameters: β1 = 0.9 and β2 = 0.95. We adopt a cosine learning rate schedule and use the default values for weight decay and gradient clipping (see Table 5 for more details). In total, we pretrain our models on 150B tokens.
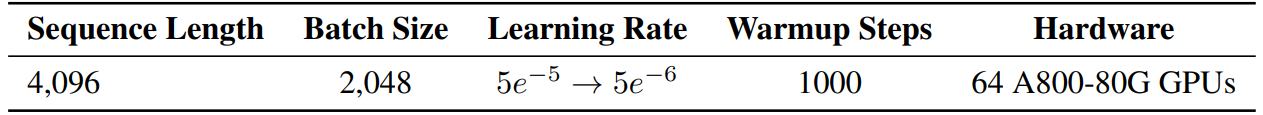
:::info
Authors:
(1) Yixin Song, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(2) Haotong Xie, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(3) Zhengyan Zhang, Department of Computer Science and Technology, Tsinghua University;
(4) Bo Wen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(5) Li Ma, Shanghai Artificial Intelligence Laboratory;
(6) Zeyu Mi, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University Mi [email protected]);
(7) Haibo Chen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University.
:::
:::info
This paper is available on arxiv under CC BY 4.0 license.
:::







{kind=link}