Table of Links
- Abstract and Introduction
- Backgrounds
- Type of remote sensing sensor data
- Benchmark remote sensing datasets for evaluating learning models
- Evaluation metrics for few-shot remote sensing
- Recent few-shot learning techniques in remote sensing
- Few-shot based object detection and segmentation in remote sensing
- Discussions
- Numerical experimentation of few-shot classification on UAV-based dataset
- Explainable AI (XAI) in Remote Sensing
- Conclusions and Future Directions
- Acknowledgements, Declarations, and References
2 Backgrounds
Few-shot learning (FSL) is an emerging approach in the field of machine learning that allows models to acquire knowledge and make accurate predictions with limited training examples per class or context in a specific problem domain. In contrast to conventional machine learning techniques that demand vast quantities of training data, FSL aims to achieve comparable levels of performance using substantially fewer training examples. This ability to learn from scarce data makes FSL well-suited for applications where gathering sizable training sets may be prohibitively expensive or otherwise infeasible.
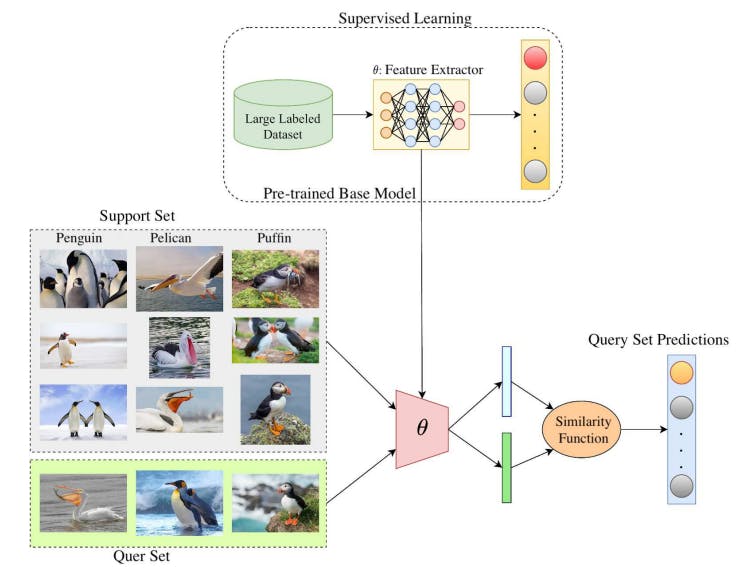
In traditional machine learning, models are trained from scratch on large labeled datasets. In contrast, FSL aims to learn new concepts from just a few examples, leveraging transfer learning from models pre-trained on other tasks. First, a base model is pretrained on a large dataset for a task like image classification. This provides the model with general feature representations that can be transferred. Then for the new few-shot task, the pretrained model is used as a starting point. The support set of few labeled examples for the new classes is used to fine-tune the pretrained model. Typically only the last layer is retrained to adapt the model to the new classes, in order to leverage the pre-learned features. Finally, the adapted model is evaluated on the query set. The query set contains unlabeled examples that the model must make predictions for, based on the patterns learned from the small support set for each new class. This tests how well the model can generalize to new examples of the classes after adapting with only a few shots. To get a clearer view, this whole process is illustrated in Figure 3.


Approaches in FSL classification can often be categorized based on the number of novel categories needed for generalization, referred to as N, as well as the number of labeled samples or classes available in the support set for each of the N novel classes, referred to as k. Generally, a lower value of k makes it more challenging for the few-shot model to achieve high classification accuracy, as there is less supporting information in the support set to aid the model in making accurate predictions. This scheme is commonly referred to as ‘N-way k-shot learning scheme.’ In instances where k equals 1, such schemes are often referred to as one-shot learning. Additionally, in instances where k equals 0, such schemes are often referred to as zero-shot learning.
Initial exploration of FSL in conjunction with unmanned aerial vehicle (UAV)-based thermal imagery was undertaken by [10, 11]. Their pioneering work demonstrated the potential of FSL for UAV-based tasks where limited onboard computational resources impose stringent constraints on model complexity and training data volume. The primary goal of FSL is to construct models that can identify latent patterns within a certain field using limited training examples, then utilize this learned knowledge to effectively categorize and classify new input. This capability closely mirrors human learning, where people can often understand the core of a new concept from just one or two examples. By reducing reliance on extensive training sets, FSL facilitates the development of machine learning systems applicable to data-scarce real-world problems across a broad range of domains.

![Fig. 4 (Left) Similarity function as applied to each pair of images in the AIDER dataset [12]. The image on the left and middle constitute a fire disaster class, and the image on the right is a non-disaster class (normal). (Right) A query image of the flood disaster class is compared with the images from the support set via the similarity function and a correct class prediction is made based on the similarity score. In this case the flood disaster class is correctly predicted and classified.](https://hackernoon.imgix.net/images/null-st134lt.png?auto=format&fit=max&w=1920)
2.1 Similarity Functions for Few-Shot Learning
A similarity function is a critical component of linking the support set and query set in few-shot learning. An example in the context of aerial disaster scene classification using the AIDER dataset [12] is illustrated in Figure 4. The left side of the figure shows how the similarity function evaluation is performed between each pair of images, with the left and middle images representing a fire disaster class and the right image representing a non-disaster class (or normal class). The right side of the figure shows how the similarity function can be used in conjunction with a query image and those from the support set to make a prediction on the correct class (flood) based on the similarity scores.
In few-shot learning, the choice of loss function is critical for enabling effective generalization from limited examples. Some commonly used loss functions include triplet loss, contrastive loss, and cross-entropy loss. The triplet loss helps models learn useful feature representations by minimizing the distance between a reference sample and a positive sample of the same class, while maximizing the distance to a negative sample from a different class. This allows fine-grained discrimination between classes. Contrastive loss is useful for training encoders to capture semantic similarity between augmented views of the same example. This improves robustness to input variations. Cross-entropy loss is commonly used for classifier training in few-shot models, enabling efficient learning from scarce labeled data. However, it can suffer from overfitting due to limited examples. Regularization methods such as label smoothing can help mitigate this. Other advanced losses like meta-learning losses based on model parameters have shown promise for fast adaptation in few-shot tasks. Overall, the choice of loss function plays a key role in addressing critical few-shot learning challenges like overfitting, feature representation learning, and fast generalization. Further research on specialized losses could continue improving few-shot performance
For the scenario depicted on the left side of Figure 4, the triplet loss Ltriplet [13] is an example of a similarity function that could be used. The triplet loss involves comparing an anchor sample class to a positive sample class and a negative sample class. The goal is to minimize the Euclidean distance between the anchor and the positive class based on the similarity function f and maximize the distance between the anchor and the negative class. This can be summarized mathematically in equation 1 as


In equation 1, the anchor, positive, and negative class samples are denoted as a, p, and n, respectively. The index i refers to the input sample index, N denotes the total number of samples in the dataset, and α is a bias term acting as a threshold. The subscript 2 indicates that the evaluated Euclidean distance is the L2 loss, and the superscript 2 corresponds to squaring each parenthesis. The second term with a negative sign allows the maximization of the distance between the anchor and the negative class sample.
Networks that use the triplet loss for few-shot learning are also referred to as triplet networks. On the other hand, for comparing pairs of images, Siamese networks are commonly used. In such cases, the contrastive loss function Lcontrastive [14] can be a better choice for defining similarity or loss, although the triplet loss can also be employed. The contrastive loss can be expressed mathematically as shown in equation 2:


In equation 2, y denotes whether two data points, x1 and x2, within a given set i, are similar (y = 0) or dissimilar (y = 1). The margin term m is user-defined, while DW is the similarity metric, which is given by:


Similarly to the previous method, the L2 loss-based Euclidean distance is used, where the first term in equation 3 corresponds to similar data points and the second term corresponds to dissimilar ones.
The third type of network for Few-Shot Learning can be realized as a prototypical network, as introduced by Snell et al. [15]. This method utilizes an embedding space in which samples from the same class are clustered together. In Figure 3, an example is provided to demonstrate this concept. For each cluster, a typical class prototype is computed as the mean of the data points in that group. The calculation of the class prototype can be expressed mathematically as shown in equation 4:


The prototypical network and Siamese or triplet networks are different few-shot learning approaches that compare query and support samples in different ways. While Siamese or triplet networks directly compare query and support samples in pairs or triplets, the prototypical network compares the query samples with the mean of their support set. This is achieved by calculating the prototype representation of each class in the embedded metric space, which is the average of the feature vectors of all the support samples for that class. This can be visualized in Figure 5. However, for one-shot learning, where only a single support sample is available for each class, the three approaches become equivalent, as the prototype representation becomes identical to the support sample representation. Overall, the choice of few-shot learning approach may depend on the dataset’s specific characteristics and the available support samples.


2.2 Importance of explainable AI in remote sensing
Remote sensing and analysis of satellite imagery has progressed rapidly thanks to artificial intelligence and machine learning. Machine learning models can identify objects and patterns in huge amounts of satellite data with incredible accuracy, surpassing human capabilities. However, these complex machine learning models are often considered ”black boxes” – they provide highly accurate predictions and detections but it is unclear why they make those predictions.
Explainable AI is an emerging field of study focused on making machine learning models and their predictions more transparent and understandable to humans. Explainable AI techniques are essential for applications like remote sensing where decisions could have serious real-world consequences [16]. For example, a machine learning model that detects signs of natural disasters like wildfires in satellite images needs to provide an explanation for its predictions so that human operators can verify the findings before taking action. There are several approaches to making machine learning models used for remote sensing more explainable.
• Highlighting important features: Techniques like saliency maps can highlight the most important parts of an image for a machine learning model’s prediction. For example, computer vision models could highlight the features they use to detect objects in satellite images, allowing correction of errors. Similarly, anomaly detection models could point to regions that led them to flag unusual activity, enabling verification of true positives versus false alarms.
• Simplifying complex models: Complex machine learning models can be converted into simplified explanations that humans can understand, like logical rules and decision trees. For instance, deep reinforcement learning policies for navigating satellites could be expressed as a simplified set of ifthen rules, revealing any flawed assumptions. These simplified explanations make the sophisticated capabilities of machine learning more accessible to domain experts.
• Varying inputs to understand responses: Another explainable AI technique is to systematically vary inputs to a machine learning model and observe how its outputs change in response. For example, generative models that create new realistic satellite images could be evaluated by generating images with different attributes to determine their capabilities and limitations. Analyzing how a model’s predictions vary based on changes to its inputs provides insights into how it works and when it may produce unreliable results.
Overall, explainable AI has the potential to build trust in machine learning systems and empower humans to make the best use of AI for applications like remote sensing. Making machine learning models explainable also allows domain experts to provide feedback that can improve the models. For example, experts in remote sensing may notice biases or errors in a machine learning model’s explanations that could lead the model astray. By providing this feedback, the experts can help data scientists refine and retrain the machine learning model to avoid those issues going forward.
In short, explainable AI has significant promise for enabling machine learning and remote sensing to work together effectively. By making machine learning models and predictions transparent, explainable AI allows:
• Humans to verify and trust the outputs of machine learning models before taking consequential actions based on them.
• Domain experts to provide feedback that improves machine learning models and avoids potential issues.
• A better understanding of the strengths, weaknesses and limitations of machine learning that can guide how the technology is developed and applied in remote sensing.
Explainable AI will be key to ensuring machine learning is used responsibly and to its full potential for remote sensing and beyond. Building partnerships between humans and AI can lead to a future with technology that enhances human capabilities rather than replacing them.
Authors:
(1) Gao Yu Lee, School of Electrical and Electronic Engineering, Nanyang Technological University, 50 Nanyang Ave, 639798, Singapore ([email protected]);
(2) Tanmoy Dam, School of Mechanical and Aerospace Engineering, Nanyang Technological University, 65 Nanyang Drive, 637460, Singapore and Department of Computer Science, The University of New Orleans, New Orleans, 2000 Lakeshore Drive, LA 70148, USA ([email protected]);
(3) Md Meftahul Ferdaus, School of Electrical and Electronic Engineering, Nanyang Technological University, 50 Nanyang Ave, 639798, Singapore ([email protected]);
(4) Daniel Puiu Poenar, School of Electrical and Electronic Engineering, Nanyang Technological University, 50 Nanyang Ave, 639798, Singapore ([email protected]);
(5) Vu N. Duong, School of Mechanical and Aerospace Engineering, Nanyang Technological University, 65 Nanyang Drive, 637460, Singapore ([email protected]).







{kind=link}