Robert Triggs / Android Authority
Another day, another large language model, but news that OpenAI has released its first open-weight models (gpt-oss) with Apache 2.0 licensing is a bigger deal than most. Finally, you can run a version of ChatGPT offline and for free, giving developers and us casual AI enthusiasts another powerful tool to try out.
As usual, OpenAI makes some pretty big claims about gpt-oss’s capabilities. The model can apparently outperform o4-mini and scores quite close to its o3 model — OpenAI’s cost-efficient and most powerful reasoning models, respectively. However, that gpt-oss model comes in at a colossal 120 billion parameters, requiring some serious computing kit to run. For you and me, though, there’s still a highly performant 20 billion parameter model available.
Can you now run ChatGPT offline and for free? Well, it depends.
In theory, the 20 billion parameter model will run on a modern laptop or PC, provided you have bountiful RAM and a powerful CPU or GPU to crunch the numbers. Qualcomm even claims it’s excited about bringing gpt-oss to its compute platforms — think PC rather than mobile. Still, this does beg the question: Is it possible to now run ChatGPT entirely offline and on-device, for free, on a laptop or even your smartphone? Well, it’s doable, but I wouldn’t recommend it.
What do you need to run gpt-oss?

Edgar Cervantes / Android Authority
Despite shrinking gpt-oss from 120 billion to 20 billion parameters for more general use, the official quantized model still weighs in at a hefty 12.2GB. OpenAI specifies VRAM requirements of 16GB for the 20B model and 80GB for the 120B model. You need a machine capable of holding the entire thing in memory at once to achieve reasonable performance, which puts you firmly into NVIDIA RTX 4080 territory for sufficient dedicated GPU memory — hardly something we all have access to.
For PCs with a smaller GPU VRAM, you’ll want 16GB of system RAM if you can split some of the model into GPU memory, and preferably a GPU capable of crunching FP4 precision data. For everything else, such as typical laptops and smartphones, 16GB is really cutting it fine as you need room for the OS and apps too. Based on my experience, 24GB RAM is required; my 7th Gen Surface Laptop, complete with a Snapdragon X processor and 16GB RAM, worked at an admittedly pretty decent 10 tokens per second, but barely held on even with every other application closed.
Despite it’s smaller size, gpt-oss 20b still needs plenty of RAM and a powerful GPU to run smoothly.
Of course, with 24 GB RAM being ideal, the vast majority of smartphones cannot run it. Even AI leaders like the Pixel 9 Pro XL and Galaxy S25 Ultra top out at 16GB RAM, and not all of that’s accessible. Thankfully, my ROG Phone 9 Pro has a colossal 24GB of RAM — enough to get me started.
How to run gpt-oss on a phone

Robert Triggs / Android Authority
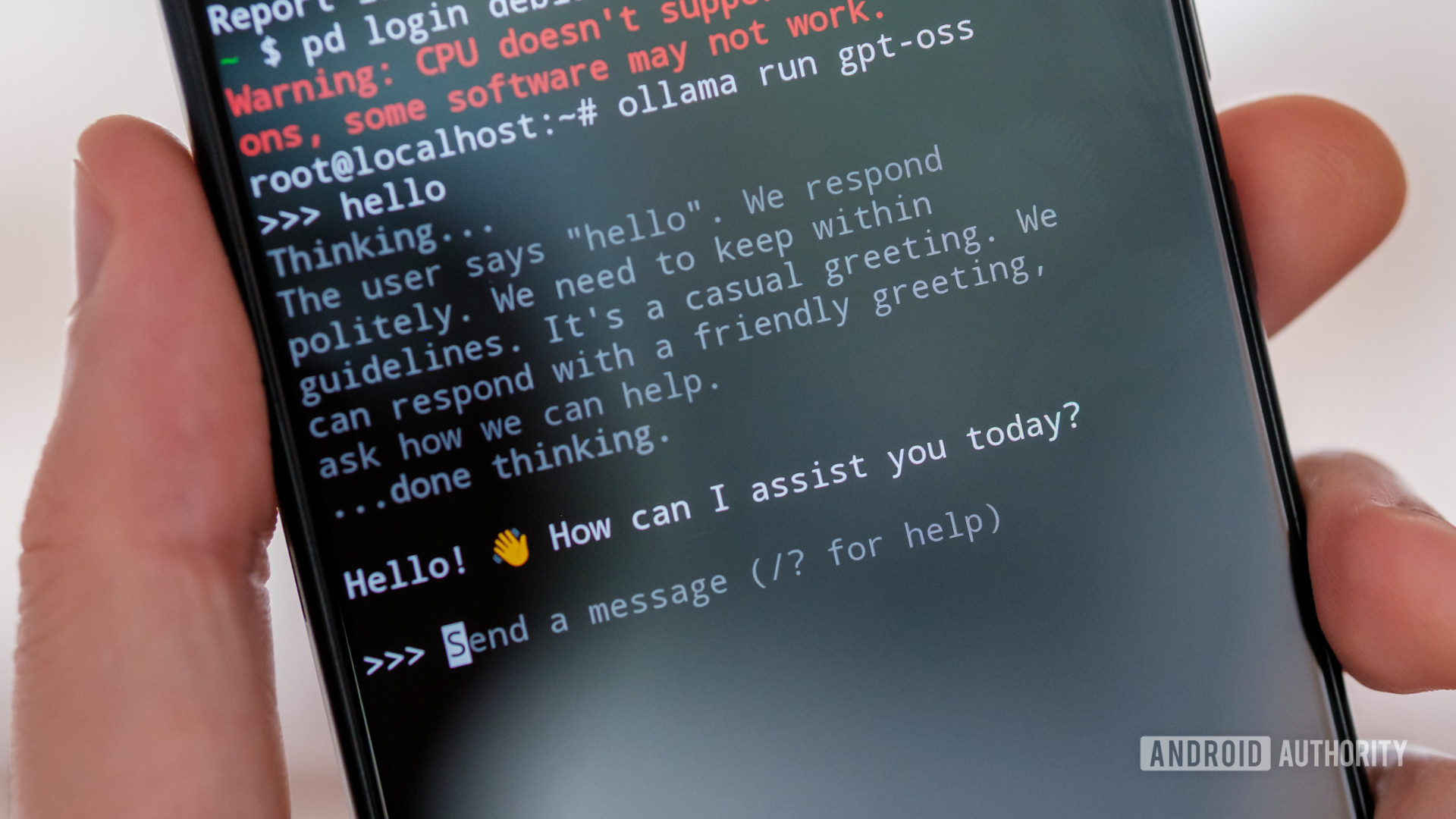
For my first attempt to run gpt-oss on my Android smartphone, I turned to the growing selection of LLM apps that let you run offline models, including PocketPal AI, LLaMA Chat, and LM Playground.
However, these apps either didn’t have the model available or couldn’t successfully load the version downloaded manually, possibly because they’re based on an older version of llama.cpp. Instead, I booted up a Debian partition on the ROG and installed Ollama to handle loading and interacting with gpt-oss. If you want to follow the steps, I did the same with DeepSeek earlier in the year. The drawback is that performance isn’t quite native, and there’s no hardware acceleration, meaning you’re reliant on the phone’s CPU to do the heavy lifting.
So, how well does gpt-oss run on a top-tier Android smartphone? Barely is the generous word I’d use. The ROG’s Snapdragon 8 Elite might be powerful, but it’s nowhere near my laptop’s Snapdragon X, let alone a dedicated GPU for data crunching.
gpt-oss can just about run on a phone, but it’s barely usable.
The token rate (the rate at which text is generated on screen) is barely passable and certainly slower than I can read. I’d estimate it’s in the region of 2-3 tokens (about a word or so) per second. It’s not entirely terrible for short requests, but it’s agonising if you want to do anything more complex than say hello. Unfortunately, the token rate only gets worse as the size of your conversation increases, eventually taking several minutes to produce even a couple of paragraphs.

Robert Triggs / Android Authority
Obviously, mobile CPUs really aren’t built for this type of work, and certainly not models approaching this size. The ROG is a nippy performer for my daily workloads, but it was maxed out here, causing seven of the eight CPU cores to run at 100% almost constantly, resulting in a rather uncomfortably hot handset after just a few minutes of chat. Clock speeds quickly throttled, causing token speeds to fall further. It’s not great.
With the model loaded, the phone’s 24GB was stretched as well, with the OS, background apps, and additional memory required for the prompt and responses all vying for space. When I needed to flick in and out of apps, I could, but this brought already sluggish token generation to a virtual standstill.
Another impressive model, but not for phones
Calvin Wankhede / Android Authority
Running gpt-oss on your smartphone is pretty much out of the question, even if you have a huge pool of RAM to load it up. External models aimed primarily at the developer community don’t support mobile NPUs and GPUs. The only way around that obstacle is for developers to leverage proprietary SDKs like Qualcomm’s AI SDK or Apple’s Core ML, which won’t happen for this sort of use case.
Still, I was determined not to give up and tried gpt-oss on my aging PC, equipped with a GTX1070 and 24GB RAM. The results were definitely better, at around four to five tokens per second, but still slower than my Snapdragon X laptop running just on the CPU — yikes.
In both cases, the 20b parameter version of gpt-oss certainly seems impressive (after waiting a while), thanks to its configurable chain of reasoning that lets the model “think” for longer to help solve more complex problems. Compared to free options like Google’s Gemini 2.5 Flash, gpt-oss is the more capable problem solver thanks to its use of chain-of-thought, much like DeepSeek R1, which is all the more impressive given it’s free. However, it’s still not as powerful as the mightier and more expensive cloud-based models — and certainly doesn’t run anywhere near as fast on any consumer gadgets I own.
Still, advanced reasoning in the palm of your hand, without the cost, security concerns, or network compromises of today’s subscription models, is the AI future I think laptops and smartphones should truly aim for. There’s clearly a long way to go, especially when it comes to mainstream hardware acceleration, but as models become both smarter and smaller, that future feels increasingly tangible.
A few of my flagship smartphones have proven reasonably adept at running smaller 8 billion parameter models like Qwen 2.5 and Llama 3, with surprisingly quick and powerful results. If we ever see a similarly speedy version of gpt-oss, I’d be much more excited.
Thank you for being part of our community. Read our Comment Policy before posting.







{kind=link}