Table of Links
Abstract and 1 Introduction
2 LongFact: Using LLMs to generate a multi-topic benchmark for long-form factuality
3 Safe:LLM agents as factuality autoraters
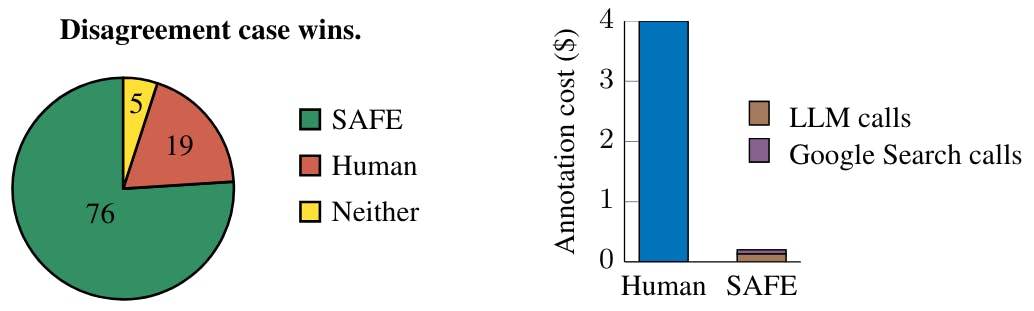
4 LLMs agents can be better factuality annotators than humans
5 F1@k: Extending F1 with recall from human-preferred length
6 Larger LLMs are more factual
7 Related Work
8 Limitations
9 Conclusion, Acknowledgments, Author Contribution, and References
Appendix
A. Frequently asked questions
B. LongFact details
C. SAFE details
D. Metric details
E. Further analysis
6 LARGER LLMS ARE MORE FACTUAL
While prior research has attempted to benchmark long-form factuality across language models (Min et al., 2023), our work presents a more-comprehensive dataset, a morescalable evaluation method, and an aggregation metric that considers factual recall. For these reasons, we benchmark thirteen popular large language models across four model families (shown in Table 1)—Gemini models (Gemini Team, 2023), GPT models (OpenAI, 2022; 2023), Claude models (Anthropic, 2023; 2024), and PaLM-2 models (Google, 2023). We evaluate each model on the same random subset of 250 prompts[9]




from LongFact-Objects,[10] and we decode model responses up to 1,024 tokens at a temperature of zero. We then use SAFE to obtain raw evaluation metrics for each model response, which we aggregate using F1@K as described in Section 5 (we selected K = 64, the median number of relevant facts among all model responses for the tested prompts, and K = 178, the maximum number of relevant facts in a response among all model responses for the tested prompts).
As shown in Figure 6 and Table 2, we generally find that larger models achieve better long-form factuality. For example, GPT-4-Turbo is better than GPT-4 which is better than GPT-3.5-Turbo, Gemini-Ultra is more factual than Gemini-Pro, and PaLM-2-L-IT-RLHF is better than PaLM-2-L-IT. We also see that the three most-factual models at both selected K values are GPT-4-Turbo, GeminiUltra, and PaLM-2-L-IT-RLHF, which all seem to correspond to the largest model within their respective families (with respect to some scaling factor, not necessarily the number of parameters). Many models from newer model families such as Gemini, Claude-3-Opus, and Claude-3-Sonnet are able to match or surpass GPT-4 performance, which is not entirely unexpected since GPT-4 (gpt-4-0613) is an older language model. Notably, we found that Claude-3-Sonnet achieves similar long-form factuality as Claude-3-Opus despite being a smaller model, but without access to further details about these models, it is unclear why this was the case. Claude-3-Haiku also has seemingly-low long-form factuality relative to older models within the same family such as Claude-Instant, though this may have been a result of prioritizing factual precision over recall, as shown in Table 2 and further discussed in Appendix E.2. [11] We discuss further insights from these results in Appendix E, including how scaling may impact long-form factuality (Appendix E.2), the effects of Reinforcement Learning from Human Feedback (Appendix E.4), and how rankings can change with respect to the K used for calculating F1@K (Appendix E.3).
[9] To increase prompt difficulty, we added a fixed postamble to every prompt—this postamble asks the model to provide as many specific details as possible. We discuss this postamble further in Appendix A.7.
[10] We excluded LongFact-Concepts for the reasons discussed in Appendix A.8.
[11] As shown in Table 2, factual recall has improved significantly more than factual precision in recent efforts to scale language models.
Authors:
(1) Jerry Wei, Google DeepMind and a Lead contributors;
(2) Chengrun Yang, Google DeepMind and a Lead contributors;
(3) Xinying Song, Google DeepMind and a Lead contributors;
(4) Yifeng Lu, Google DeepMind and a Lead contributors;
(5) Nathan Hu, Google DeepMind and Stanford University;
(6) Jie Huang, Google DeepMind and University of Illinois at Urbana-Champaign;
(7) Dustin Tran, Google DeepMind;
(8) Daiyi Peng, Google DeepMind;
(9) Ruibo Liu, Google DeepMind;
(10) Da Huang, Google DeepMind;
(11) Cosmo Du, Google DeepMind;
(12) Quoc V. Le, Google DeepMind.




{kind=link}