The engineering team at Cloudflare recently shared how they transitioned Quicksilver, their internal global key-value store, to a tiered caching architecture. They described their incremental journey from storing everything everywhere to adopting a distributed caching system, improving storage efficiency while preserving consistency guarantees and low-latency reads at the edge.
Over the last few years, Cloudflare transitioned from what is now called Quicksilver V1, where all data was stored on each server, to a new tiered caching system, Quicksilver V2, where only a handful of servers store data. The two-article series describes how they achieved the tiered caching architecture, a process that required the team to migrate hundreds of thousands of live databases while serving billions of requests per second.
Quicksilver is a key-value store developed internally by Cloudflare to enable fast global replication and low-latency access across its global data centers. Originally designed as a global distribution system for configurations, it has evolved over time into the foundational storage system for many Cloudflare services and products, including their DNS, CDN, and WAF.
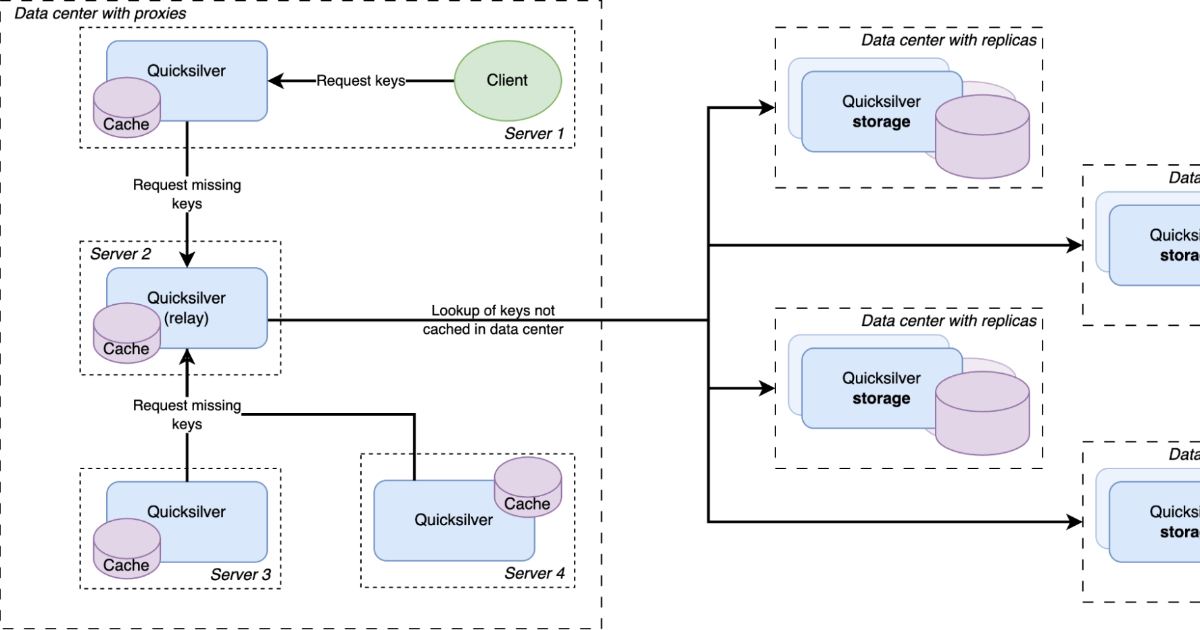
Quicksilver v1 stored the complete dataset on every server globally, resulting in unsustainable disk space usage as the 1.6TB dataset grew by 50% in just one year, threatening to exhaust available storage across Cloudflare’s network. The transition began with Quicksilver v1.5, a solution that introduced proxy and replica server roles, resulting in a 50% reduction in disk usage.
In the latest v2 implementation, Cloudflare introduced a multi-level caching strategy. The newest architecture features local per-server caches, data center-wide sharded caches, and full dataset replicas on specialized storage nodes, with reactive prefetching that distributes cache misses across servers. Memory usage and cold cache concerns led Cloudflare to choose persistent storage using RocksDB over memory-based caching, with evictions based on the engine’s compaction filters.
Source: Cloudflare blog
Anton Dort-Golts and Marten van de Sanden, systems engineers at Cloudflare, explain why backward compatibility and sequential consistency were important:
Quicksilver has, from the start, provided sequential consistency to clients (…) We have experienced Hyrum’s Law first hand, with Quicksilver being so widely adopted across the company that every property we introduced in earlier versions is now relied upon by other teams. This means that changing behaviour would inevitably break existing functionality and introduce bugs.
The new architecture maintains sequential consistency through multiversion concurrency control (MVCC) and sliding window approaches to handle asynchronous replication challenges.

Source: Cloudflare blog
The transformation from the old architecture to Quicksilver v2 addresses the initial critical constraints across Cloudflare’s 330-city network while maintaining sub-millisecond performance for the 1.6TB dataset containing five billion key-value pairs. According to the authors, Quicksilver currently responds to 90% of requests within 1 ms and 99.9% of requests within 7 ms. Most requests return only a few keys, while others return hundreds or even more keys. Dort-Golts and van de Sanden add:
Our key space was split up into multiple shards. Each server in a data center was assigned one of the shards. Instead of those shards containing the full dataset for their part of the key space, they contain a cache for it. Those cache shards are populated by all cache misses inside the data center. This all forms a data center-wide cache that is distributed using sharding.
Cloudflare resolved the data locality issue by maintaining local per-server caches in addition to data center-wide caches, with all servers in a data center containing both their local cache and a cache for one physical shard of the sharded cache. Each requested key is first looked up in the server’s local cache and then in the data center-wide sharded one. If both caches miss the key, the lookup happens on one of the storage nodes. The authors conclude the analysis by sharing the results of having multiple caching layers:
The percentage of keys that can be resolved within a data center improved significantly by adding the second caching layer. The worst performing instance has a cache hit rate higher than 99.99%. All other instances have a cache hit rate that is higher than 99.999%.
The 99.9th percentile latency between proxies and replicas shows virtually no difference, with proxies occasionally outperforming replicas due to smaller on-disk datasets.







{kind=link}