Authors:
(1) Clemencia Siro, University of Amsterdam, Amsterdam, The Netherlands;
(2) Mohammad Aliannejadi, University of Amsterdam, Amsterdam, The Netherlands;
(3) Maarten de Rijke, University of Amsterdam, Amsterdam, The Netherlands.
Table of Links
Abstract and 1 Introduction
2 Methodology and 2.1 Experimental data and tasks
2.2 Automatic generation of diverse dialogue contexts
2.3 Crowdsource experiments
2.4 Experimental conditions
2.5 Participants
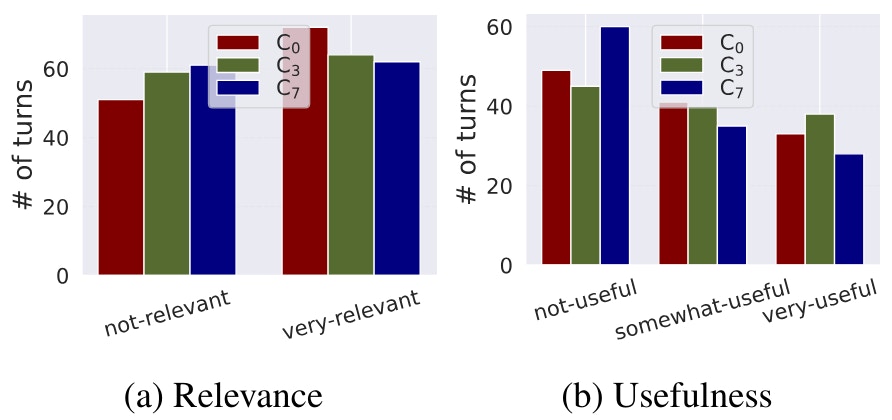
3 Results and Analysis and 3.1 Data statistics
3.2 RQ1: Effect of varying amount of dialogue context
3.3 RQ2: Effect of automatically generated dialogue context
4 Discussion and Implications
5 Related Work
6 Conclusion, Limitations, and Ethical Considerations
7 Acknowledgements and References
A. Appendix
2.3 Crowdsource experiments
Following (Kazai, 2011; Kazai et al., 2013; Roitero et al., 2020), we design human intelligence task (HIT) templates to collect relevance and usefulness labels. We deploy the HITs in variable conditions to understand how contextual information affects annotators’ judgments. Our study has two phases: in Phase 1 we vary the amount of contextual information; in Phase 2 we vary the type of contextual information. In each phase and condition, the annotators were paid the same amount as this study is not focused on understanding how incentive influences the quality of crowdsourced labels. Like (Kazai et al., 2013), we refrain from disclosing the research angle to the annotators in both phases; this helps prevent potential biases during the completion of the HIT.
Phase 1. In Phase 1, the focus is on understanding how the amount of dialogue context impacts the quality and consistency of relevance and usefulness labels. We vary the length of the dialogue context to address (RQ1). Thus, we design our experiment with three variations: C0, C3, and C7 (see Section 2.4). The HIT consists of a general task description, instructions, examples, and the main task part. For each variation, we gather labels for two main dimensions (relevance and usefulness) and include an open-ended question to solicit annotators’ feedback on the task. Each dimension is assessed with 3 annotators in a separate HIT, with the same system response evaluated by each. This ensures a consistent evaluation process for both relevance and usefulness.
Phase 2. In Phase 2, the focus shifts to the type of contextual information, to answer (RQ2). We take an approach of machine in the loop for crowdsourcing. We restrict our experiments to experimental variation C0 (defined below), where no previous dialogue context is available to the annotators. We aim to enhance the quality of crowdsourced labels for C0 by including additional contextual information alongside the turn being evaluated. Our hypothesis is that without prior context, annotators may face challenges in providing accurate and consistent labels. By introducing additional context, like the user’s information need or a dialogue summary, we expect an increase in the accuracy of evaluations. Through this, we aim to approach a level of performance similar to when annotators have access to the entire dialogue context while minimizing the annotation effort required. We enhance the 40 dialogues from Phase 1 with the user’s information need or a dialogue summary, as detailed in Section 2.2. Thus, in Phase 2, we have three experimental setups: C0-llm, C0-heu, and C0-sum. Table 3 in Section A.1 summarizes the setups.
The HIT design closely mirrors that of Phase 1. The main task remains unchanged, except for the inclusion of the user’s information need or a dialogue summary. Annotators answer the same two questions on relevance and usefulness in separate HITs. While we do not strictly enforce reliance on the additional information provided, annotators are encouraged to use it when they perceive that the current response lacks sufficient information for an informed judgment.
2.4 Experimental conditions
We focus on two key attributes: the amount and type of dialogue context. For both attributes, we explore three distinct settings, resulting in 6 variations, for both relevance and usefulness; each was applied to the same 40 dialogues:
• Amount of context. We explore three truncation strategies: no-context (C0), partial context (C3), and full context (C7), designed to encompass scenarios where no previous dialogue context is accessible to the annotator (C0), where some previous dialogue context is available but not comprehensively (C3), and when annotators have access to the complete previous dialogue context (C7).
• Type of context. Using the contexts generated in Section 2.2, we experiment with three variations of context type: heuristically generated information need (C0-heu), an LLM-generated information need (C0-llm), and dialogue summary (C0-sum).
Table 3 in Section A.1 of the appendix summarizes the experimental conditions.
2.5 Participants
We enlisted master workers from the US on Amazon Mechanical Turk (MTurk) (Amazon Mechanical Turk, 2023) to ensure proficient language understanding. Annotators were filtered based on platform qualifications, requiring a minimum accuracy of 97% across 5000 HITs. To mitigate any learning bias from the task, each annotator was limited to completing 10 HITs per batch and participating in a maximum of 3 experimental conditions. A total of 78 unique annotators took part in Phases 1 and 2 and each worker was paid $0.4 per HIT, an average of $14 per hour. Their average age range was 35–44 years. The gender distribution was 46% female and 54% male. The majority held a four-year undergraduate degree (48%), followed by two-year and master’s degrees (15% and 14%, respectively).
We conduct quality control on the crowdsourced labels to ensure reliability as described in Section A.2 in the appendix.







{kind=link}