Table of Links
Abstract and 1. Introduction
2 Concepts in Pretraining Data and Quantifying Frequency
3 Comparing Pretraining Frequency & “Zero-Shot” Performance and 3.1 Experimental Setup
3.2 Result: Pretraining Frequency is Predictive of “Zero-Shot” Performance
4 Stress-Testing the Concept Frequency-Performance Scaling Trend and 4.1 Controlling for Similar Samples in Pretraining and Downstream Data
4.2 Testing Generalization to Purely Synthetic Concept and Data Distributions
5 Additional Insights from Pretraining Concept Frequencies
6 Testing the Tail: Let It Wag!
7 Related Work
8 Conclusions and Open Problems, Acknowledgements, and References
Part I
Appendix
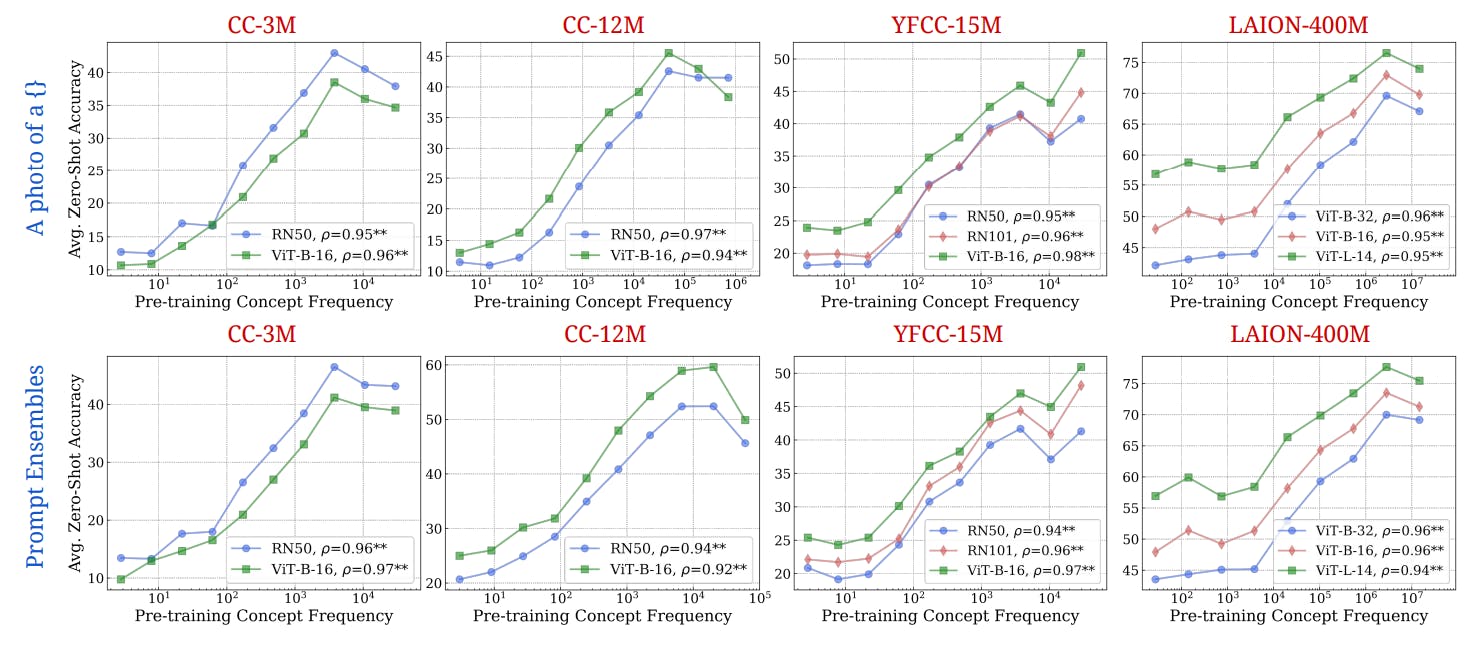
A. Concept Frequency is Predictive of Performance Across Prompting Strategies
B. Concept Frequency is Predictive of Performance Across Retrieval Metrics
C. Concept Frequency is Predictive of Performance for T2I Models
D. Concept Frequency is Predictive of Performance across Concepts only from Image and Text Domains
E. Experimental Details
F. Why and How Do We Use RAM++?
G. Details about Misalignment Degree Results
H. T2I Models: Evaluation
I. Classification Results: Let It Wag!
Effect of Pre-training Data on Downstream Data. Several data-centric prior works [91, 46, 82, 42, 83, 74, 124, 125, 135, 109, 78, 92, 99, 100, 38, 26, 95] have highlighted the importance of pretraining data in affecting performance. Fang et al. [42] robustly demonstrated that pretraining data diversity is the key property underlying CLIP’s strong out-of-distribution generalisation behaviour. Similarly, Berlot-Attwell et al. [16] showed that attribute diversity is crucial for compositional generalization [60], namely systematicity [45]. Nguyen et al. [82] extended the Fang et al. [42] analysis to show that differences in data distributions can predictably change model performance, and that this behaviour can lead to effective data mixing strategies at pretraining time. Mayilvahanan et al. [79] complemented this research direction by showing that CLIP’s performance is correlated with the similarity between training and test datasets. Udandarao et al. [118] further showed that the frequency of certain visual data-types in the LAION-2B dataset was roughly correlated to the performance of CLIP models in identifying visual data-types. Our findings further pinpoint that the frequency of concept occurrences is a key indicator of performance. This complements existing research in specific areas like question-answering [62] and numerical reasoning [94] in large language models, where high train-test set similarity does not fully account for observed performance levels [127]. Concurrent to our work, Parashar et al. [86] also explore the problem of long-tailed concepts in the LAION-2B dataset and how it affects performance of CLIP models, supporting our findings. In contrast to their work, we look at count separately in image and text modalities, as well as across pretraining sets, and do a number of control experiments to thoroughly test the robustness of our result. Finally, our demonstration that the long tail yields a log-linear trend explicitly indicates exponential sample inefficiency in large-scale pretrained models.
Data-centric analyses. Our work also adds to the plethora of work that aims to understand and explore the composition of large-scale datasets, and uses data as a medium for improving downstream tasks. Prior work has noted the importance of data for improving model performance on a generalised set of tasks [46, 11, 40, 13, 106]. For instance, several works utilise retrieved and synthetic data for adapting foundation models on a broad set of downstream tasks [119, 54, 115, 21, 101, 134, 90]. Maini et al. [76] observed the existence of “textcentric” clusters in LAION-2B and measured its impact on downstream performance. Other work has seeked to target the misalignment problem that we quantified in Tab. 3 by explicit recaptioning of pretraining datasets [68, 28, 120, 131, 83, 17]. Further, studies have also shown that by better data pruning strategies, neural scaling laws can be made more efficient than a power-law [109, 10]. Prior work has also showcased that large-scale datasets suffer from extreme redundancy in concepts, and high degrees of toxic and biased content [39, 116]. Further research has showcased the downstream effects that such biases during pretraining induce in state-of-the art models [19, 104, 18, 47]. Our work tackles the issue of long-tailed concepts in pretraining datasets, and shows that this is an important research direction to focus efforts on.
Authors:
(1) Vishaal Udandarao, Tubingen AI Center, University of Tubingen, University of Cambridge, and equal contribution;
(2) Ameya Prabhu, Tubingen AI Center, University of Tubingen, University of Oxford, and equal contribution;
(3) Adhiraj Ghosh, Tubingen AI Center, University of Tubingen;
(4) Yash Sharma, Tubingen AI Center, University of Tubingen;
(5) Philip H.S. Torr, University of Oxford;
(6) Adel Bibi, University of Oxford;
(7) Samuel Albanie, University of Cambridge and equal advising, order decided by a coin flip;
(8) Matthias Bethge, Tubingen AI Center, University of Tubingen and equal advising, order decided by a coin flip.






{kind=link}