
Last November, we argued that JPMorgan Chase & Co. Chief Executive Jamie Dimon is sitting on a treasure trove of unique data that will never find its way into proprietary large language models via the internet. And as such, he was OpenAI CEO Sam Altman’s biggest competitor because his data is more valuable than the democratized insights from these LLMs.
Our premise was and continues to be that foundation model companies are waging an internecine battle chasing artificial general intelligence (“Messiah AGI”) and the true holy grail is what we called “enterprise AGI” — meaning applying AI to proprietary data inside of enterprises will ultimately prove to be the most valuable economic endeavor. Today we extend that argument and posit that agents and enterprise digital twins, powered by that proprietary data, will drive the next wave of AI value.
In our previous “Jamie Dimon” episode, we set a framework for the why. In this Breaking Analysis, we explain how enterprises such as JPMC will drive value in a way that frontier model vendors cannot. We’ll examine our original premise and share data that further reinforces the challenges foundation model vendors face, making it a daunting business. Moreover, we’ll explain why agents, programmed by data, will ultimately provide the biggest value unlock for enterprises in the coming years.
The three waves of agents
We think of agent evolution in three distinct waves as shown below:
Consumer agents – ChatGPT in its GPT-3/4 era gave us the first taste of a personal digital assistant. GPT-5 will likely deliver the first general purpose, consumer-grade agent that can act on a user’s behalf, not just chat.
Coding agents – Anthropic’s Claude paired with Cursor shows what happens when you post-train with Reinforcement Learning onto a strong base model and aim it at software engineering. Code is a good proving ground because outcomes are objectively testable, much like math problems.
Enterprise agents – We believe this is the next frontier – i.e. agents powered by a live digital twin of the business. Not digital twins of something physical such as a factory like NVIDIA’s Omniverse, rather an enterprise. Here the landscape changes. It’s not just about bigger models; it’s new vendor tech stacks, new vendor business models, and new customer operating models that we’ll explain. The value is so large that even Jamie Dimon, with his huge balance sheet and orders of magnitude more useful data than frontier labs have access to, is stepping onto Sam Altman’s playing field.
With that framing in place, let’s walk through why the jump from consumer/coder agents to enterprise agents is not a linear extrapolation, and what new technology and organizational layers have to materialize before Jamie Dimon can realistically challenge OpenAI’s lead.
Additional color on the three eras of agentic AI
We make the following additional points on this topic:
Jamie Dimon, as we’ve talked about before, is a proxy for enterprises and the proprietary data and know-how that they have within their four walls that frontier LLMs cannot train on. This is why the real value will come from enterprises applying that data and know-how to extending the frontier LLMs or models that are similar to that and we’ll explain why.
The real revolution is that we’ve moved from scaling laws in the pre-training era—which is the GPT models that ChatGPT and similar products were built on, to the post-training era, which is where we start using reinforcement learning. Reinforcement learning is a fancy term for trial-and-error learning and, for trial-and-error, you have to be able to learn from your mistakes.
- It first works in software-engineering agents because code gives immediate, objective feedback, i.e.:
- You can run a test and see if it works– you can compile it.
- It fits into a programmer’s workflow without huge changes.
So that’s where agents in the enterprise first take off. And then our contention is that to go beyond that is where we’re going to need a new type of technology platform—the enterprise digital twin.
To get real value out of that, we’re going to have to go with a new—not just new technology model at the foundation where the data is—but a new operations model where firms have to organize around end-to-end outcomes like onboarding a new customer, not departmental or functional specialization.
- Vendor implications:
- Vendors must provide end-to-end process-centric data platforms or digital twins. It’s not the conventional data platforms or the siloed applications.
- It appears we’re going to need open-weight models for this trial-and-error learning to work properly, and that’s incompatible with the frontier model vendors’ business models.
As such, we’re going to need lots of changes. And the main point is that Jamie Dimon (as a proxy for leading enterprises) and the value he’s going to extract from this era of AI is going to need completely different scaffolding and sets of business models for customers like him, as well as the vendors that supply him, compared to the era where ChatGPT is creating and capturing value today.
In short, we believe this shift — from pre-training scale to post-training skill, and from siloed workflows to outcome-centric twins — sets the competitive chessboard for the next decade of enterprise AI.
Wave 1: Consumer agents
Let’s drill into the first wave a bit deeper
ChatGPT on GPT3.5 got it all started. but GPT-5 is where we think ChatGPT’s real value as a general-purpose consumer agent begins. OpenAI’s own revenue projection (dotted red line below) climbs from low-single billions in 2024 to >$50 billion by 2027—a growth curve that many people feel threatens Google Search– we’ll see.
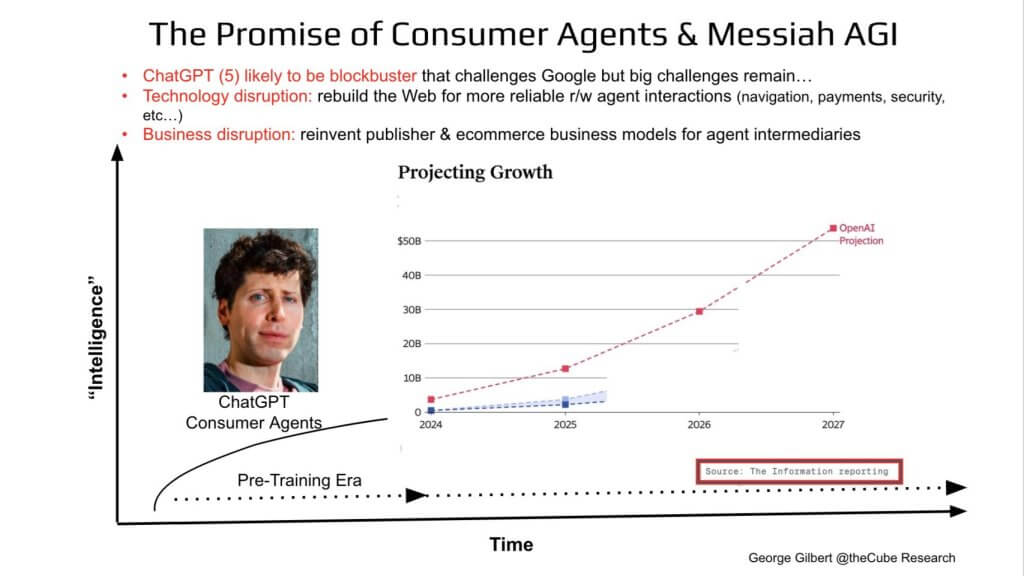
The red call-outs above are instructive as there are caveats, technical rewirings and business model changes that have to fall into place before GPT-5-class agents can move from cool demo to must-have personal assistant. Specifically:
Thirty years ago investors hailed the commercial Internet as the greatest legal creation of wealth in history. Today we hear equally grand pronouncements that generative AI surpasses fire, the wheel, and electricity. GPT-5 will likely justify a good share of that hyperbole. By unifying multimodal reasoning—voice, video, tool use, research, code execution—OpenAI is poised to ship the first truly full-stack consumer agent, a blockbuster product by any historical yardstick.
But the leap from headline to habit requires upheaval on multiple fronts:
- Technical infrastructure
- The Web was built for humans; crawlers simply index pages so people can read them. We need a Web rewired for autonomous navigation, micro-transactions, new security rails, and agent-friendly payment flows.
- Proposals are emerging for per-article micro-payments so agents can legally ingest premium content in real time. However US public policy seems to be cutting against these proposals for competitive reasons (i.e. China).
- Business-model rewiring
- Publishers must pivot from search-engine optimization to agent-engine optimization.
- E-commerce catalogs have to expose metadata that agents—not eyeballs—can parse and act on.
- Marketing shifts from influencing a human shopper to influencing a bot that screens options based on policy and preference rules.
- Historical precedent
- In the late 1990s enthusiasm ran ahead of broadband build-out and viable revenue models; AI faces a similar gap between promise and groundwork.
The headline is that GPT-5 can ignite massive consumer adoption, yet widespread value capture hinges on re-plumbing the Web and re-monetizing content. That’s before we even tackle the additional hurdles unique to enterprise deployment, which carry their own technology, governance, and operating-model demands.
LLMs economics are brutal
Before we get too excited about GPT-5, let’s stare at the brutal economics of scale. The data below tells a big story.
Upper-right chart. That “scaling-law” line (log of compute petaflops for pre-training on the X-axis, log of test-loss, which is a fancy way of describing accuracy and the ability to recognize ever finer patterns, on the Y-axis) moves steadily down—but every inch of improvement demands an order-of-magnitude jump in PF-days (petaflop days) of compute.
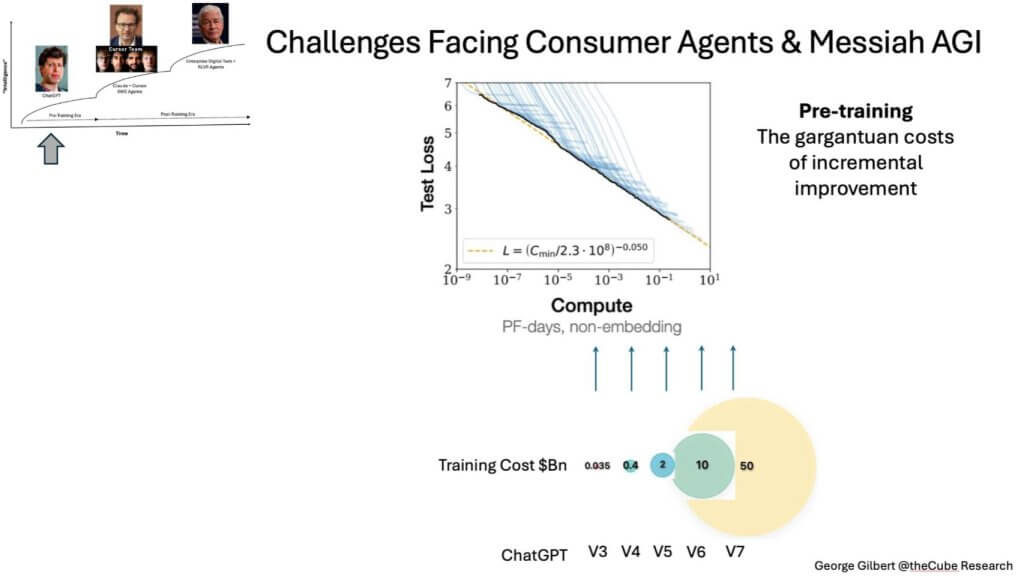
Let’s unpack where the above numbers come from.
On the slide above, the left axis shows estimated training cost per generation; the right axis plots the corresponding test-loss improvement. The $35 million mark for a GPT-3-class model is the common reference point. Each successive generation requires roughly a 10-to-30× increase in training FLOPs, but after algorithmic and hardware efficiencies the all-in cash outlay still grows about 5-to-10× each cycle. Numbers often look smaller because they capture only the final two- or three-month production run. That explains the confusion around DeepSeek’s reported $6 million cost; the figure omitted the research runs, data-ablation experiments, and restarts that consume three-to-ten times more compute before the last pass even begins.
The slide’s curve makes a second point clear. Each jump in spend buys only an incremental drop in test loss—better predictive accuracy, more reliable answers, finer pattern detection. Keeping pace on pre-training alone is already pushing costs toward $10 billion for a single next-gen run. At that level the market cannot sustain many players unless they add a strongly differentiated layer on top of the base model. Coming bottlenecks in high-quality training data and intense competition will squeeze both the magnitude and the lifespan of any price premium on raw API access.
Reinforcement-learning can address the law of diminishing returns by opening up a new scaling vector. And inference-time “reasoning” opens up yet another dimension of scaling. But the pre-training foundation still needs to keep advancing. This means the capital intensity of playing at the frontier model layer continues to increase exponentially. The economics of amortizing pre-training works as long as the end-market continues to grow at a similar pace. But when the market growth slows, the cost of pre-training is going to look like a game of musical chairs when the music stops.,
Hitting a data wall: The data scarcity and synthetic data challenge
So far we’ve focused on compute costs, but there’s an equally brutal constraint we need to discuss, which is that we’re running out of free, high-quality human text.
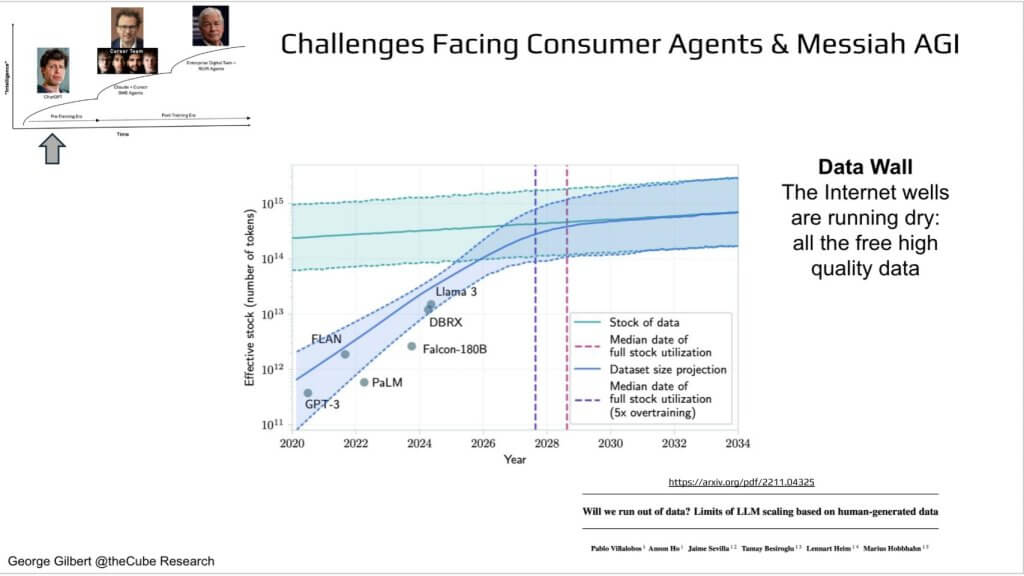
The chart above tracks the “effective stock” of usable Internet tokens (green band) versus the projected size of datasets consumed by frontier models (blue band). Those two curves meet around 2027-28—meaning every extra point of model improvement will require new strategies.
We should point out though that synthetic data is easy to generate with computer code because you can test it and therefore, the synthetic data now has more signal in it. Does it work? Does it not work? And you have all sorts of tests and that’s why as we’ll see, coding agents take off first. But the first way of trying to get past this data wall as we’re going to show is to use human-generated reasoning traces, which is when you get essentially a wide range of experts in different fields to try and elaborate on their problem-solving strategies to get to a solution for how to solve problems in specific domains, and that’s super expensive. As such:
Model vendors will see their COGS for training data rise significantly. Depending on the posture of public policy they may have to pay to license proprietary publisher data. Those deals are already starting as we saw with the recent Amazon/NYT deal. Whether this is the first of many or a high water mark remains to be seen.
More important, model vendors will have to source ever more sophisticated problem sets and “reasoning traces” from human experts in ever more fields. That’s what data vendors such as Scale.ai specialize in sourcing.
Alex Wang of Scale AI says the next breakthroughs hinge on human-annotated chains of thought—not just more scraped text prose. Annotation at that depth is expensive and slow. It’s the next bottleneck. That type of data scarcity reshapes the economics of pre-training frontier models. And it’s why Meta reportedly shelled out ~$15 billion for a 50 percent stake in Scale.ai’s network of experts.
[Listen to Alex Wang explain this phenomenon]
A key point made by Wang is: “Data production will be the lifeblood of future AI systems” and he emphasized the human element – and this is why Meta paid $15B to acquire Alex.
Some additional context to Alex Wang’s comments: Data production is very similar to spice production; it will be the lifeblood of future AI systems. The best-and-brightest people are one key source of that lifeblood, but proprietary data is just as critical. JP Morgan alone holds hundreds of petabytes of data, while GPT-4 trained on less than one petabyte. Enterprises and governments own orders-of-magnitude more proprietary data than has ever been fed into a frontier model, and that reservoir can power the next wave of truly elite systems.
The open question is the role of synthetic data. The most plausible path is hybrid human-AI generation: AI handles the bulk creation, while domain experts—people with deep reasoning skills—inject high-fidelity corrections and insights. Hybrid human-AI data is the only way to achieve the extreme quality and nuance that future models will require.
Meta’s reported $15 billion deal for Scale AI underscores this reality. The acquisition was less about tooling and more about access to Alex Wang, a small cadre of specialists, and Scale’s network of expert labelers across multiple domains. Human expert reasoning traces have emerged as the new bottleneck for frontier labs. In effect, these firms are calling for patriotic data contributions so everyone else can benefit, because without those human-validated traces, large language models will stall at their current ceiling.
‘Data Communism’
The funny part of Alex Wang’s comment was that he was basically calling on experts in every field to “contribute” their expertise for the benefit of mankind. Scale pays these experts for their time but it’s still hourly wage labor.

The tongue-in-cheek headline, “From each according to his ability, to each according to his needs,” was at the heart of Karl Marx’s economic philosophy. If you squint hard enough, that sounds an awful lot like what Alex Wang is proposing – i.e. subject matter experts contribute their knowledge for model training for the benefit of mankind.
After the $15bn acquihire, Alex Wang could be history’s richest communist.
Why coding is such a strong use case
In the enterprise, there’s a very concrete use case that is already taking off and gives every indication of supporting frontier model training on its own. Why is coding is such a popular use case? And why are software engineering agents the first killer application in the enterprise?
Let’s dig in.
The face at the top on the graphic below is Anthropic’s Dario Amodei, whose Claude model powers Cursor the product—the software engineering agent. And Cursor is just the leading example of many software engineering agents.

We’re still on the same intelligence-over-time curve, after the ChatGPT consumer bump, we see a new step-function labeled “Claude + Cursor SWE Agents.” The revenue table on the left—$1 M at launch, $100 M by month 12, $300 M by month 24, $500 M by month 30—illustrates just how fast the uptake has been.
What makes coding uniquely suited for early enterprise-agent success, and what hurdles remain before we can generalize this model to finance, supply-chain, or customer-service domains where the feedback signals aren’t as clear? The answer is provided in the commentary below:
Trial-and-error learning – reinforcement learning in formal terms – explains the breakout success of software-engineering agents. Unlike foundation models that consume fifteen-trillion-tokens of data, a coding agent generates its own data. It proposes a solution, runs a test, and immediately learns from pass-or-fail feedback. This loop supplies endless synthetic data and intrinsic reward signals, eliminating the need for vast proprietary datasets. Just as important, the workflow drops neatly into established developer tooling, so adoption requires no organizational surgery.
These conditions made software engineering the natural beachhead for AI agents. Cursor is the iconic reference point, but dozens of similar tools are scaling fast, nearly all gravitating to Anthropic’s Claude frontier model as the preferred engine. Most products focus on writing net-new code or translating between languages; wholesale refactoring of legacy codebases is a harder problem and remains largely untapped. Success in software and math does not automatically port to other enterprise domains, where equivalent, high-fidelity feedback loops are harder to construct – a challenge we explore in subsequent slides.
Quantifying why software engineering and math shine
Let’s dig deeper into why SWE and Math are such good examples. The chart below tracks accuracy on a basket of “intelligence” benchmarks – grade-school math, competitive math, software engineering task suite, multi-subject exams — over the past five years. Y-axis is benchmark accuracy; X-axis is calendar year. Everything meanders upward until sometime in ‘24 , then the red box shows a near-vertical surge. What changed? Post-training reinforcement learning on top of an already-strong base model.
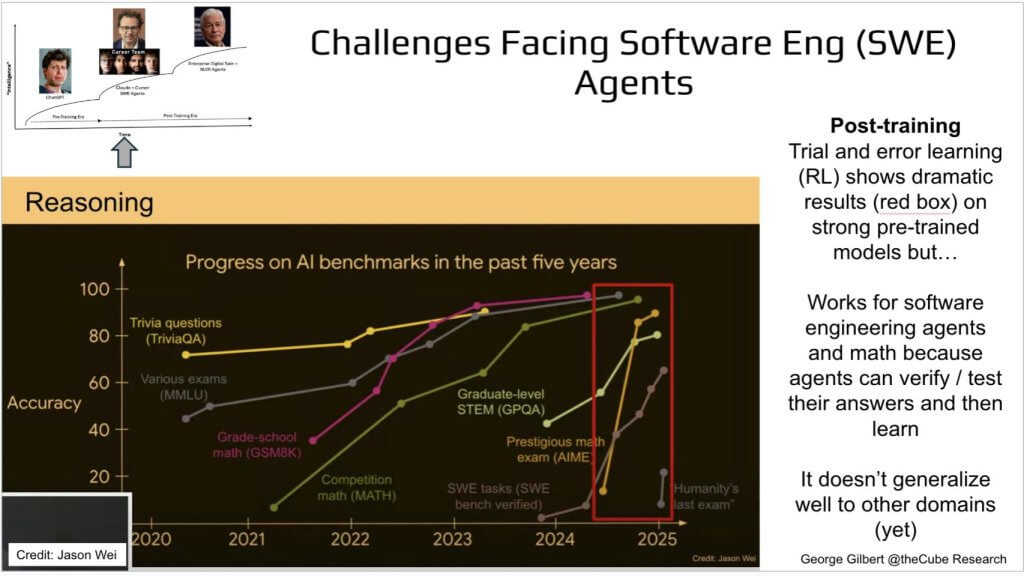
During the pre-training era – essentially up through mid-2024 – data efficiency was modest, reliant on scraping the vast but finite reservoirs of freely available Internet text. Once those wells began to run dry, progress hit diminishing returns. The inflection arrived in late 2024, when the post-training era took hold. Trial-and-error learning, i.e., reinforcement learning, allowed models to generate candidate outputs, verify them autonomously, and update weights based on right-or-wrong signals. Benchmarks in math and coding responded almost immediately, climbing at a near-vertical rate.
The mechanism is straightforward – i.e. an agent checks its own work; if the test passes, the gradient reinforces that solution, if it fails, the model adjusts. That loop delivers dramatic gains without requiring trillions of new tokens. Both domains offer an immediate, unambiguous reward signal – code compiles or it doesn’t or it passes a unit test or it doesn’t; the math is either right or wrong – so the agent can as an objective verification tool, retry, and learn. That tight loop means you don’t need another 10 trillion tokens of pre-training data; you just need a verifiable reward.
But the catch is called out on the right of the graphic. The recipe doesn’t yet generalize to, say, legal reasoning, or financial forecasting, where the ground truth is fuzzy, delayed, or buried in human judgment.
Generalizing the technique remains an open challenge. Two paths are emerging:
- Hard-to-verify domains – Areas where answers lack a binary pass/fail must rely on a second LLM to critique the output, evaluating facets of correctness and offering structured feedback. This approach is feasible but substantially harder.
- New verifiable domains – Fields that can supply objective reward signals, such as those modeled in a high-fidelity digital twin, should yield progress comparable to math and coding. The digital-twin discussion follows in subsequent sections.
The critical takeaway is once a domain provides an automated verifier, post-training efficiency explodes. The race is now to identify or construct verifiable environments beyond software and mathematics.
There may be a new way of generating synthetic data that gets us past both the data bottleneck and the challenge of objectively verifiable rewards – something that appeared not long after Wang cashed his check. It has to do with trial and error learning (the fancy term is reinforcement learning) and models that can verify subjective, not objective, answers without humans in the loop. In other words, we may have a way of getting past human expert annotators detailing their reasoning to get to a correct answer.
It appears GPT5, or an upgrade that comes soon after, will try to generate some combination of expert questions, answers, and the reasoning traces to get to the answers. Another model, acting like a teacher or verifier, will grade the right answers and the reasoning traces. This way the models might be able to get on a steep learning curve for more subjective answers just the way they’ve been learning math and coding.
Software engineering is the next wave beyond consumer agents
With verifiable rewards, SWE agents have been improving much faster than the general purpose underlying models. Once you inject reinforcement learning into a reliable reward signal, progress goes exponential.
On the chart below, the Y-axis plots “task length” (think: wall-clock work a human would need). The gentle green slope (7-month cadence) is overshadowed by the blue trendline on the right – halving the time horizon every 70 days.
Left chart (METR data). Across general agent benchmarks the length of tasks an AI can complete without human hand-holding doubles roughly every seven months. GPT-2 could answer a trivia question; GPT-4o can spend ~15 minutes autonomously optimizing code for a custom chip.
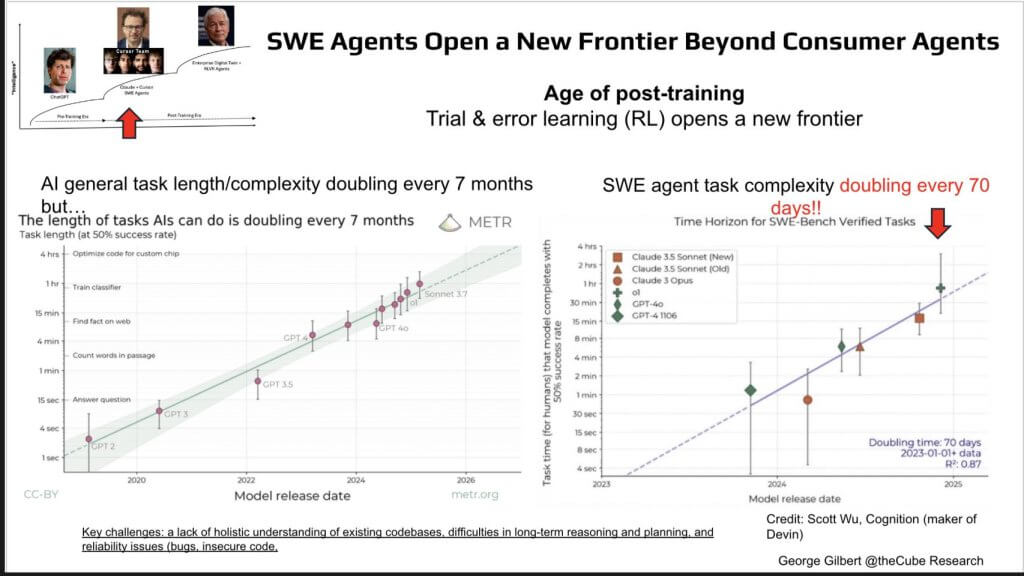
The slide isolates the core issue in agent self-improvement. For broad, loosely verified tasks the only boost comes from generic gains in the base model and occasional evaluation cycles – yielding a doubling of autonomous task-length roughly every seven months. In contrast, software-development agents operate with a hard reward signal – i.e. they either pass the unit test or they don’t. That verifiable feedback drives reinforcement learning that doubles task complexity every seventy days. The metric here is simple, how long the agent can run without human intervention. The sharper slope proves that hard, binary reward signals accelerate learning by an order of magnitude. That is the essential takeaway.
Exploring the brutal economics underpinning models
Before crowning one model king, let’s look at the brutal economics of the models beneath the rise of agentic AI products. In the chart below, the Y-axis is the composite benchmark score; each colored step represents a new model release. The dark line highlights OpenAI’s leading model, which itself changes (with each square dot), and the quick catch-up by rivals (the other colored lines).
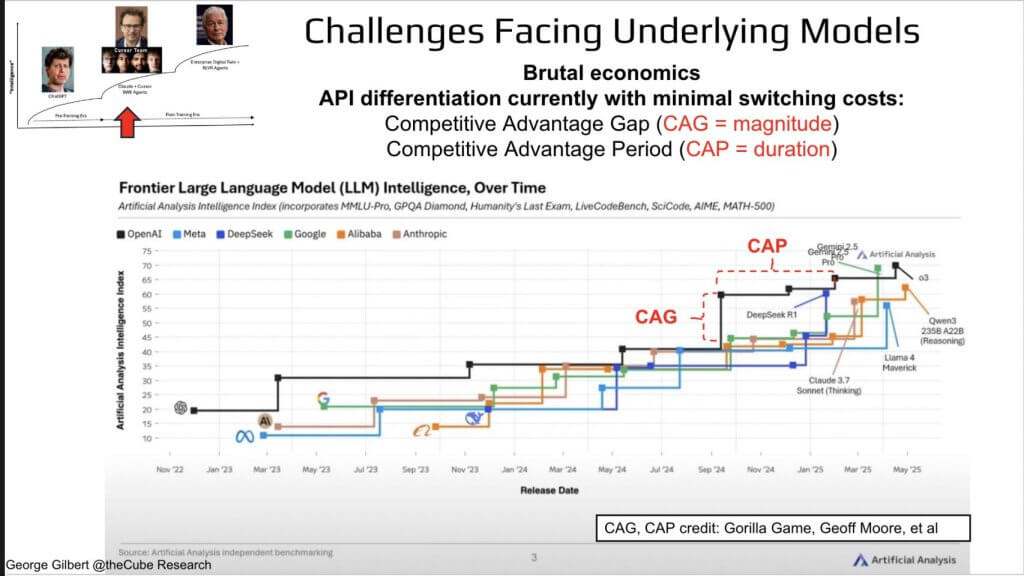
The staircase chart plots an independent “AI-intelligence index” for frontier models from OpenAI, Anthropic, Google, Meta, DeepSeek, Alibaba, and others over the past 24 months.
- The Vertical jumps (red CAG call-outs) mark a Competitive Advantage Gap – how far a release leaps ahead of the pack.
- Horizontal lines show the CAP – Competitive Advantage Period – how long that lead lasts before a rival catches up.
What stands out is how small both dimensions have become. GPT-4o takes the lead but within weeks DeepSeek R1 or Gemini 3 closes the gap. Switching costs between APIs are measured in a few lines of Python code, so the CAP shortens with every release. In other words, you can spend a billion dollars on compute and data only to enjoy a six-week pricing umbrella before the market reduces your advantage to zero.
The point is, spending ten billion dollars and multiple years on a frontier training run no longer guarantees a lasting edge. The moment a new model lands, the competitive lead can evaporate almost as quickly as a new consumer gadget cycle. Unlike the pharmaceutical industry – where patent protection secures a decade of exclusivity – model training enjoys no comparable moat.
The current race revolves around ever‐larger compute clusters and incremental algorithmic tweaks. Hardware scale is available to any firm with sufficient capital; algorithmic insights diffuse quickly through open research and employee mobility. Proprietary training data helps, but it is only one ingredient and rarely decisive. To achieve both a substantial competitive-advantage gap and a durable competitive-advantage period, the game must shift. The next era will require an entirely different data foundation, one capable of conferring a sustained, defensible edge. That foundation is the enterprise digital twin discussed in the sections that follow.
To tease the last section, Jamie Dimon and any other enterprise that can model their data into a digital twin of operations, can train proprietary agents that have a very high CAG and a durable CAP. All the capex may be going into a half dozen or more frontier labs, but the sustainable differentiation will lie in these enterprises.
Pricing models for Messiah AGI
Let’s now explore how this dynamic shows up in pricing models for the underlying frontier models. The chart below lays this out. Here’s the killer behind those shrinking advantage windows: token prices are in free-fall. Y-axis is log-scale price per million tokens (from $100 down to sub-penny). X-axis spans Oct ’21 to Apr ’25. Each diagonal line shows successive model releases driving price down an order of magnitude every few months.
So USD per million tokens against release dates. Every colored trend-line is a different capability tier -GPT-3.5-class (teal), GPT-4-class (pink), GPT-4o-plus (blue). Regardless of tier, prices are declining on an exponential glide-path:
- The slopes are getting steeper with each new generation of models
- GPT3.5 Turbo class models were declining in price at 9x/year
- GPT4 class models were declining in price at 40x/year
- GPT4o class models were declining in price at 900x/year.
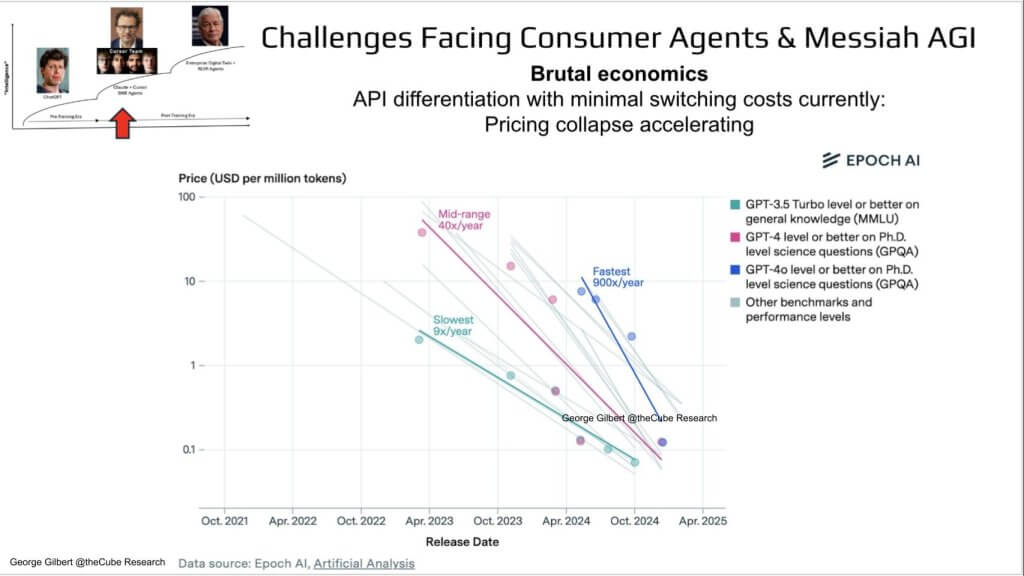
In other words, you can burn $10 billion on GPT-6 training and watch the market re-price that output at a fraction of the margin in a single quarter. Throw in minimal switching costs for customers of the API and you get the picture. The point is Packaged agents—bundled with proprietary data and workflow context—are where we think the durable economics will live.
The accelerating collapse in API pricing stands apart from the economics of products built on top. Venture capital is pouring into frontier labs at an unprecedented rate. Nation-state funds are underwriting domestic model efforts, Chinese labs are proliferating, and high-profile entrants – Elon Musk among them – are scrambling to join the race. The parallel to the late-’90s Internet bubble is hard to ignore– tens of billions chasing what increasingly looks like a mirage.
Today the consumer-agent crown already sits with the incumbent leader, and the leading API position belongs to Anthropic. Durable differentiation will not come from another round of capital-intensive model training; it will come from doing something genuinely different. That necessity ushers in the next era, where the advantage shifts to differentiated data foundations and domain-specific agent platforms.
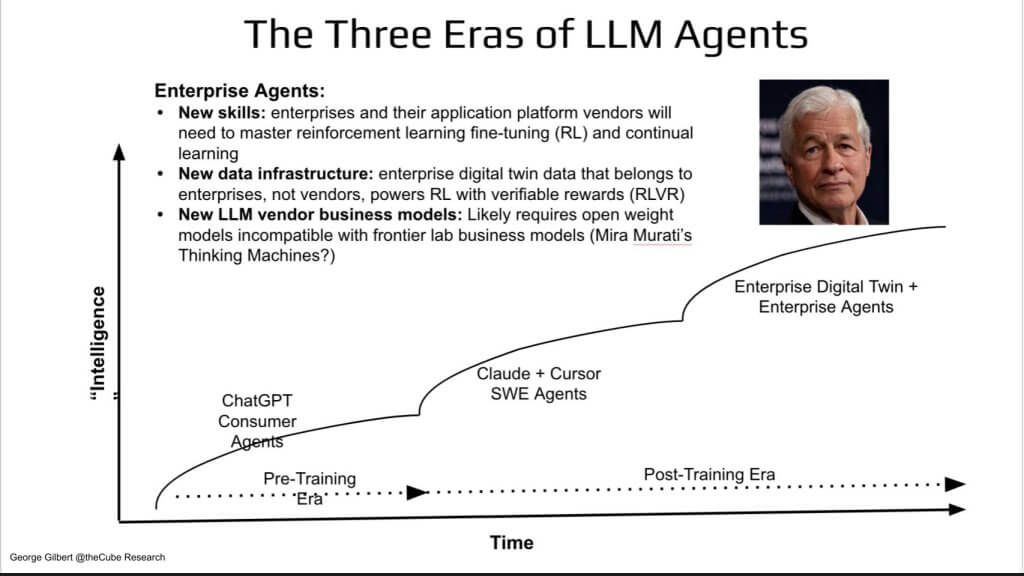
The third era: Enterprise agents
Let’s come Back to our 3 Eras of AI.
We’ve come full circle: consumer chatbots got us started, coding agents proved to be a flywheel, but enterprise agents are where the real money—and long-term moat—will be built in our view. Think of the trajectory in three discrete eras, mapped on the curve you’ve seen all episode:
- Pre-training era — Consumer agents. ChatGPT showed how powerful the product is, but revenue from the underlying model API is constrained by collapsing token prices and low switching costs.
- Post-training era — Coding agents. Claude-plus-Cursor validated RL on verifiable outputs, doubling task complexity every 70 days and driving ARR to new scale.
- Digital-twin era — Enterprise agents.
The core takeaway is AI is programmed by data, and true durable differentiation will come from proprietary data. Consider JPMorgan Chase as a stand-in for any advanced enterprise. Initial estimates pegged its private corpus at roughly 150 petabytes – already hundreds of times the half-petabyte to one-petabyte used to train a GPT-4-class model. More recent figures suggest the bank may hold on the order of an exabyte. Yet volume alone isn’t the story; it’s how that data is modeled to represent day-to-day operations. Enterprise data is dense, high-signal, and – if properly organized – far richer than the broad, low-signal crawl that feeds frontier models.
Unlocking that value demands several shifts:
- Mastery of reinforcement learning—trial-and-error loops that enable continual improvement on live business tasks.
- A new data foundation: a digital twin that tracks people, places, things, and activities. This process-centric model breaks through six decades of application and data silos; it is not merely a bigger lake.
- Open-weight models. Early evidence indicates reinforcement learning works best when the underlying weights are accessible, a requirement that clashes with the closed-API business models of most frontier labs. Mira Murati’s Thinking Machines effort appears to be one path toward reconciling openness with commercial viability.
These elements will trigger new go-to-market motions, a fresh generation of application-platform vendors, revamped technical stacks, and—ultimately—organizational and business-model change for the enterprises that adopt them.
Envisioning ‘enterprise AGI’
Let’s dig into what enterprise AGI will actually look like. Below is a classic diagram many use to describe the elements of agentic AI – but keyu pieces are missing to power the enterprise in our view.
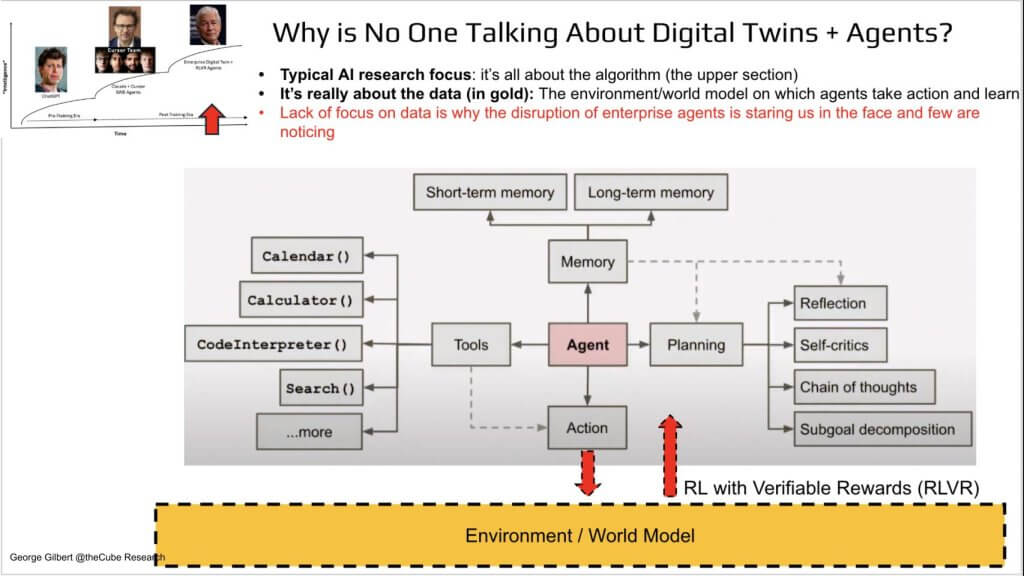
Most agent diagrams look identical – tools on the left – calendar, calculator, code interpreter, search; cognitive modules on the right – planning, reflection, self-critique, chain-of-thought, sub-goal decomposition; a memory stack across the top; and an action port along the bottom. The entire picture is algorithm-centric because that is what computer-science researchers reward. Data hardly shows up, yet in the enterprise data is everything.
This particular diagram – borrowed from a recent Stanford CS lecture – omits the component that actually creates value – the environment or world model. An agent learns only by interacting with its environment and receiving feedback on the outcome. In academic settings that omission is an afterthought; in a business context it is the difference between a toy and a system that can move revenue, cost, or risk.
The absence of a first-class data layer in mainstream agent thinking underscores why enterprise agents remain an under-explored frontier. The disruption is staring the industry in the face, but few acknowledge it because the conversation is dominated by algorithmic heroes rather than data realism.
Gaming examples are instructive
Let’s pull some examples from Real World Models where Agents got started.
Before we take too many liberties with the phrase enterprise digital twin, it helps to remember the very first twins that ever mattered to AI researchers were seen in gaming. DeepMind’s AlphaStar learned to dominate StarCraft II not just because its model architecture was magic , but because the entire game environment – the 4-D map of units, resources, timing, and fog-of-war – was exposed as a perfect, real-time real world model.
On the graph below we show the Match-making-rating (MMR) percentile on the X-axis, skill level on the Y-axis. The blue curve is human progression from silver to grandmaster; the red dot is AlphaStar smashing through the top percentile – discovering strategies no human had ever tried, courtesy of reinforcement learning a digital twin.

The crucial insight is the mapping of people, places, things, and activities inside a game world to the same four dimensions—people, places, things, and processes—inside a business. Conventional data platforms provide static snapshots, a kaleidoscope view. Agents require a richer, dynamic representation that captures how actions ripple across the enterprise. When an agent modifies a step in a process it needs the map to trace the impact on downstream people and workflows.
Reinforcement learning flourished first inside environments that already contained such world models. DeepMind’s AlphaStar for StarCraft and OpenAI’s work on the Dota strategy game are canonical examples. Each environment supplied continuous, verifiable rewards – i.e. intermediate signals that tested strategic choices and an ultimate win-or-lose outcome. These conditions allowed agents to iterate rapidly and improve.
The same principles apply to the enterprise. By constructing a four-dimensional digital twin – people, places, things, processes – businesses can deliver the feedback loops agents need to learn, adapt, and ultimately drive measurable results across complex operations. Lessons from AlphaStar and Dota form the blueprint for this more advanced, enterprise-grade implementation.
If an agent can exploit a synthetic world model to beat 99% of pro gamers, imagine what it can do when the “map” is a digital twin of a bank or a live model of a supply-chain. But that also means enterprises – not vendors – must own and curate the world model so the agent can learn with verifiable rewards. The point is that the lessons from AlphaStar will translate to finance, healthcare, and manufacturing, anything with a digital twin.
Minecraft example of learned skills
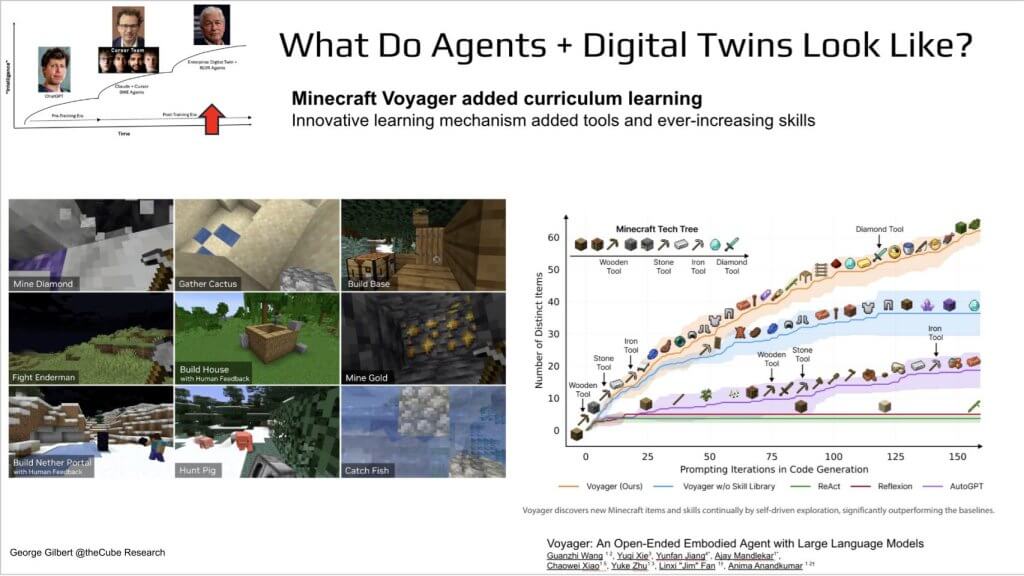
Minecraft serves as the next reference world model. In the Voyager project the environment is more open-ended than StarCraft. An agent starts by learning how to craft simple stone tools, then uses those tools to build basic structures. As competence grows it discovers how to forge more advanced implements, each new capability unlocking a broader range of tasks. Over time the agent accumulates skills and expands the set of tools at its disposal. That progressive, self-directed skill acquisition is critical because every new ability enriches the environment and, in turn, furnishes richer feedback for further learning. The pattern – learn a tool, use it to create value, learn the next tool – provides an important template for constructing an enterprise world model where agents continuously extend their own action space.
Algos without data = failure of agents
Now let’s really try to double down on the importance of Data
Every headline about AI credits the algorithm – AlexNet, Transformers, RLHF, the new reasoning stacks – but the right side of this slide reminds us that each breakthrough was really sparked by a new dataset era.

| Algorithm | Data Set |
| AlexNet (2012) | ImageNet – a labeled corpus of 14 M photos |
| Transformers (2017) | Web crawl – trillions of tokens scraped at scale |
| RLHF chatbots (2022) | Reward-model data – human-ranked responses |
| Reasoning agents (now) | Enterprise twins – verifiable, domain-specific world models |
A recent blog post by Jack Morrison, highlighted on the Latent Space podcast, underscores a recurring blind spot: everyone fixates on algorithmic breakthroughs while ignoring the dataset hiding in plain sight. Morrison sketches the reasoning era and notes that agents will learn from verifiers—calculators for math, compilers and unit tests for code—yet leaves the critical dataset box essentially blank. The dataset is obvious. Every organization is building, or will build, a platform that captures an ever-larger digital twin of its operations. That twin—people, places, things, processes—is the immense, high-fidelity corpus that will power enterprise-grade reasoning.
Connecting enterprise agents with digital twins
Let’s now connect enterprise agents with digital twins as we’re defining them
We’ve moved up the curve from consumer chat to coding / SWE agents – and the slide below shows how it all works inside a company. The chart from Palantir highlights at the bottom right an end-to end supply-chain twin; red call-outs on the left highlight RL feedback arrows feeding the agent box. The metric tree illustrates how “What happened?” rolls up to “What should we do?”
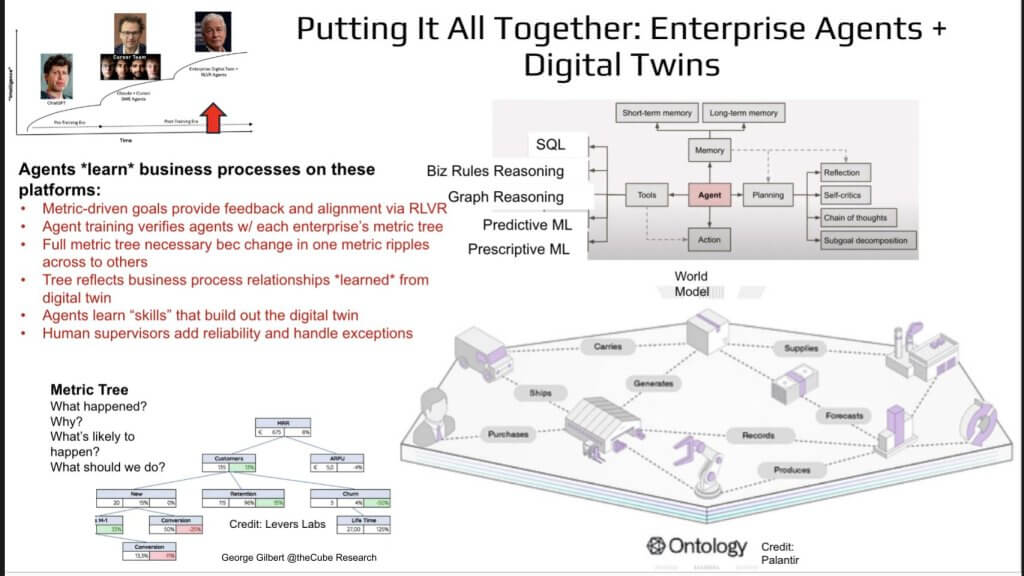
Think of three layers working in concert:
Installing a digital twin – like the Palantir schematic shown here – is only the first step. The engine that turns that representation into agent learning is the metric tree. Unlike conventional BI dashboards, where KPIs live in isolated tables or hand-coded formulas, a metric tree links every measure in a learned, hierarchical graph. Change a node – say, authorizing a product return – and the tree reveals ripples across customer-support satisfaction, on-hand inventory, and cash-flow metrics. The richer the twin, the higher the fidelity of those relationships.
The agent sits above this structure and dynamically selects tools that correspond to analytical intent:
- What happened? — SQL queries on the twin
- Why did it happen? — business-rules execution and graph reasoning
- What’s likely to happen next? — predictive ML
- What should we do? — prescriptive ML
If the tree lacks a metric, the agent adds one – mirroring how Voyager in Minecraft learned new tools and skills, then fed them back into the environment. Each new metric becomes a tool; each successful action becomes a skill; both flow into the twin, iteratively expanding its scope. The result is a self-reinforcing feedback loop: agent actions enrich the symbolic model, and the enriched model, in turn, sharpens agent decisions. The twin need not be perfect on day one; it grows in lock-step with agent capability.
A new enterprise architecture is emerging
Let’s look at how this will impact enterprise architecture.
This graphic below builds on our previous work and pulls it all together. It also answers the question: Who is actually building a live, digital representation of the business?
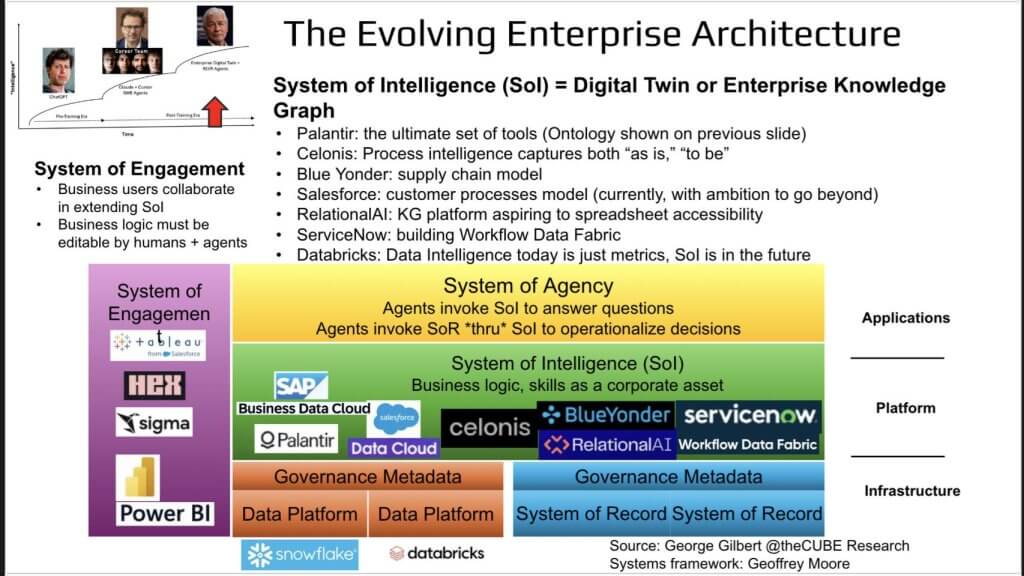
The graphic reprises the layered stack often used in Breaking Analysis and Services-as-Software.
- Purple – System of Engagement. BI players—Tableau, Hex, Sigma, Power BI—must inject business context into the platform through metrics and dimensions.
- Green – System of Intelligence. This is the digital-twin layer, the most valuable real estate. Vendors vying to own the 4-D map include Palantir, Celonis, Blue Yonder, Salesforce Data Cloud, RelationalAI, ServiceNow, and Databricks (by aspiration). Whoever hard-wires business logic and skills here sets the rules for everyone else.
- Yellow – System of Agency. Once the twin is live, agents call it for answers and route write-backs through it, ensuring every action lands under governed policy.
- Orange – Governance. Policies and lineage span the stack.
- Blue – Data Infrastructure. Snowflake, Databricks, and the hyperscalers sit here—vital plumbing, but margin pressure grows as value shifts upward.
This pattern echoes the history of IT – i.e. each new abstraction layer envelops the one below. Lower layers keep innovating, but lose feature-based differentiation and pricing power once the upper layer decides which capabilities to expose. Traditional data platforms captured snapshots of strings; metric-centric platforms upgraded those to snapshots of things. The green layer goes further – capturing processes – bridging sixty years of application and data islands.
A quick tour of the contenders:
- Palantir offers a rich ontology—powerful but demanding, the ultimate set of tools for those who can wield them.
- Celonis captures the as-is state of thousands of process variants, then packages optimizations so customers avoid hand-building every flow.
- Blue Yonder delivers an end-to-end supply-chain model ready to operate.
- Salesforce already models customer processes and intends to extend far beyond, a goal underscored by the Informatica acquisition.
- RelationalAI introduces a knowledge-graph platform with spreadsheet-level accessibility; its declarative model lets business users participate directly in defining logic.
- ServiceNow is assembling a workflow data fabric—another process-oriented approach.
- Databricks calls data intelligence existential and plans to move past metrics-and-dimensions toward full process knowledge. Its advanced agent-development tools will require that richer data intelligence or partnerships with the vendors above to realize their potential.
Margin and control will accrue to the layer that captures processes and feeds agents; data infrastructure, while indispensable, becomes the cost-optimized foundation beneath it.
A bifurcated enterprise software world
Let’s focus now on how Enterprise Software Is Splitting Into Two Worlds.

Picture the frozen-lake scene from the recent Bond film -Rami Malek’s villain stands unharmed on the glossy surface while a diver flails in the frigid water below. The metaphor captures how enterprise software is cleaving into two distinct worlds.
- Above the ice sits the yellow-green territory: Systems of Engagement, Intelligence, and Agency. Vendors here learn the business from a live digital twin and push toward outcome-based pricing. Differentiation is high, and a significant share of value will ultimately accrue to enterprises themselves, with supporting vendors participating alongside them.
- Below the ice lie the data platforms, storage formats, GPUs, and other infrastructure. Pricing trends toward utility rates unless a supplier commands near-monopoly leverage – Intel once did, NVIDIA may for now, and hyperscalers could maintain an artificial umbrella over spot instances. History suggests those umbrellas collapse over time, making it harder to stand out at this layer.
The industry is aligning accordingly: players above the ice focus on modeled business context and higher-margin economics, while those below face mounting pressure to commoditize. The strategic choice is to move up into outcome-driven layers or prepare for tightening margins in the infrastructure trench.
Thriving enterprises will reimagine their businesses: No paving the cowpath
The discussion comes back to a single conclusion – i.e. ownership of coherent, high-signal enterprise data is the deciding factor in the next wave of AI value capture. Labs may still dominate headline model releases, yet those models increasingly rely on proprietary ground-truth data that only large organizations possess in scale.

On the visual above, Sam Altman anchors the left – world-famous foundation models. Dario Amodei sits center-left, demonstrating that post-training on domain feedback can spin meaningful ARR. Center-right stands the prize everyone is pursuing. In our view, a live, verifiable digital twin of an enterprise is represented at the far right by Jamie Dimon, steward of the deepest transaction ledger in banking, perfectly positioned to weaponize that twin and challenge model labs on both margin and moat.
Key takeaways
- Enterprises that build and maintain a digital twin – people, places, things, processes – are best placed to harvest AI profit pools.
- The shift demands more than technology; it requires re-organizing around end-to-end customer outcomes. For a bank the benchmark might be onboarding and knowing a customer – in compliance terms – as fast as possible.
- The change is analogous to moving white-collar work from craft production to an assembly line. Organizational redesign and data modeling go hand-in-hand.
For deeper exploration of the operating-model implications, see the companion interview below with Carsten Thoma, President of Celonis:
Disclaimer: All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by News Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of theCUBE Research. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.
Image: theCUBE Research/Grok
Support our open free content by sharing and engaging with our content and community.
Join theCUBE Alumni Trust Network
Where Technology Leaders Connect, Share Intelligence & Create Opportunities
11.4k+
CUBE Alumni Network
C-level and Technical
Domain Experts
Connect with 11,413+ industry leaders from our network of tech and business leaders forming a unique trusted network effect.
News Media is a recognized leader in digital media innovation serving innovative audiences and brands, bringing together cutting-edge technology, influential content, strategic insights and real-time audience engagement. As the parent company of News, theCUBE Network, theCUBE Research, CUBE365, theCUBE AI and theCUBE SuperStudios — such as those established in Silicon Valley and the New York Stock Exchange (NYSE) — News Media operates at the intersection of media, technology, and AI. .
Founded by tech visionaries John Furrier and Dave Vellante, News Media has built a powerful ecosystem of industry-leading digital media brands, with a reach of 15+ million elite tech professionals. The company’s new, proprietary theCUBE AI Video cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.






{kind=link}