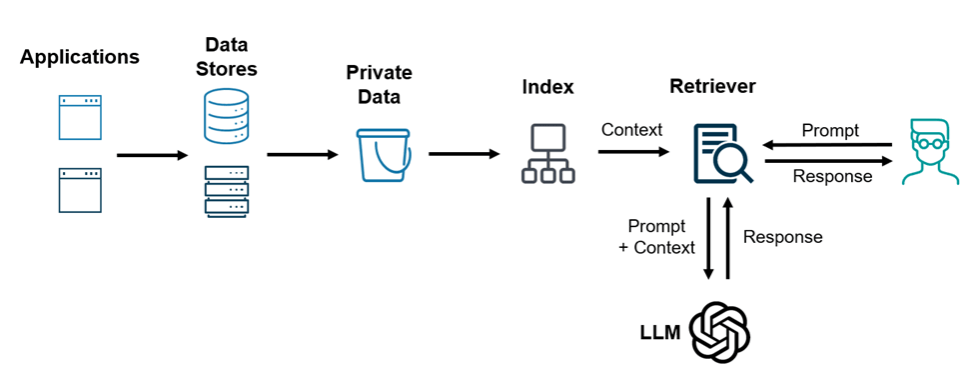
Data security has become a key concern as enterprises deploy RAG applications utilizing Large Language Models. In a recent survey, more than 80% of participating privacy teams said they deal with AI and data governance fields. Data protection is a vital issue when developing AI application tools.
Trust can only be built where data privacy and commercial-grade security standards are observed. Although some customers can now manage their record retention periods, the risk of employing private information in RAG workflows that depend on third-party LLM remains.
The threat surface is significantly high even if you use LLMs on your physical machines. This article will analyze if and how the providers of LLM systems collecting and processing data can meet the privacy and security requirements that enterprises need.


What Happens to Your Data When You Use LLMs?
The LLM you are using is highly dependent on the service user contracts and the policies set up by the provider when it comes to data usage. Data privacy and security are key for most LLM service providers; however, there is still variance in their practices regarding data retention.
Temporary Data Storage
Providers sometimes permit short-term storage of user data to detect misuse, monitoring, and debugging. Azure OpenAI Service allows users to submit various types of input data and receive AI-generated responses. The service ensures that user data remains confidential and is not used to improve AI models without explicit consent. They keep good content moderators preemptively to reduce the risk of inappropriate content generation.
Permanent Data Storage
On the other hand, some providers may set policies to improve model performance by retaining data for long periods. Organizations should review data retention practices to ensure compliance with privacy regulations and safeguard sensitive proprietary information.
When handling such data, it’s critical to evaluate whether the provider’s policies align with enterprise privacy standards, as improper retention or usage could constitute a breach of confidentiality and trust.
Ensure that the terms of service provided by the appropriate service provider are read to understand its data retention and use policies fully.
Enterprise-Level Agreements
Companies that maintain strict privacy and data protection regimes often pursue an enterprise-grade deal with the LLM providers. This agreement regularly entails Zero Data Retention (ZDR)—the user’s data will not be collected or reused without the user’s consent. For example, Joist AI works with top LLM providers on ZDR contracts, which restricts them from retaining any extra information that has been processed except that intended for the current task. Measures like these illustrate data protection commitment at the industry level by including Microsoft’s adherence to specific ZDR policies.
Provider-Specific Policies
With so many diverse LLM providers available today, practice caution when choosing the kind of data you wish to share. Here’s a quick summary of data privacy policies for major LLM services:
Azure OpenAI Service
In Microsoft’s case, all customer data uploaded onto the Azure OpenAI service is kept secure and private. User prompts and the generated content have to remain in the customer’s geography and aren’t allowed to be used to train or improve base models unless explicit consent is given. There are content filters to prevent abuse of the service and abuse monitoring systems in place. Data for fine-tuning is also encrypted at rest, allowing the customer to delete it anytime.
Open AI LLM (Direct Use)
When users employ OpenAI’s direct API services, their data is also analyzed for abuse prevention and model improvements. In other words, the prompts and responses are retained and utilized to train the system. People with concerns regarding data privacy should go through OpenAI’s privacy policy carefully and consider whether to give sensitive information through OpenAI’s platform.
Google Vertex AI / PaLM API
Google’s Vertex AI system offers neat data protection measures, including encryption of user data while in use and at rest. However, the available information about model training, its retention, and its use for the public is pretty scarce, making it necessary for organizations to seek clarification from Google directly to ensure that their data protection policies align with those of the organization. However, the company ensures that customer information will not be used to train their models without permission. Further information can be found in Google’s data privacy policy.
AWS Bedrock
AWS Bedrock works on various foundation models, including models created by AI21 Labs, Anthropic, and Stability AI. Regarding data protection, AWS explains that customer data is not used in training any models developed without the customer’s explicit permission.
The information processed within the Bedrock application is kept within the AWS ecosystem and, therefore, can benefit from the security, compliance, and other amenities AWS offers.
Anthropic (Claude)
Claude models developed by Anthropic adhere to a strict policy of protecting user privacy and data security. As stated in the company’s policy on privacy, user prompts or responses are not incorporated into model training unless users consent to such feedback or voluntarily provide it.
Additionally, for the provision of the Claude service, clients can process the data as they direct without using it for training the mode, as Anthropic is only registered as a data processor. Users are advised to learn more about the implications of the terms through which concepts are used and the company’s policies to formulate their nouns.
Why Data Storage May Be Necessary?
The data is stored for several core reasons: to enhance large language models’ versatility, effectiveness, and robustness.
Abuse Detection
One of the reasons the LLM models require storage is to put it to use to expose and prevent any abuse of the model. LLM providers can recognize abusers who generate illicit content and have it stored temporarily. This data is then analyzed to establish patterns and take necessary and appropriate actions to eradicate malicious and abusive behavior.
Debugging and Monitoring
An additional core reason why LLMs require data storage is to facilitate debugging and monitoring. Developers frequently come across issues, and after backing up interactions, these stored interactions are needed to diagnose the problem, evaluate the system performance, and incorporate any required changes. This is vital to sustain the effectiveness and accuracy of the model.
Model Fine-Tuning
LLMs that have been trained previously have to be fine-tuned to facilitate them performing certain tasks or working in specific areas. To effectively train a model, relevant data must be stored and utilized, and such is a model fine-tuning. When organizations model, it proves to be more reliable and precise.
How Can Enterprises Ensure Data Privacy?
There are several ways in which an enterprise can improve data privacy while employing Large Language Models (LLMs):
- Verify Provider Policies: Understanding how providers manage and secure data is essential for compliance and risk mitigation; consider a closer inspection of LLM Providers’ policies and procedures on data collection and privacy to ensure that it complies with your enterprise’s security requirements.
- Enterprise Agreements: These contracts include provisions that prevent the other party from using collected data outside of the intended purpose. Organizations may want such contracts to enhance security measures to protect the organization.
- Use Private Deployments: Host LLMs on a private cloud/internal infrastructure rather than a public one, decreasing the risk of outside exposure.
- Data Minimization and Anonymization: To minimize the likelihood of security breaches and comply with privacy laws, avoid using personal data that is not strictly necessary and, if required, redacted.
- Monitor and Audit: Engage in regular audits and monitoring regarding the actions taken and LLM applications within the organization to minimize violations. Continuous supervision assists in achieving appropriate privacy protection measures or data accuracy.
What are Compliance and Regulatory Considerations?
Enterprises must consider essential compliance frameworks when deploying Large Language Models (LLMs) to not compromise data privacy. Among these frameworks are:
GDPR
The General Data Protection Regulation is a data protection law that applies within the boundaries of the European Union, which requires certain criteria to be met for compliance. Consent to data processing is to be explicit, and individuals should have the right to access or erase their data.
HIPAA
In the United States, protected HIPAA frameworks govern Protected Health Information (PHI). The organizations holding or safeguarding this information must only protect their confidentiality and integrity in disclosing what is necessary under the Privacy and Security Rule’s stipulations.
SOC 2 Type II
Sociology, which restricts service provision to those set standards, is also a voluntary compliance protocol maintaining the security, availability, and integrity of customers’ data and their privacy. Compliance with SOC 2 Type II means that an organization follows acceptable standards for a certain time.
Conclusion
Large Language Model (LLM) applications require user data privacy to comply with policies and to foster user loyalty. Enterprises can effectively manage LLMs’ risks by taking stringent security measures, meeting compliance, and following key principles. Periodic assessments, limiting the data collected, and obtaining consent are essential in protecting sensitive data.






{kind=link}