Authors:
(1) Raphaël Millière, Department of Philosophy, Macquarie University ([email protected]);
(2) Cameron Buckner, Department of Philosophy, University of Houston ([email protected]).
Table of Links
Abstract and 1 Introduction
2. A primer on LLMs
2.1. Historical foundations
2.2. Transformer-based LLMs
3. Interface with classic philosophical issues
3.1. Compositionality
3.2. Nativism and language acquisition
3.3. Language understanding and grounding
3.4. World models
3.5. Transmission of cultural knowledge and linguistic scaffolding
4. Conclusion, Glossary, and References
2.2. Transformer-based LLMs
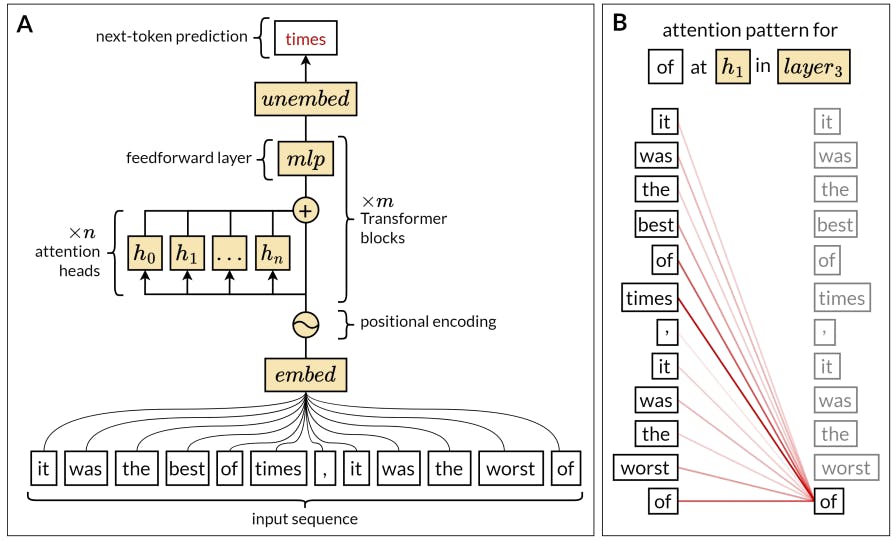
One of the key advantages of the Transformer architecture is that all words in the input sequence are processed in parallel rather than sequentially, by contrast with RNNs, LSTMS and GRUs.[6] Not only does this architectural modification greatly boost training efficiency, it also improves the model’s ability to handle long sequences of text, thus increasing the scale and complexity of language tasks that can be performed.
At the heart of the Transformer model lies a mechanism known as self-attention (Fig. 2). Simply put, self-attention allows the model to weigh the importance of different parts of a sequence when processing each individual word contained in that sequence. For instance, when processing the word “it” in a sentence, the self-attention mechanism allows the model to determine which previous word(s) in the sentence “it” refers to–which can change for different occurrences of “it” in different sentences. This mechanism helps LLMs to construct a sophisticated representation of long sequences of text by considering not just individual words, but the interrelationships among all words in the sequence. Beyond the sentence level, it enables LLMs to consider the broader context in which expressions occur, tracing themes, ideas, or characters through paragraphs or whole documents.
It is worth mentioning that Transformer models do not operate on words directly, but on linguistic units known as tokens. Tokens can map onto whole words, but they can also map onto smaller word pieces. Before each sequence of words is fed to the model, it is chunked into the corresponding tokens – a process called tokenization. The goal of tokenization is to strike a balance between the total number of unique tokens (the size of the model’s “vocabulary”), which should be kept relatively low for computational efficiency, and the ability to represent as many words from as many languages as possible, including rare and complex words. This is typically accomplished by breaking down words into common sub-word units, which need not carve them at their morphologically meaningful joints. For example, GPT-4’s tokenizer maps the word “metaphysics” onto three tokens, corresponding to “met”, “aph”, and “ysics” respectively. Similarly, numbers need not be tokenized into meaningful units for the decimal system; GPT-3 processes “940” as a single token, while “941” gets processed as two tokens for “9” and “41” (this quirk of tokenization goes a long way towards explaining why LLMs can struggle with multiple-digit arithmetic; see Wallace et al. (2019) and Lee et al. (2023)).
The most common variant of Transformer-based models are known as “autoregressive” models – including GPT-3, GPT-4, and ChatGPT. Autoregressive models operate using a learning objective called next-token prediction: given a sequence of tokens, they are tasked with predicting which token is statistically most likely to follow. They are trained on a large corpus that includes a diverse range of sources, such as encyclopedias, academic articles, books, websites, and, in more recent iterations of the GPT series, even a substantial amount of computer code. The goal is to provide the model with a rich, diverse dataset that encapsulates the breadth and depth of natural and artificial languages, allowing it to learn from next-token prediction in many different contexts.
At each training step, the model’s objective is to predict the next token in a sequence sampled from the corpus, based on the tokens that precede. For instance, given the sequence “The cat is on


the,” the model might predict “mat” as the most likely next token. The model is initialized with random parameters, which means its first predictions are essentially no better than chance. However, with each prediction, the model’s parameters are incrementally adjusted to minimize the discrepancy between its prediction and the actual next token in the training data. This process is iterated over billions of training steps, until the model becomes excellent at predicting the next token in any context sampled from the training data. This means that a trained model should be able to write text – or code – fluently, picking up on contextual clues provided in the “prompt” or input sequence.
While LLMs trained in this way are very good at generating convincing paragraphs, they have no intrinsic preference for truthful, useful, or inoffensive language. Indeed, the task of next-token prediction does not explicitly incorporate common normative goals of human language use. To overcome this limitation, it is possible to refine a model pre-trained with next-token prediction by “fine-tuning” it on a different learning objective. One popular fine-tuning technique in recent LLMs such as ChatGPT is called “reinforcement learning from human feedback,” or RLHF (Christiano et al. 2017).
RLHF proceeds in three stages. The initial stage involves collecting a dataset of human comparisons. In this phase, human crowdworkers are asked to review and rank different model responses according to their quality. For instance, the model may generate multiple responses to a particular prompt, and human reviewers are asked to rank these responses based on certain normative criteria such as helpfulness, harmlessness and honesty (the “three Hs”, Askell et al. 2021). This results in a comparison dataset that reflects a preference ranking among possible responses to a set of inputs. In the second stage, this comparison data is used to train a reward model that guides the fine-tuning process of the model. A reward model is a function that assigns a numerical score to a given model output based on its perceived quality. By leveraging the comparison data, developers can train this reward model to estimate the quality of different responses. In the third and final stage, the reward model’s outputs are used as feedback signals in a reinforcement learning process, to fine-tune the pre-trained LLM’s parameters. In other words, the pre-trained LLM learns to generate responses that are expected to receive higher rankings based on the reward model. This process can be repeated iteratively, such that the model’s performance improves with each iteration. However, the effectiveness of this approach heavily relies on the quality of the comparison data and the reward model.
RLHF allows developers to steer model outputs in more specific and controlled directions. For instance, this method can be utilized to reduce harmful and untruthful outputs, to encourage the model to ask clarifying questions when a prompt is ambiguous, or to align the model’s responses with specific ethical guidelines or community norms. By combining next-token prediction with RLHF, we can guide LLMs to produce outputs that are not just statistically likely, but also preferred from a human perspective. The fine-tuning process thus plays a crucial role in adapting these models to better cater to the normative goals of human language use.
LLMs have a remarkable ability to use contextual information from the text prompt (user input) to guide their outputs. Deployed language models have already been pre-trained, and so do not learn in the conventional “machine learning” sense when they generate text; their parameters remain fixed (or “frozen”) after training, and most architectures lack an editable long-term memory resource. Nonetheless, their capacity to flexibly adjust their outputs based on the context provided, including tasks they have not explicitly been trained for, can be seen as a form of on-the-fly “learning” or adaptation, and is often referred to as “in-context learning” (Brown et al. 2020). At a more general level, in-context learning can be interpreted as a form of pattern completion. The model has been trained to predict the next token in a sequence, and if the sequence is structured as a familiar problem or task, the model will attempt to “complete” it in a manner consistent with its training. This feature can be leveraged to give specific instructions to the model with carefully designed prompts.
In so-called “few-shot learning”, the prompt is structured to include a few examples of the task to be performed, followed by a new instance of the task that requires a response. For instance, to perform a translation task, the prompt might contain a few pairs of English sentences and their French translations, followed by a new English sentence to be translated. The model, aiming to continue the pattern, will generate a French translation of the new sentence. By looking at the context, the model infers that it should translate the English sentence into French, instead of doing something else such as continuing the English sentence. In “zero-shot learning,” by contrast, the model is not given any examples; instead, the task is outlined or implied directly within the prompt. Using the same translation example, the model might be provided with an English sentence and the instruction “Translate this sentence into French:”. Despite receiving no example translations, the model is still able to perform the task accurately, leveraging the extensive exposure to different tasks during training to parse the instruction and generate the appropriate output.
Few-shot learning has long been considered an important aspect of human intelligence, manifested in the flexible ability to learn new concepts from just a few examples. In fact, the poor performance of older machine learning systems on few-shot learning tasks has been presented as evidence that human learning often relies on rapid model-building based on prior knowledge rather than mere pattern recognition (Lake et al. 2017). Unlike older systems, however, LLMs trained on next-token prediction excel at in-context learning and few-shot learning specifically (Mirchandani et al. 2023). This capacity appears to be highly correlated with model size, being mostly observed in larger models such as GPT-3 (Brown et al. 2020). The capacity for zero-shot learning, in turn, is particularly enhanced by fine-tuning with RLHF. Models such as ChatGPT can fairly robustly pick up on point-blank questions and instructions without needing careful prompt design and lengthy examples of the tasks to be completed.
LLMs have been applied to many tasks within and beyond natural language processing, demonstrating capabilities that rival or even exceed those of task-specific models. In the linguistic domain, their applications range from translation (Wang, Lyu, Ji, Zhang, Yu, Shi & Tu 2023), summarization (Zhang et al. 2023), question answering (OpenAI 2023a), and sentiment analysis (Kheiri & Karimi 2023) to free-form text generation including creative fiction (Mirowski et al. 2023). They also power advanced dialogue systems, lending voice to modern chatbots like ChatGPT that greatly benefit from fine-tuning with RLHF (OpenAI 2022). Beyond traditional NLP tasks, LLMs have demonstrated their ability to perform tasks such as generating code (Savelka, Agarwal, An, Bogart & Sakr 2023), solving puzzles (Wei et al. 2022), playing text-based games (Shinn et al. 2023), and providing answers to math problems (Lewkowycz et al. 2022). The versatile capacities of LLMs make them potentially useful for knowledge discovery and information retrieval, since they can act as sophisticated search engines that respond to complex queries in natural language. They can be used to create more flexible and context-aware recommendation systems (He et al. 2023), and have even been proposed as tools for education (Kasneci et al. 2023), research (Liang et al. 2023), law Savelka, Ashley, Gray, Westermann & Xu (2023), and medicine (Thirunavukarasu et al. 2023), aiding in the generation of preliminary insights for literature review, diagnosis, and discovery.
[6] Note that parallel processing in Transformers is applicable within a predefined maximum sequence length or input window, beyond which the model cannot process without truncating or segmenting the input. This is due to the self-attention mechanism’s quadratic growth in computational and memory requirements with respect to the sequence length.







{kind=link}