:::info
Authors:
(1) Haolong Li, Tongji Universiy and work done during internship at ByteDance ([email protected]);
(2) Yu Ma, Seed Foundation, ByteDance ([email protected]);
(3) Yinqi Zhang, East China Normal University and work done during internship at ByteDance ([email protected]);
(4) Chen Ye (Corresponding Author), ESSC Lab, Tongji Universiy ([email protected]);
(5) Jie Chen, Seed Foundation, ByteDance and a Project Leader ([email protected]).
:::
Table of Links
Abstract and 1 Introduction
2 Problem Definition
2.1 Arithmetical Puzzle Problem
2.2 Data Synthesizing
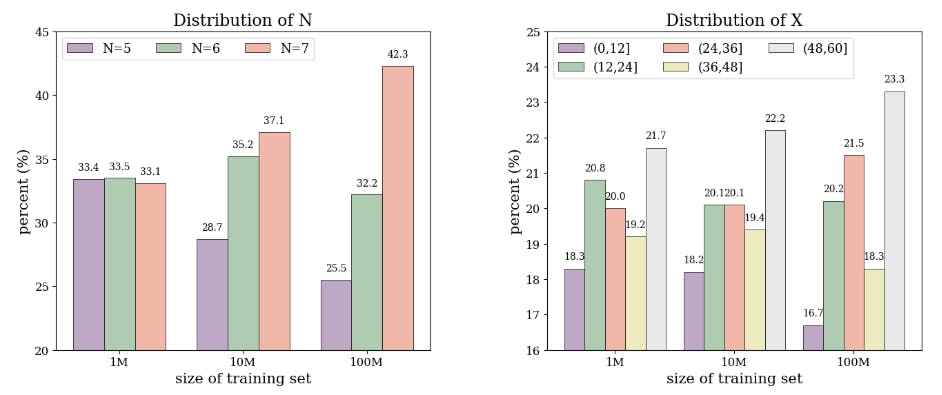
2.3 Dataset
3 Model
4 Experiments
4.1 Evaluation
4.2 Results
4.3 Case Studies
5 Conclusion and Acknowledgements
6 Limitations
7 Ethics Statement and References
A Appendix
A.1 Hyperparameter Settings
A.2 Evaluation of the Base Model
A.3 Case Study
A.4 Visualization of the Proposed Puzzle
Abstract
Large Language Models (LLMs) have shown excellent performance in language understanding, text generation, code synthesis, and many other tasks, while they still struggle in complex multi-step reasoning problems, such as mathematical reasoning. In this paper, through a newly proposed arithmetical puzzle problem, we show that the model can perform well on multi-step reasoning tasks via fine-tuning on high-quality synthetic data. Experimental results with the open-llama-3B model on three different test datasets show that not only the model can reach a zero-shot pass@1 at 0.44 on the in-domain dataset, it also demonstrates certain generalization capabilities on the out-of-domain datasets. Specifically, this paper has designed two out-of-domain datasets in the form of extending the numerical range and the composing components of the arithmetical puzzle problem separately. The fine-tuned models have shown encouraging performance on these two far more difficult tasks with the zero-shot pass@1 at 0.33 and 0.35, respectively.
1 Introduction
Large Language Models (LLMs), as zero-shot and multi-task learners, have shown extraordinary capabilities across a variety of natural language tasks (Vaswani et al., 2017; Schulman et al., 2017; Radford et al., 2019; Ziegler et al., 2019; Brown et al., 2020; Kojima et al., 2022; Park et al., 2023; Chowdhery et al., 2023; Rafailov et al., 2024). However, even the most advanced LLMs face challenges when it comes to tackling complex multi-step reasoning problems, such as mathematical and scientific reasoning (Koncel-Kedziorski et al., 2016; Cobbe et al., 2021; Hendrycks et al., 2021; Wei et al., 2022; Chen et al., 2022; Gao et al., 2023; Trinh et al., 2024). This comes from three main reasons: firstly, mathematical reasoning often requires quantitative multiple steps of deduction, since a single logical error is enough to derail a much larger solution (Lightman et al., 2023). Secondly, the lack of high-quality data limits LLMs’ ability to generalize and excel in mathematical reasoning tasks. Lastly, LLMs encounter difficulty in extrapolation, as they struggle to apply reasoning skills when solving unseen mathematical problems.
Many prior research has explored along these challenges. GPT-4 (Achiam et al., 2023), LLaMA (Touvron et al., 2023a,b), Gemini (Team et al., 2023), Minerva (Lewkowycz et al., 2022), Llemma (Azerbayev et al., 2023), Mistral (Jiang et al., 2023), WizardMath (Luo et al., 2023), MAMMOTH (Yue et al., 2023), ToRA (Gou et al., 2023) and Deepseek (Bi et al., 2024; Guo et al., 2024; Lu et al., 2024) have emerged as dominant models in popular mathematical reasoning benchmarks such as GSM8K (Cobbe et al., 2021), MATH (Hendrycks et al., 2021), CMATH (Wei et al., 2023) and AGIEval (Zhong et al., 2023). Moreover, process supervision and verifiers (Cobbe et al., 2021; Li et al., 2023; Uesato et al., 2022; Lightman et al., 2023; Yu et al., 2023) at the step level have also obtained widespread attention. However, mathematical extrapolation, particularly in terms of abstract forms, is often overlooked.
In this paper, we address the aforementioned challenges by introducing a novel and challenging arithmetical puzzle problem and making an initial attempt to solve them. Specifically, we propose a puzzle that needs multi-step calculations to generate a correct solution. Meanwhile, a data synthesis pipeline is developed to automatically generate a vast amount of high-quality data for supervised fine-tuning (SFT). And a series of LLMs based on open-llama-3B (Touvron et al., 2023a) are finetuned on this synthetic dataset. Furthermore, to demonstrate the reasoning abilities in extrapolation,
we have designed two out-of-domain benchmarks in the form of extending the numerical range and the composing components of the arithmetical puzzle problem. For the purpose of fair evaluation, we have restricted our models to greedy sampling in a zero-shot setting and provided a corresponding verifier. Our data scaling experiments demonstrate that as the amount of synthetic data grows, in-domain zero-shot pass@1 increases from 0.22 to 0.44, while the out-of-domain zero-shot pass@1 increases from 0.14/0.17 to 0.33/0.35.
Our major contributions can be concluded as: (1) We propose a novel arithmetical puzzle problem with corresponding data synthesis pipeline and out-of-domain benchmarks, to verify the multi-step reasoning and extrapolation capabilities of LLMs fine-tuned on synthetic data. (2) Experiments indicate that increasing the amount of high-quality synthetic data leads to performance enhancements across in-domain and out-of-domain datasets. (3) A comprehensive case study has been performed.
:::info
This paper is available on arxiv under CC BY-NC-SA 4.0 Deed (Attribution-Noncommercial-Sharelike 4.0 International) license.
:::






{kind=link}