Authors:
(1) Albert Gu, Machine Learning Department, Carnegie Mellon University and with equal contribution;
(2) Tri Dao, Department of Computer Science, Princeton University and with equal contribution.
Table of Links
Abstract and 1 Introduction
2 State Space Models
3 Selective State Space Models and 3.1 Motivation: Selection as a Means of Compression
3.2 Improving SSMs with Selection
3.3 Efficient Implementation of Selective SSMs
3.4 A Simplified SSM Architecture
3.5 Properties of Selection Mechanisms
3.6 Additional Model Details
4 Empirical Evaluation and 4.1 Synthetic Tasks
4.2 Language Modeling
4.3 DNA Modeling
4.4 Audio Modeling and Generation
4.5 Speed and Memory Benchmarks
4.6 Model Ablations
5 Discussion
6 Conclusion and References
A Discussion: Selection Mechanism
B Related Work
C Mechanics of Selective SSMs
D Hardware-aware Algorithm For Selective SSMs
E Experimental Details and Additional Results
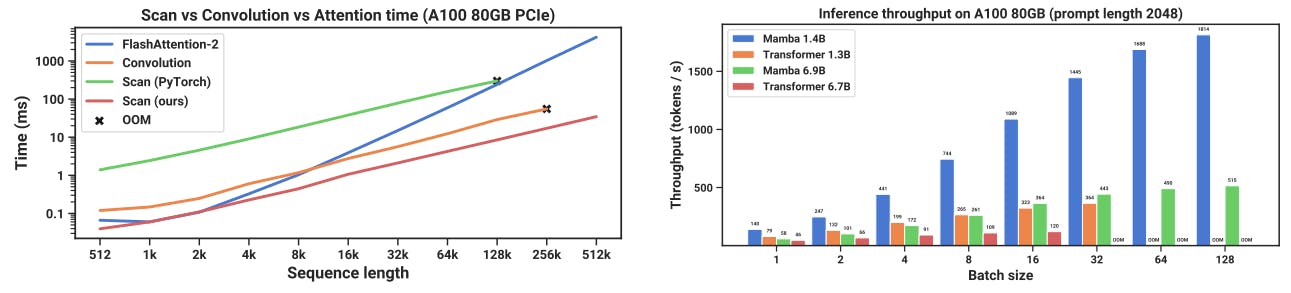
4.5 Speed and Memory Benchmarks
We benchmark the speed of the SSM scan operation (state expansion N = 16), as well as the end-to-end inference throughput of Mamba, in Figure 8. Our efficient SSM scan is faster than the best attention implementation that we know of (FlashAttention-2 (Dao 2023)) beyond sequence length 2K, and up to 20-40× faster than a standard scan implementation in PyTorch. Mamba achieves 4-5× higher inference throughput than a Transformer of similar size, since without the KV cache it can use much higher batch sizes. For example, a Mamba-6.9B (untrained) would have higher inference throughput than a 5× smaller Transformer-1.3B. Details in Appendix E.5, which additionally includes a benchmark of memory consumption.








{kind=link}