Table of Links
Abstract and 1. Introduction
-
Related Work
-
Task, Datasets, Baseline
-
RQ 1: Leveraging the Neighbourhood at Inference
4.1. Methods
4.2. Experiments
-
RQ 2: Leveraging the Neighbourhood at Training
5.1. Methods
5.2. Experiments
-
RQ 3: Cross-Domain Generalizability
-
Conclusion
-
Limitations
-
Ethics Statement
-
Bibliographical References
4.2. Experiments
4.2.1. Implementation Details
We follow the hyperparameters for baseline as described in Kalamkar et al. 2022. We use the BERT base model to obtain the token encodings. We employ a dropout of 0.5, maximum sequence length of 128, LSTM dimension of 768, attention context dimension of 200. We sweep over learning rates {1e5, 3e-5, 5e-5. 1e-4, 3e-4} for 40 epochs with Adam optimizer (Kingma and Ba, 2014) to derive the best model based on validation set performance. For all our inference variants, we carry a grid search over the interpolation factor (λ) in increments of 0.1 in the range of [0,1] to choose the best model based on Macro-F1 on validation set. For KNN and multiple prototypes, we vary k over powers of 2 from 8 till 256.
4.2.2. Results
In Table 1, we present the macro-F1 and micro-F1 scores for both the baseline and the interpolation variants. We observe a significant improvement when using kNN interpolation across all datasets, particularly in the more challenging macro-F1 metric, which accounts for label imbalances. On the other hand, single prototype interpolation mitigates memory footprint issue of kNN by storing one representation per rhetorical role but leads to performance degradation compared to kNN. This decline results from oversimplification, as a single prototype may struggle to capture the diverse aspects within each rhetorical role, particularly when instances of the same label are dispersed across the embedding space. This is evident in the Paheli dataset, where no improvement over the baseline is observed. Interpolation with multiple prototypes balances memory efficiency and label variation capture. While it slightly underperforms kNN interpolation in Paheli and M-CL datasets, it outperforms kNN in Build and M-IT. This can be attributed to a smoothing effect that reduces noise or human label variations in the kNN-based approach, particularly evident in datasets with low inter-annotator agreements (Build and M-IT). These results affirm our hypothesis that straightforward interpolation using training set examples during inference can boost the performance of rhetorical role classifiers.
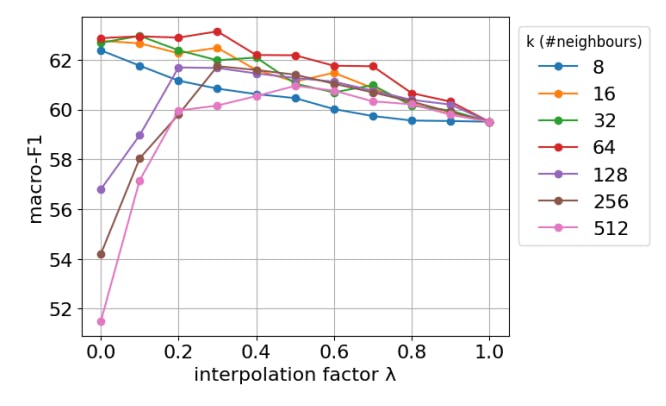
Sensitivity of interpolation In Figure 1, we present the macro-F1 score for the M-CL dataset using kNN interpolation, while varying the interpolation coefficient λ and the number of neighbors




’k’. Here, λ values of 0 and 1 correspond to predictions solely from interpolation and the baseline model, respectively. We observe that performance initially improves as ’k’ increases, signifying that incorporating more neighbors boosts confidence by including closely similar examples. However, performance starts to decline with higher ’k’, which can be attributed to a large number of neighbours introducing noise with low inter-annotator agreement, suggesting a need for a addressing this task a multilabel classification. On the other hand, reducing λ consistently enhances performance, particularly for lower k, showcasing the model’s capacity to rely solely on semantically similar instances for label prediction. With higher k, we notice a decline in performance at lower λ values beyond a certain optimal point, which is related to the label variation problem exacerbated by a larger number of neighbours. Similar trends are observed with other interpolations.
Authors:
(1) Santosh T.Y.S.S, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]);
(2) Hassan Sarwat, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]);
(3) Ahmed Abdou, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]);
(4) Matthias Grabmair, School of Computation, Information, and Technology; Technical University of Munich, Germany ([email protected]).
This paper is







{kind=link}