Authors:
(1) Anthi Papadopoulou, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway and Corresponding author ([email protected]);
(2) Pierre Lison, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
(3) Mark Anderson, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
(4) Lilja Øvrelid, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway;
(5) Ildiko Pilan, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway.
Table of Links
Abstract and 1 Introduction
2 Background
2.1 Definitions
2.2 NLP Approaches
2.3 Privacy-Preserving Data Publishing
2.4 Differential Privacy
3 Datasets and 3.1 Text Anonymization Benchmark (TAB)
3.2 Wikipedia Biographies
4 Privacy-oriented Entity Recognizer
4.1 Wikidata Properties
4.2 Silver Corpus and Model Fine-tuning
4.3 Evaluation
4.4 Label Disagreement
4.5 MISC Semantic Type
5 Privacy Risk Indicators
5.1 LLM Probabilities
5.2 Span Classification
5.3 Perturbations
5.4 Sequence Labelling and 5.5 Web Search
6 Analysis of Privacy Risk Indicators and 6.1 Evaluation Metrics
6.2 Experimental Results and 6.3 Discussion
6.4 Combination of Risk Indicators
7 Conclusions and Future Work
Declarations
References
Appendices
A. Human properties from Wikidata
B. Training parameters of entity recognizer
C. Label Agreement
D. LLM probabilities: base models
E. Training size and performance
F. Perturbation thresholds
6.2 Experimental Results
We first evaluate the five privacy risk indicators using PII spans manually labeled by human annotators from both the TAB corpus and the Wikipedia biographies. The results are shown in Table 5. The approaches based on LLM probabilities and span classification were trained on the corresponding training set (either Wikipedia or TAB), and the threshold of the perturbation-based method was similarly adjusted from the training set. The web search results rely on the two alternatives techniques presented in Section 5.5, respectively based on the intersection of URLs or the estimated number of hits. We also provide the results obtained with a simple baseline that masks all PII spans.
We then evaluate the risk indicators with the PII spans actually detected by the privacy-oriented entity recognizer described in Section 4, thereby enabling us to assess the end-to-end performance of the proposed approaches. The results are shown in Table 6. Note that, in this setup, the majority rule baseline (which masks all PII spans) leads to recall scores lower than 1 due to detection errors arising from the privacy-oriented entity recognizer.
6.3 Discussion
We now discuss the experimental results of each privacy risk indicator one by one.
LLM probabilities
We can observe that the AutoML model, which consists of an ensemble of supervised classifiers such as decision trees with hyper-parameters optimized on the development set, outperforms a simpler logistic regression model. In other words, the task of predicting high-risk text spans given the aggregated probabilities obtained from a large language model seems to require a non-linear decision boundary.
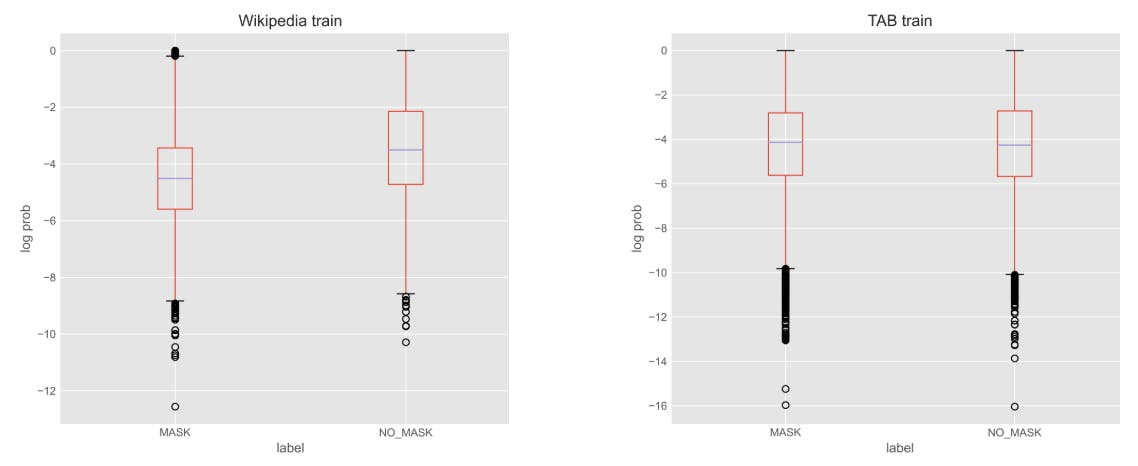
We also notice a substantial difference between the Wikipedia biographies and the TAB corpus. A closer look at the token log-probabilities factored by masking decision, as shown in Figure 3, is particularly instructive. While the PII spans from the Wikipedia biographies show a clear difference between the log-probabilities of the masked and non-masked tokens, this is not the case for the TAB corpus[8].


The classifier reaches its optimal performance relatively quickly, after observing about 1 % of the total training set size in both corpora. Ablation experiments also show that the most important feature for the classifier is the PII type, as some types are masked by human annotators much more often than others.
Span classification
The span classification approach improves the classification performance compared to the classifier trained only on the aggregated probabilities from the LLM, in particular for the Text Anonymization Benchmark.
As training this classifier includes fine-tuning a large language model, it requires slightly more training data than the classifier based exclusively on LLM probabilities and PII types. We observe experimentally that the classifier performance stabilizes at around 10% of training instances for both datasets. Based on ablation experiments, we also see that the outputs of the fine-tuned language model play a major role in the final prediction, along with the PII type.


Perturbations
Despite its theoretical benefits (such as the possibility to directly assess the extent to which a PII span contributes to predicting a direct personal identifier), the perturbation-based method performs poorly, and does not seem to improve upon the majority rule baseline. Indeed, the perturbation mechanism, in combination with the cost function employed to fix the threshold on the log-probabilities, leads to masking the vast majority of text spans.
Sequence labelling
Overall, this approach seems to provide the best balance between precision and recall scores, which is to be expected from a large language model fined-tuned on manually labeled data. In contrast to the span classification method, which only considers the tokens inside the PII span itself, the sequence labelling approach can take into account the surrounding context of each span.


One should note that the results in Tables 5 and 6 are obtained with a default threshold of 0.5 on the masking probability. This threshold can, of course, be adjusted to increase the relative importance of recall scores, as is often done in text sanitization to increase the cost of false negatives.
The method based on partial matches, which considers a PII span as risky if at least one constituting token is marked as risky, provides the best results. We also observe that the results on the Wikipedia biographies are lower than those obtained for TAB. This is likely to be due to the smaller number of biographies available for training (453 short texts) compared to the 1014 documents in the training set of TAB.
Web Search
Table 5 shows a clear difference between using intersection of URLs and using the estimated number of hits, with the first showing a very low recall score while the latter shows a more balanced performance between precision and recall. The intersection of URLs, though, provides better explainability than the number of hits, as one can point the user to the actual URL(s) that contribute to the re-identification.
While using the intersection of URLs is hampered by the limitation on the number of pages, the chances of a meaningful crossover between target and entities in a text diminishes the deeper into the tail of web results we delve. A possible solution is to try to analyze the text found in the URLs in order to evaluate whether the target individual is mentioned or not.
On the other hand, the number of hits up to a limit is a better approximation of risky entities, despite the unreliability of the number of hits as given by the API. Note, though, the restrictions we have already mentioned in Section 5.5 that are bound to affect the performance. Even though the web can be seen as a very useful and detailed approximation of potential background knowledge an attacker could have and use for re-identification purposes, the technical details of utilizing this make it hard to explain clearly the reason behind the performance.


Summary
As can be expected, privacy risk indicators trained on manually labelled data, in particular sequence labelling, provide the best performance when comparing the spans identified as high risk with expert annotations. Text data annotated with masking decisions is, however, scarce to non-existent for many text sanitization domains.
When it comes to data utility, we also observe that the precision score weighted by information content (Pw) is higher than the regular precision score for all privacy risk indicators. As argued in Pilan et al. (2022), this weighted score is more informative than the basic precision score as it takes into account the informativeness of each token. As a consequence, a higher weighted precision score means that overmasking tends to occur on less informative tokens.
6.4 Combination of Risk Indicators
Finally, we also evaluate the performance of the privacy risk indicators in combination. More specifically, we consider a manually detected PII span as high-risk if it has been marked as such by at least one, two or three risk indicators.[9] The resulting performance is shown in Table 7.
Although the combination of privacy risk indicators with ≥ 3 positive signals leads to overmasking, it does detect all direct identifiers and virtually all quasi-identifiers while retaining a higher precision than the majority rule baseline. This high recall is important in text sanitization, as the cost of ignoring a high-risk PII span is much higher than the cost of a false positive. While overmasking does slightly reduce the data utility (by making the text less readable or stripped of some useful content), the presence of a false negative implies that it remains possible to re-identify the individual(s) in question, and that their privacy is therefore not fully ensured.
[8] At least when aggregating over all PII types. If we do, however, factor those log-probabilities by PII type, we do notice a difference in log-probabilities for a number of PII types.






{kind=link}