
Amazon Bedrock Agents are like smart assistants for your AWS infrastructure — they can reason, decide what to do next, and trigger actions using Lambda functions.
In this article, I’ll show how I built a Supervisor Agent that orchestrates multiple AWS Lambdas to:
-
List EC2 instances,
-
Fetch their CPU metrics from CloudWatch,
-
Combine both results intelligently — all without the agent ever calling AWS APIs directly.
By the end, you’ll understand how Bedrock Agents work, how to use action groups, and how to chain Lambdas through a supervisor function — a clean, scalable pattern for multi-step automation.
Let’s check on the diagram and with other example of what the agent is, for better visuality and understanding:
User makes a call to the Bedrock agent (1) with some task, let’s say, “how much of TVs do you have in stock?”. The agent knows by a defined prompt that if the question is related to checking stock status, they need to call (2) the “database“ action group (3, AG). In the database AG, we defined a lambda function to use (4), and this lambda will check the status in the DynamoDB table (5), get the response (6,7) and return the answer to the user (8).
Let’s check one more example: 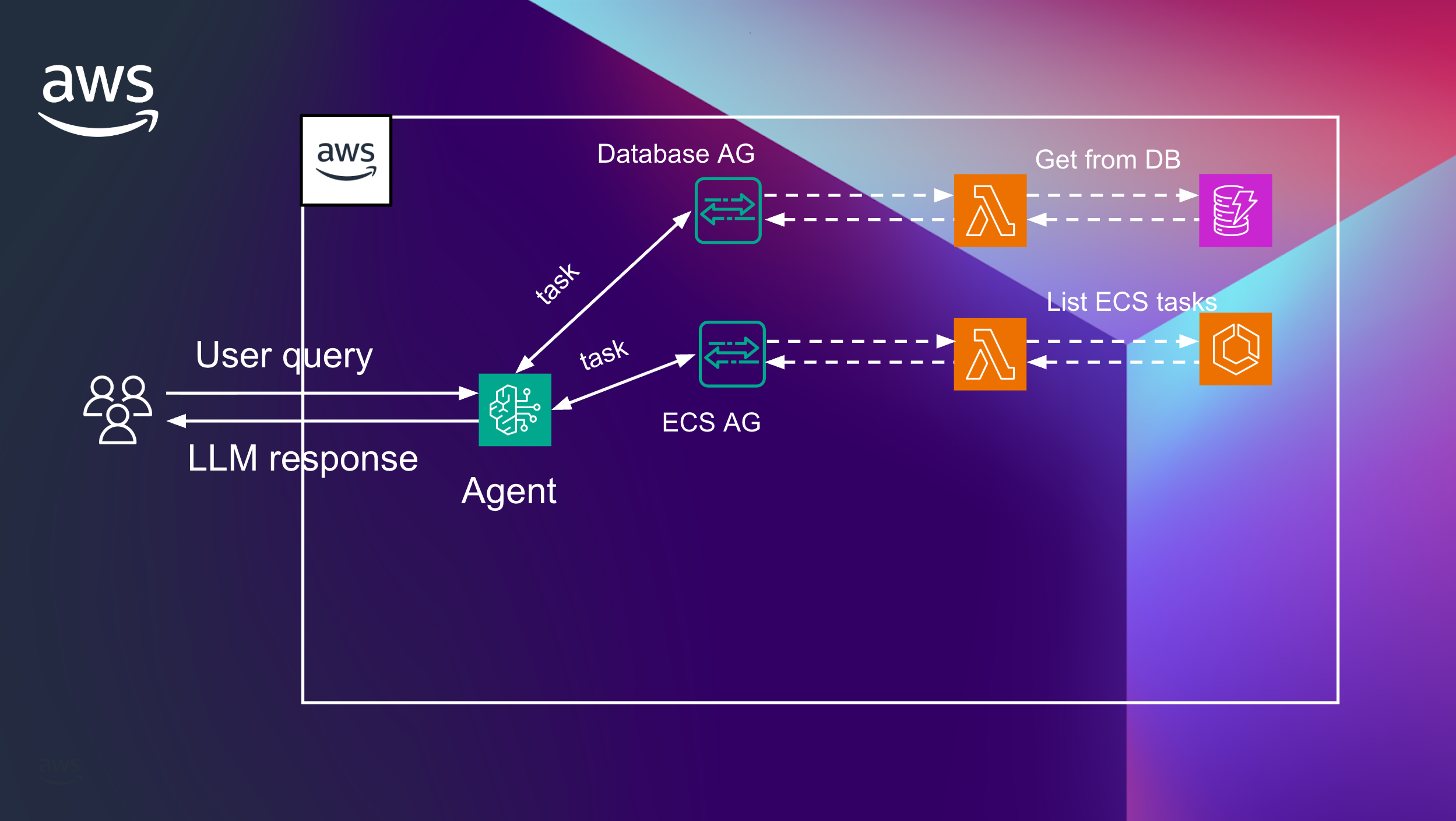
Each agent can have multiple action groups, for example, we want to get information about some AWS resources, like list all ECS tasks, the logic is the same as for the previous one. To explain the agent that AG to call – we need to use the prompt, will explain later.
And more example:
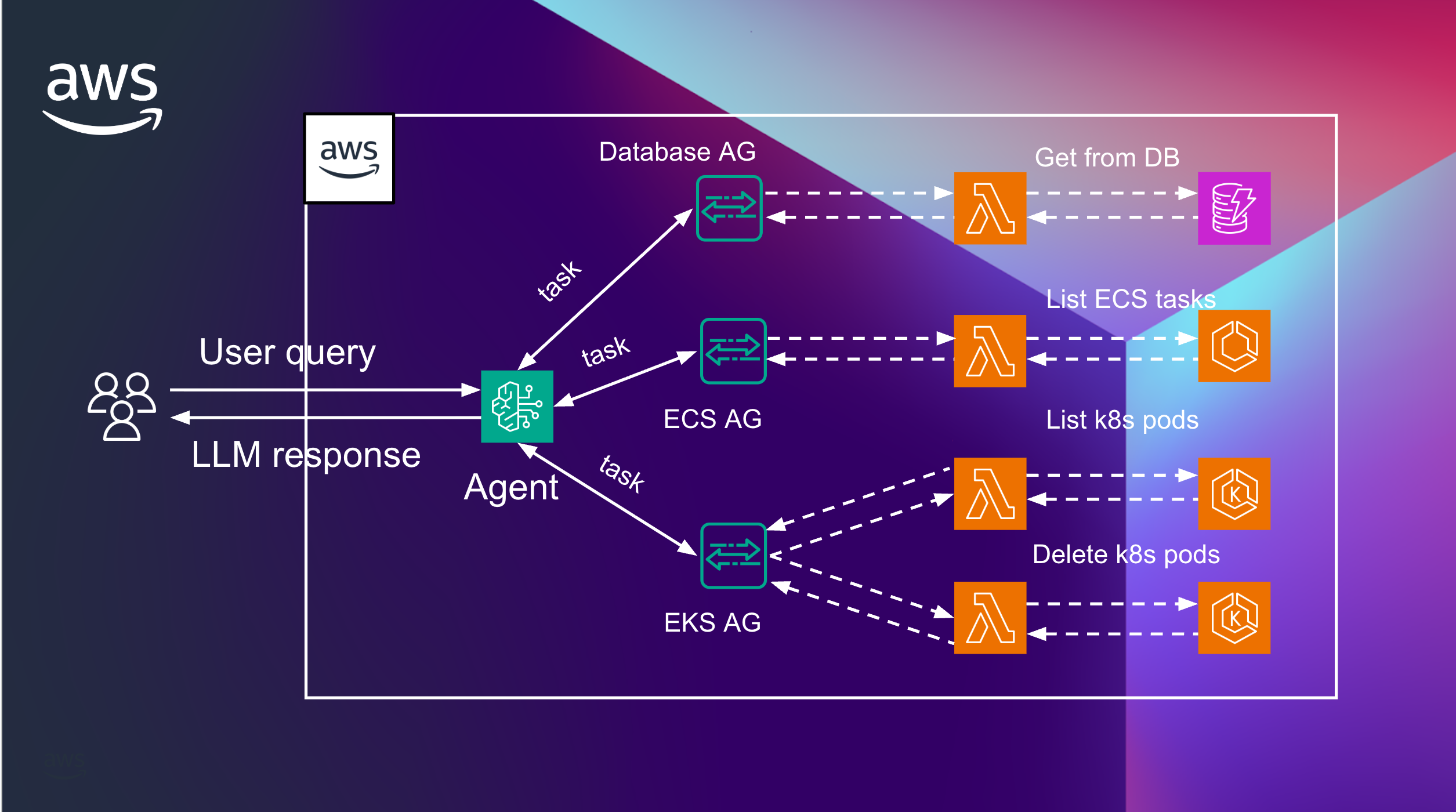
We added one more AG with EKS action groups. As you see here, each action group can have more than one lambda function to make requests to. In this example, it’s listing and deleting resources from some existing K8S cluster.
The action group and lambda function can have any functionality, even if you need to get data from a third-party API to fetch weather data or flight ticket availability.
I hope it’s a bit clear now, and let’s get back to our supervisor agent setup:
In AWS console, open Bedrock → Agents → Create agent
Give it a name and Create
Once created, you can change the model if you want to or keep Claude by default. I will change to Nova Premier 1.0
Add description and instructions for the Agent. The action group we will create on the next step
You are the main AWS Supervisor Agent.
Goal: Help analyze AWS infrastructure.
Action Groups:
- ec2: list_instances → returns instance list + instanceIds
Rules:
- Never call AWS APIs directly.
- For EC2:
- Call ec2_listinstances
Always use before actions.
Note:
ec2 – action group name
list_instances – function name, as I mentioned previously – you can have multiple functions per each action group
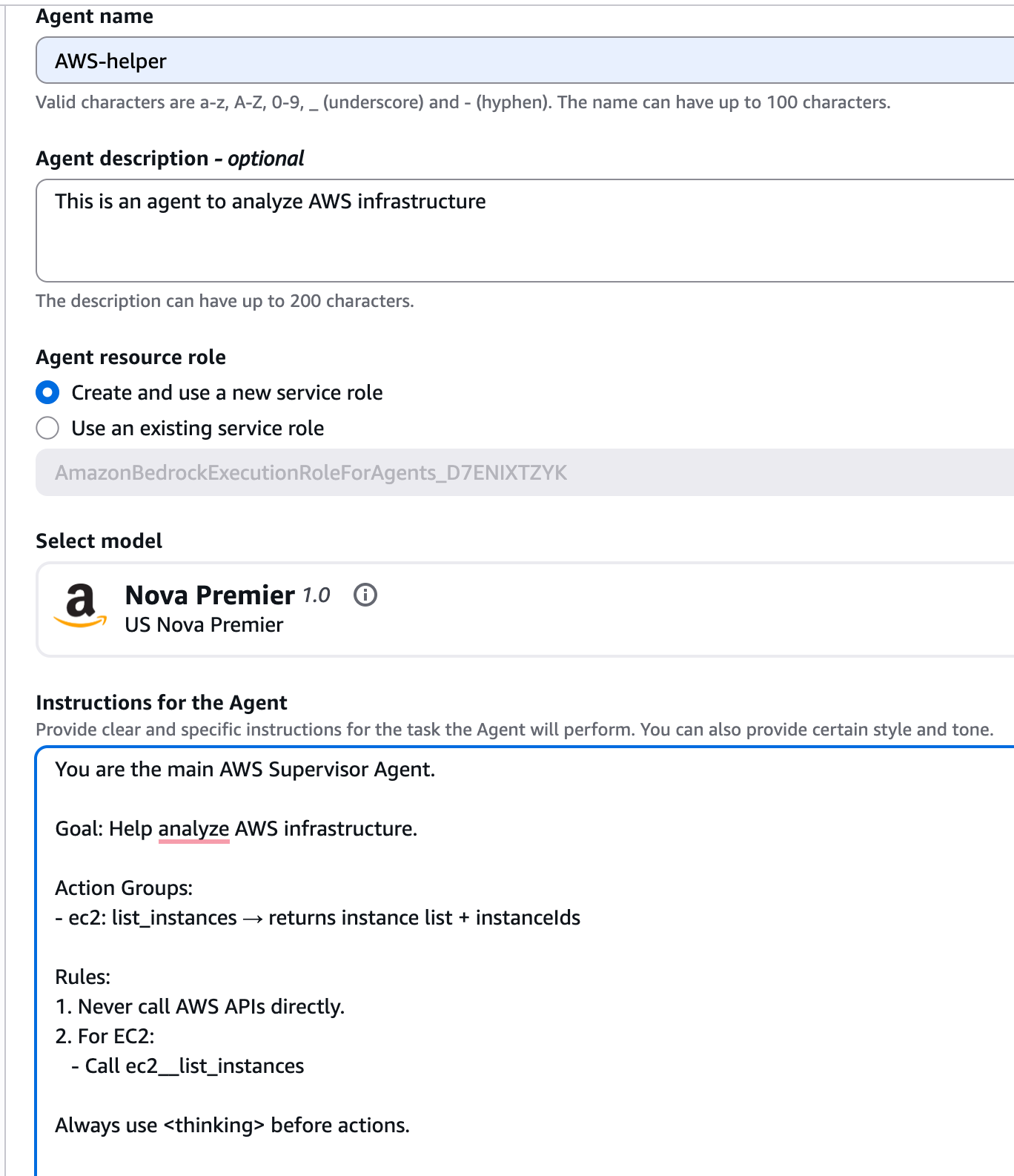
And click the “Save”

And “Prepare” buttons in the top. Prepare will be active once you save.
Scroll down to the actions group → add

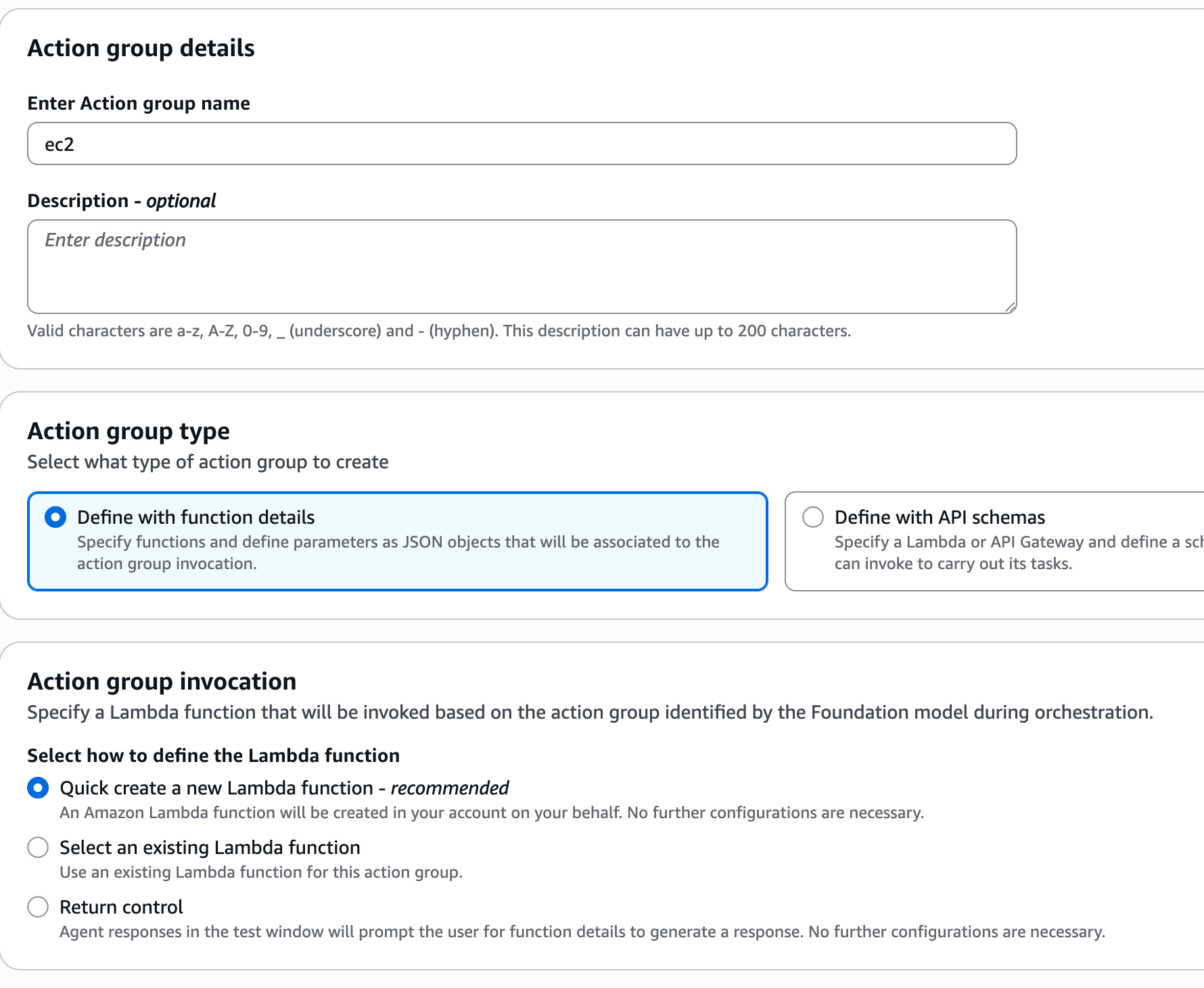
Name – EC2. Action group. invocation – create a new lambda function, where list_instances must be the same as we defined in the agent instructions
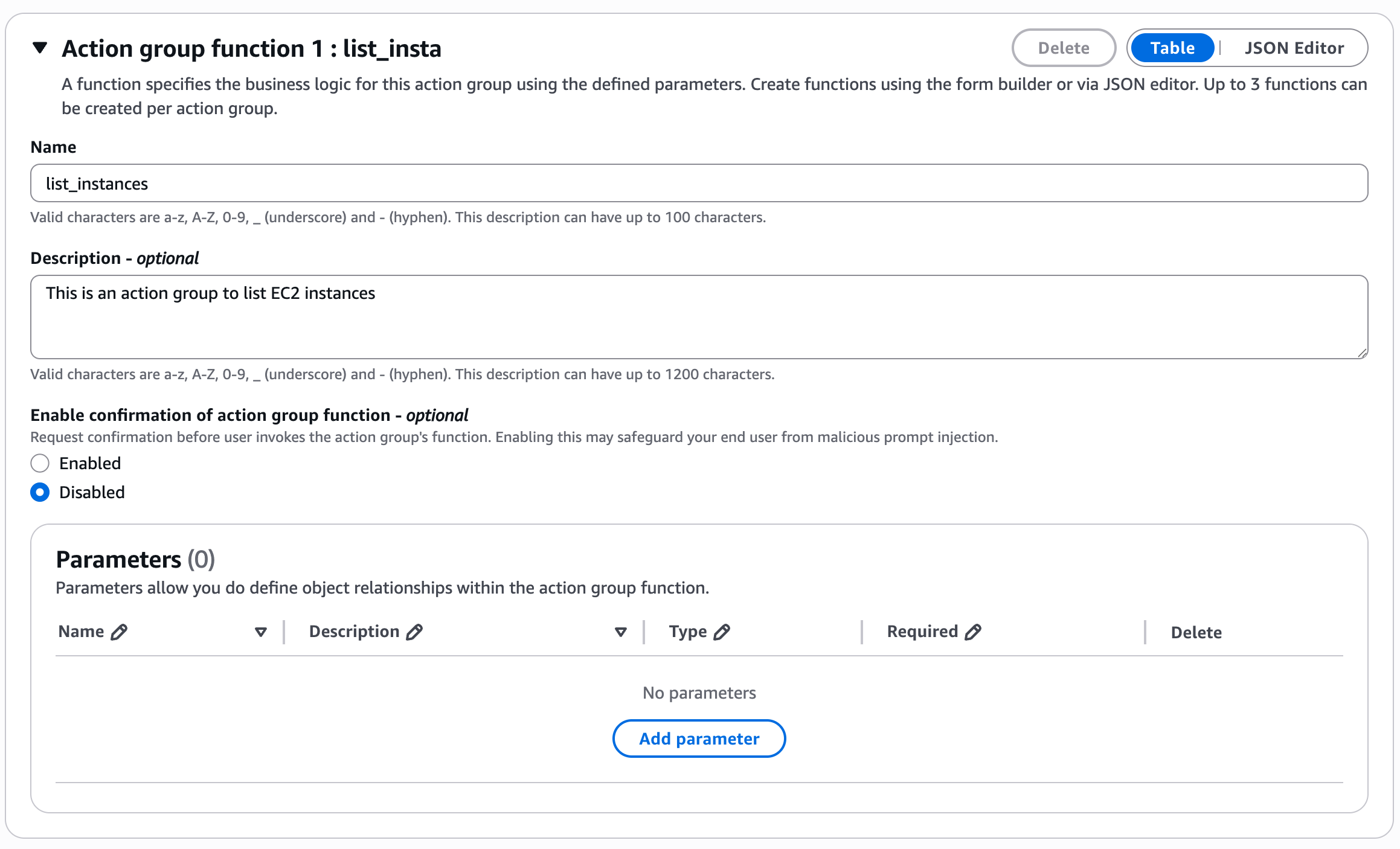
Add action group name and description, click Create and again “Save“ and “Prepare“.
Go to your lambda function, Bedrock created the function with EC2 prefix in the name and add this code:
import logging
from typing import Dict, Any
from http import HTTPStatus
import boto3
logger = logging.getLogger()
logger.setLevel(logging.INFO)
ec2_client = boto3.client('ec2')
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
"""
AWS Lambda handler for processing Bedrock agent requests related to EC2 instances.
Supports:
- Listing all EC2 instances
- Describing a specific instance by ID
"""
try:
action_group = event['actionGroup']
function = event['function']
message_version = event.get('messageVersion', 1)
parameters = event.get('parameters', [])
response_text = ""
if function == "list_instances":
# List all EC2 instances
instances = ec2_client.describe_instances()
instance_list = []
for reservation in instances['Reservations']:
for instance in reservation['Instances']:
instance_list.append({
'InstanceId': instance.get('InstanceId'),
'State': instance.get('State', {}).get('Name'),
'InstanceType': instance.get('InstanceType'),
'PrivateIpAddress': instance.get('PrivateIpAddress', 'N/A'),
'PublicIpAddress': instance.get('PublicIpAddress', 'N/A')
})
response_text = f"Found {len(instance_list)} EC2 instance(s): {instance_list}"
elif function == "describe_instance":
# Expect a parameter with the instance ID
instance_id_param = next((p for p in parameters if p['name'] == 'instanceId'), None)
if not instance_id_param:
raise KeyError("Missing required parameter: instanceId")
instance_id = instance_id_param['value']
result = ec2_client.describe_instances(InstanceIds=[instance_id])
instance = result['Reservations'][0]['Instances'][0]
response_text = (
f"Instance {instance_id} details: "
f"State={instance['State']['Name']}, "
f"Type={instance['InstanceType']}, "
f"Private IP={instance.get('PrivateIpAddress', 'N/A')}, "
f"Public IP={instance.get('PublicIpAddress', 'N/A')}"
)
else:
response_text = f"Unknown function '{function}' requested."
# Format Bedrock agent response
response_body = {
'TEXT': {
'body': response_text
}
}
action_response = {
'actionGroup': action_group,
'function': function,
'functionResponse': {
'responseBody': response_body
}
}
response = {
'response': action_response,
'messageVersion': message_version
}
logger.info('Response: %s', response)
return response
except KeyError as e:
logger.error('Missing required field: %s', str(e))
return {
'statusCode': HTTPStatus.BAD_REQUEST,
'body': f'Error: {str(e)}'
}
except Exception as e:
logger.error('Unexpected error: %s', str(e))
return {
'statusCode': HTTPStatus.INTERNAL_SERVER_ERROR,
'body': f'Internal server error: {str(e)}'
}
NOTE: the response of the function must be in Bedrock-specific format, details can be found in the documentation:
https://docs.aws.amazon.com/bedrock/latest/userguide/agents-lambda.html
After you updated your function code – go to the function Configuration → permissions → role name create a new inline policy:
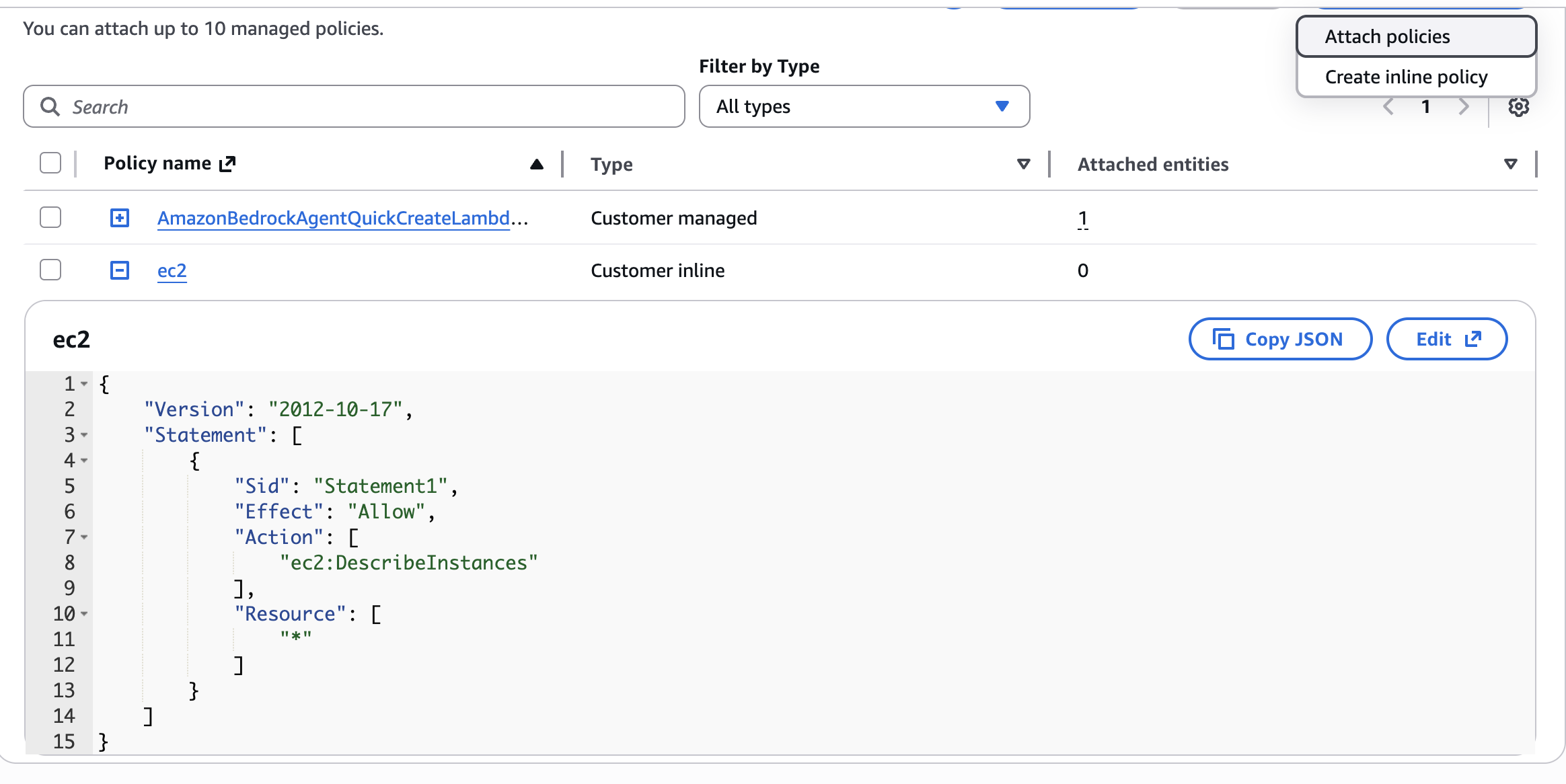 As JSON:
As JSON:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances"
],
"Resource": [
"*"
]
}
]
}
Now we can go back to our agent and click “Test”, enter text to check if it actually works:
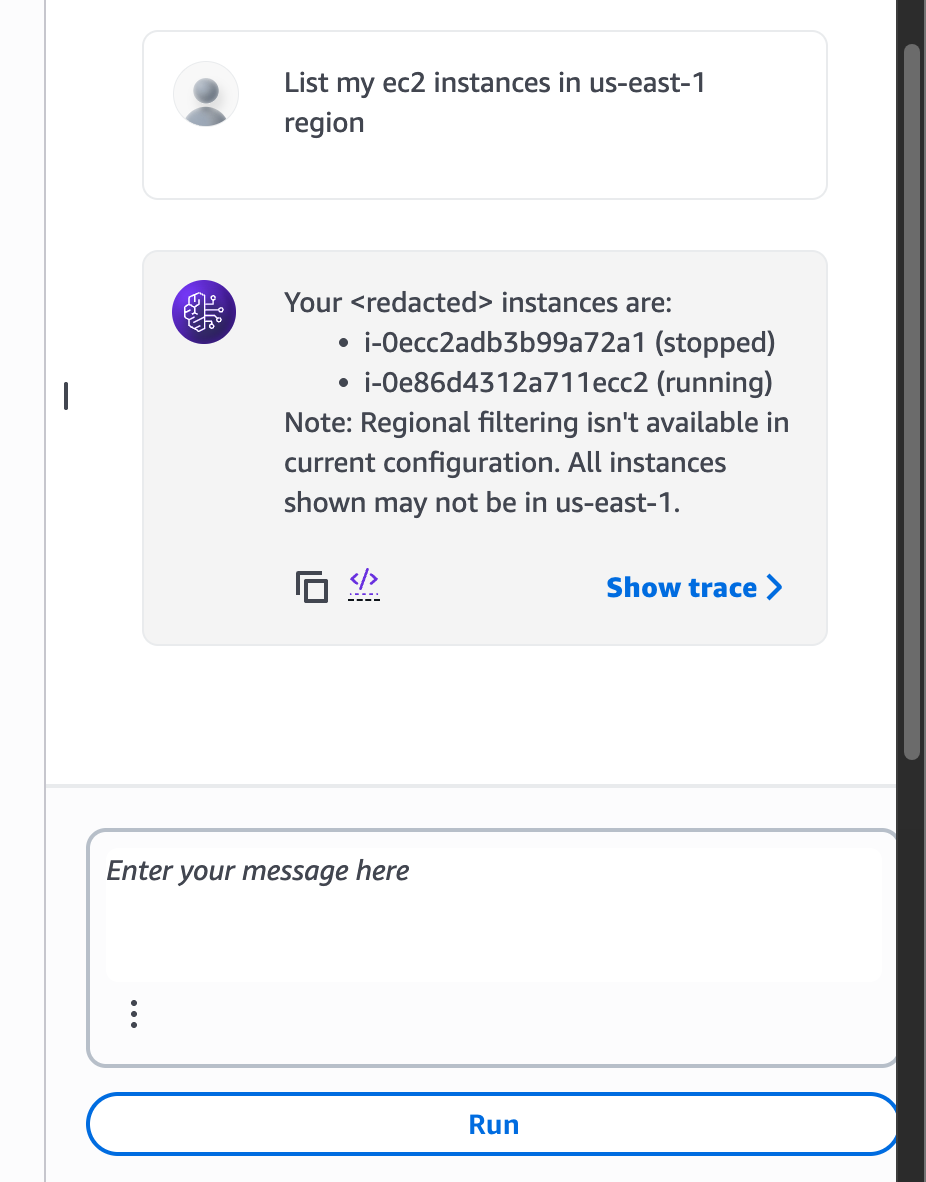
Cool! The first action group works as expected, lets add one more action group to list cloudwatch metrics:
Name of the action group – cloudwatch
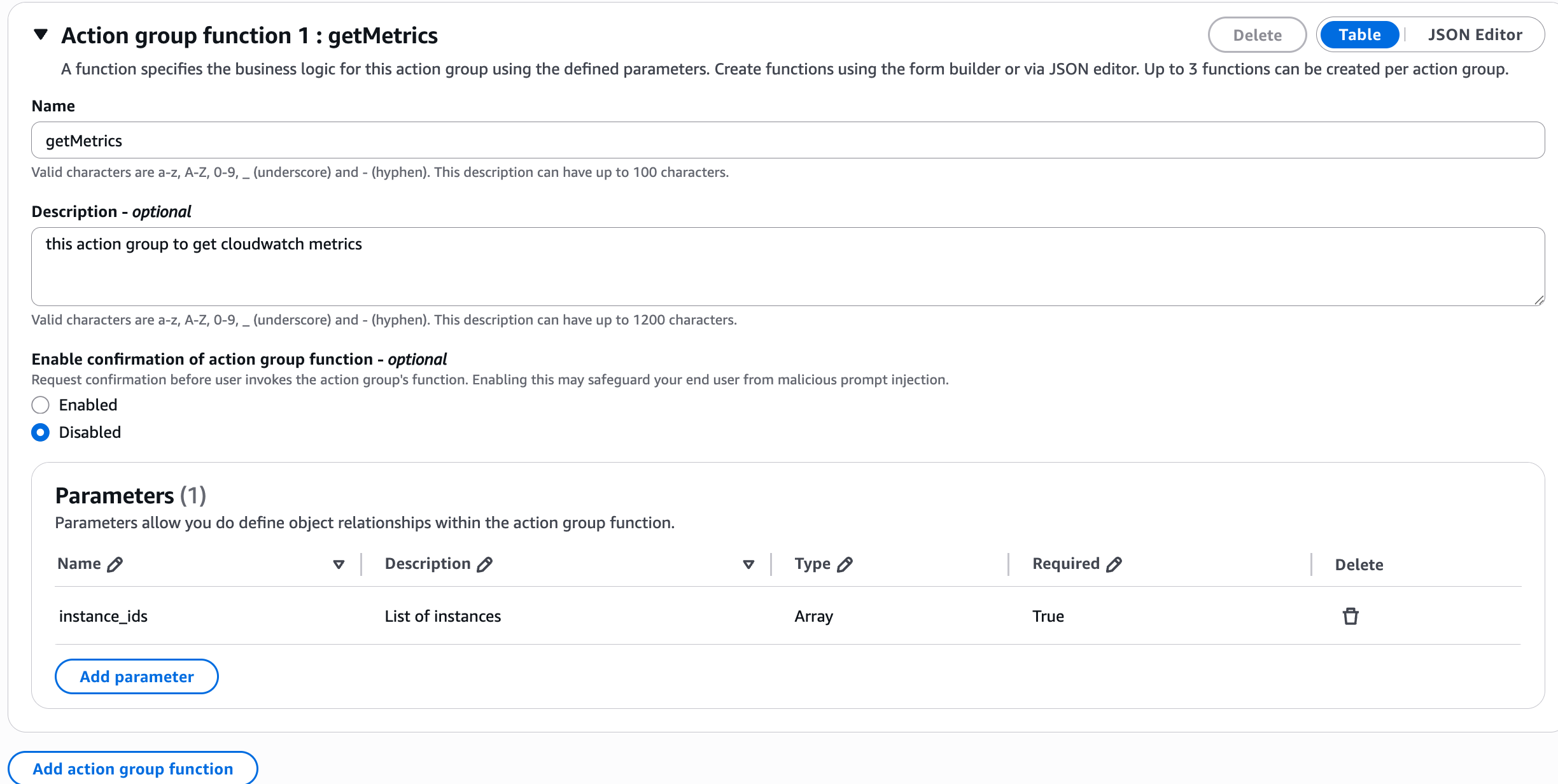
Name of the function is getMetrics, add description and parameters, since this lambda must know the instance or intances to check metrics of
Update the agent prompt to explain how we want to use the new action group, and click “Save” and “Prepare” again
You are the main AWS Supervisor Agent.
Goal: Help analyze AWS infrastructure.
Action Groups:
- ec2: describeInstances → returns instance list + instanceIds
- cloudwatch: getMetrics → needs instance_ids
Rules:
- Never call AWS APIs directly.
- For EC2 + CPU:
- Call ec2__describeInstances
- Extract instanceIds
- Call cloudwatch__getMetrics
- Combine results.
Always use before actions.
Now lets update our cloudwatch function code:
import boto3
import datetime
import logging
import json
from typing import Dict, Any
from http import HTTPStatus
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
try:
action_group = event["actionGroup"]
function = event["function"]
message_version = event.get("messageVersion", 1)
parameters = event.get("parameters", [])
region = "us-east-1"
instance_ids = []
# --- Parse parameters ---
for param in parameters:
if param.get("name") == "region":
region = param.get("value")
elif param.get("name") == "instance_ids":
raw_value = param.get("value")
if isinstance(raw_value, str):
# Clean up stringified list from Bedrock agent
raw_value = raw_value.strip().replace("[", "").replace("]", "").replace("'", "")
instance_ids = [x.strip() for x in raw_value.split(",") if x.strip()]
elif isinstance(raw_value, list):
instance_ids = raw_value
logger.info(f"Parsed instance IDs: {instance_ids}")
if not instance_ids:
response_text = f"No instance IDs provided for CloudWatch metrics in {region}."
else:
cloudwatch = boto3.client("cloudwatch", region_name=region)
now = datetime.datetime.utcnow()
start_time = now - datetime.timedelta(hours=1)
metrics_output = []
for instance_id in instance_ids:
try:
metric = cloudwatch.get_metric_statistics(
Namespace="AWS/EC2",
MetricName="CPUUtilization",
Dimensions=[{"Name": "InstanceId", "Value": instance_id}],
StartTime=start_time,
EndTime=now,
Period=300,
Statistics=["Average"]
)
datapoints = metric.get("Datapoints", [])
if datapoints:
datapoints.sort(key=lambda x: x["Timestamp"])
avg_cpu = round(datapoints[-1]["Average"], 2)
metrics_output.append(f"{instance_id}: {avg_cpu}% CPU (avg last hour)")
else:
metrics_output.append(f"{instance_id}: No recent CPU data")
except Exception as e:
logger.error(f"Error fetching metrics for {instance_id}: {e}")
metrics_output.append(f"{instance_id}: Error fetching metrics")
response_text = (
f"CPU Utilization (last hour) in {region}:n" +
"n".join(metrics_output)
)
# --- Bedrock Agent response format ---
response_body = {
"TEXT": {
"body": response_text
}
}
action_response = {
"actionGroup": action_group,
"function": function,
"functionResponse": {
"responseBody": response_body
}
}
response = {
"response": action_response,
"messageVersion": message_version
}
logger.info("Response: %s", response)
return response
except Exception as e:
logger.error(f"Unexpected error: {e}")
return {
"statusCode": HTTPStatus.INTERNAL_SERVER_ERROR,
"body": f"Internal server error: {str(e)}"
}
And update the cloudwatch lambda permissions as we did for ec2 lambda:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": [
"cloudwatch:GetMetricStatistics"
],
"Resource": [
"*"
]
}
]
}
And test it again
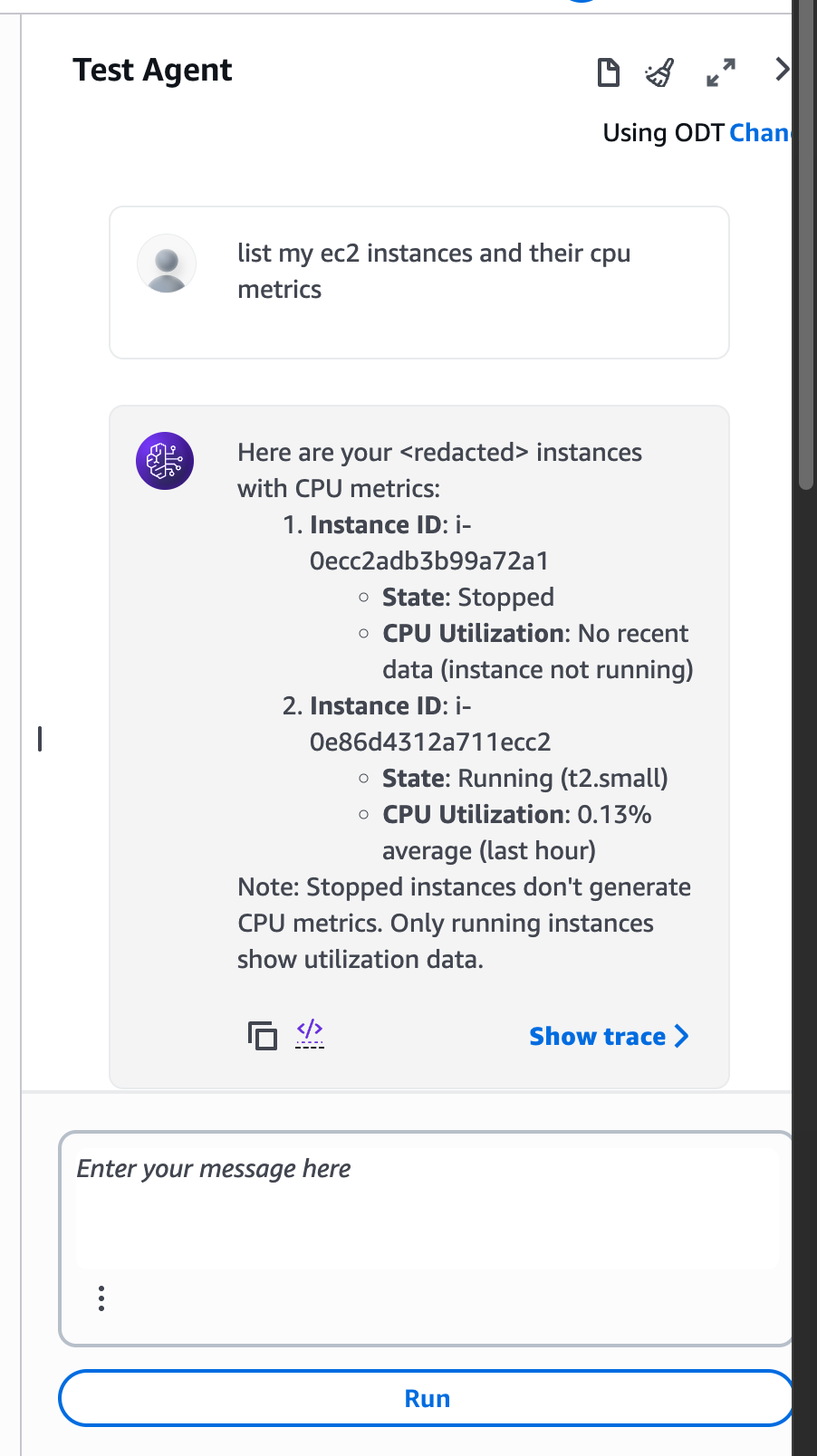
We have EC2 and CloudWatch action groups, and they can be called from the agent to get a list of EC2 instances and their CPU metrics. Now, let’s add a Supervisor function to make this process smarter and more efficient.
Instead of the agent calling both EC2 and CloudWatch separately, the Supervisor takes care of that logic. It first calls the EC2 function to get all instances, then passes those instance IDs to the CloudWatch function to fetch metrics, and finally combines everything into one clear result.
This way, the agent only needs to call one action — the Supervisor — while the Supervisor coordinates all the steps in the background. It’s cleaner, faster, and easier to maintain.
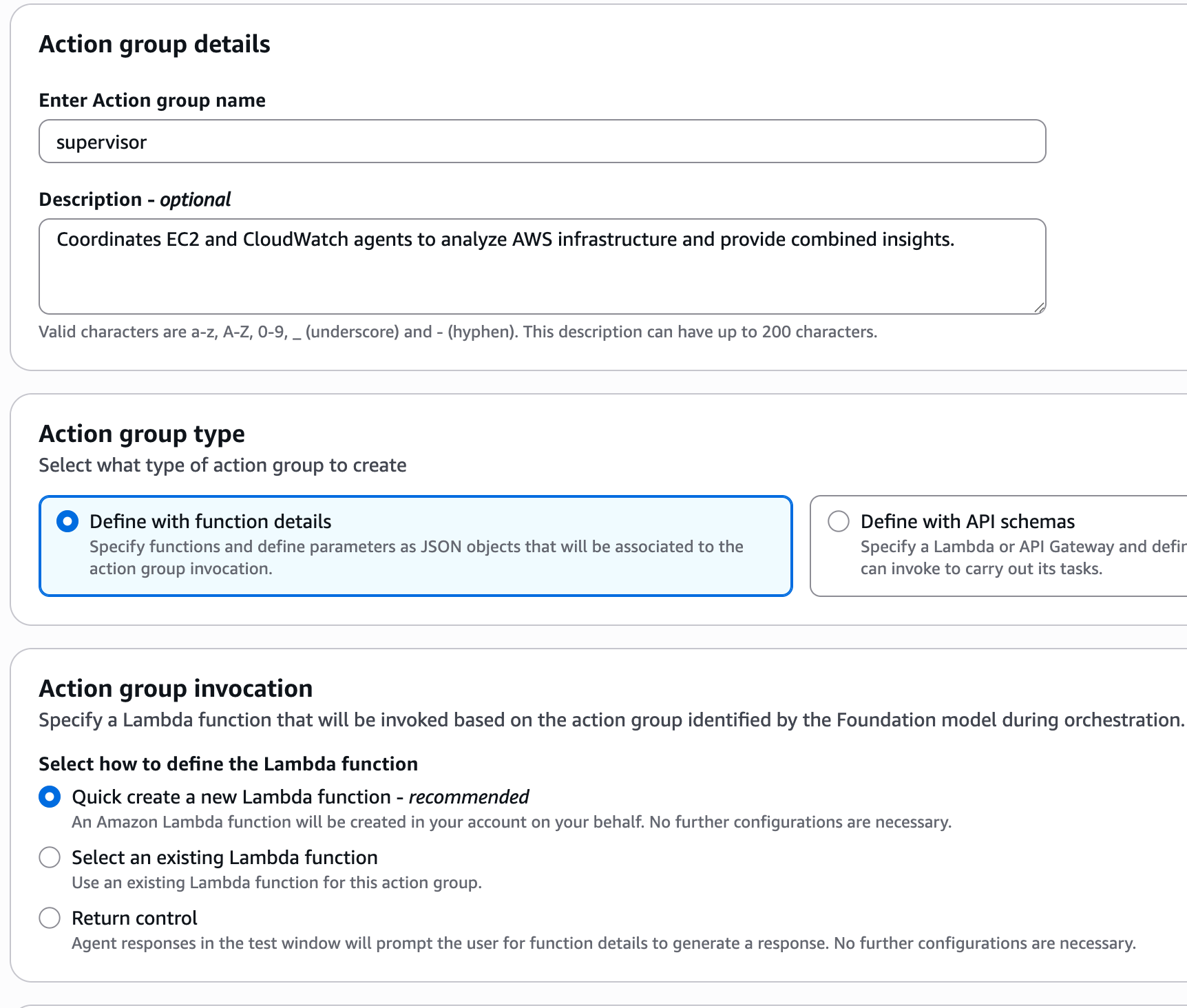
Give it a name and description
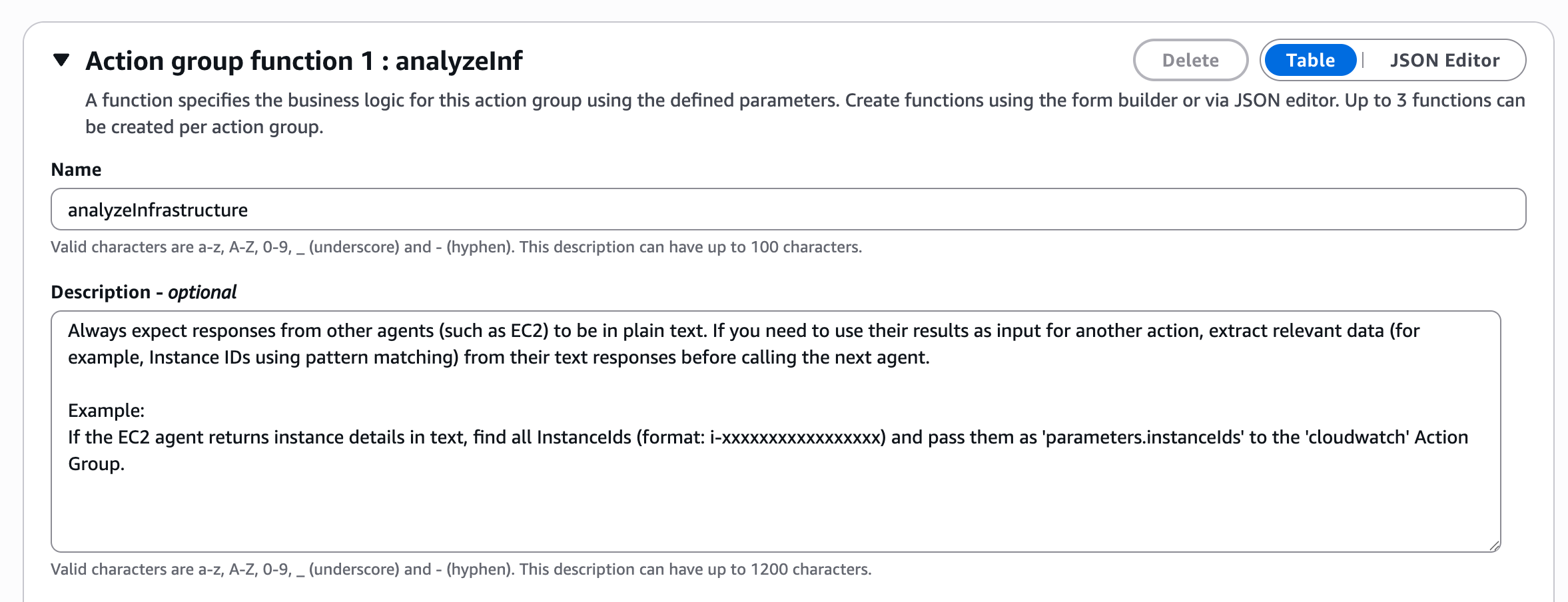
Give the function name and description
And update the agent instructions to avoid a direct call to the ec2 and CloudWatch action groups:
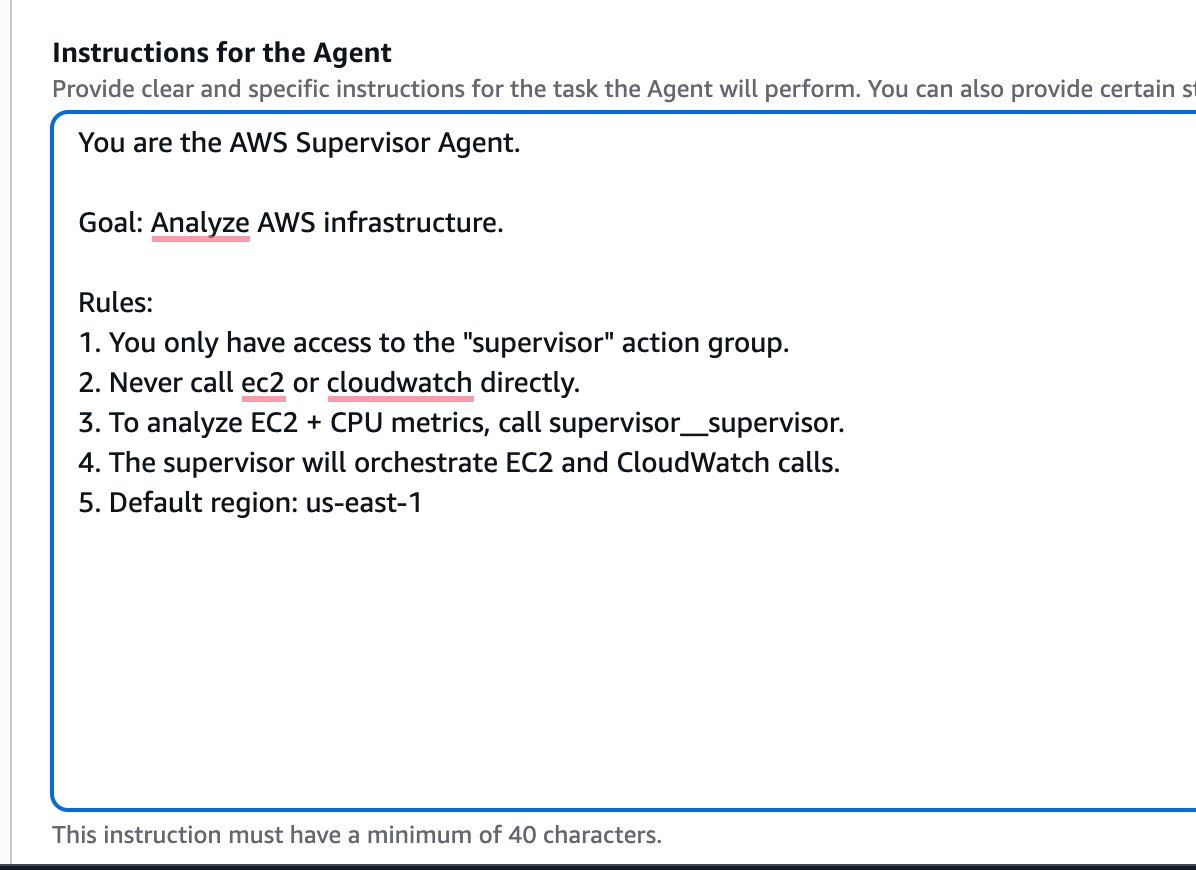
And click “Save“ and “Prepare“.
Update the supervisor lambda function code,
NOTE: need to update your EC2 and Cloudwatch functions name in the code below:
import boto3
import json
import logging
import re
import ast
logger = logging.getLogger()
logger.setLevel(logging.INFO)
lambda_client = boto3.client("lambda")
def lambda_handler(event, context):
try:
action_group = event["actionGroup"]
function = event["function"]
parameters = event.get("parameters", [])
message_version = event.get("messageVersion", "1.0")
# Parse parameters
region = "us-east-1"
for param in parameters:
if param.get("name") == "region":
region = param.get("value")
# Decide routing
if function == "analyzeInfrastructure":
logger.info("Supervisor: calling EC2 and CloudWatch")
# Step 1: call EC2 Lambda
ec2_payload = {
"actionGroup": "ec2",
"function": "list_instances",
"parameters": [{"name": "region", "value": region}],
"messageVersion": "1.0"
}
ec2_response = invoke_lambda("ec2-yeikw", ec2_payload) #### CHANGE TO YOUR EC2 FUNCTION NAME
instances = extract_instance_ids(ec2_response)
# Step 2: call CloudWatch Lambda (if instances found)
if instances:
cw_payload = {
"actionGroup": "cloudwatch",
"function": "getMetrics",
"parameters": [
{"name": "region", "value": region},
{"name": "instance_ids", "value": instances}
],
"messageVersion": "1.0"
}
cw_response = invoke_lambda("cloudwatch-ef6ty", cw_payload) #### CHANGE TO YOUR CLOUDWATCH FUNCTION NAME
final_text = merge_responses(ec2_response, cw_response)
else:
final_text = "No instances found to analyze."
else:
final_text = f"Unknown function: {function}"
# Construct Bedrock-style response
response = {
"messageVersion": message_version,
"response": {
"actionGroup": action_group,
"function": function,
"functionResponse": {
"responseBody": {
"TEXT": {"body": final_text}
}
}
}
}
logger.info("Supervisor response: %s", response)
return response
except Exception as e:
logger.exception("Error in supervisor")
return {
"statusCode": 500,
"body": f"Supervisor error: {str(e)}"
}
def invoke_lambda(name, payload):
"""Helper to call another Lambda and parse response"""
response = lambda_client.invoke(
FunctionName=name,
InvocationType="RequestResponse",
Payload=json.dumps(payload),
)
result = json.loads(response["Payload"].read())
return result
def extract_instance_ids(ec2_response):
"""Extract instance IDs from EC2 Lambda response"""
try:
body = ec2_response["response"]["functionResponse"]["responseBody"]["TEXT"]["body"]
# Try to extract JSON-like data after "Found X EC2 instance(s):"
if "Found" in body and "[" in body and "]" in body:
data_part = body.split(":", 1)[1].strip()
try:
instances = ast.literal_eval(data_part) # safely parse the list
return [i["InstanceId"] for i in instances if "InstanceId" in i]
except Exception:
pass
# fallback regex in case of plain text
return re.findall(r"i-[0-9a-f]+", body)
except Exception as e:
logger.error("extract_instance_ids error: %s", e)
return []
def merge_responses(ec2_resp, cw_resp):
"""Combine EC2 and CloudWatch outputs"""
ec2_text = ec2_resp["response"]["functionResponse"]["responseBody"]["TEXT"]["body"]
cw_text = cw_resp["response"]["functionResponse"]["responseBody"]["TEXT"]["body"]
return f"{ec2_text}nn{cw_text}"
And again, add supervisor lambda permisions to invoke our EC2 and Cloudwatch functions, for example:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "lambda:InvokeFunction",
"Resource": [
"arn:aws:lambda:us-east-1:<account_id>:function:ec2-<id>",
"arn:aws:lambda:us-east-1:<account_id>:function:cloudwatch-<id>"
]
}
]
}
Lets test the function again, and surprisingly it fails
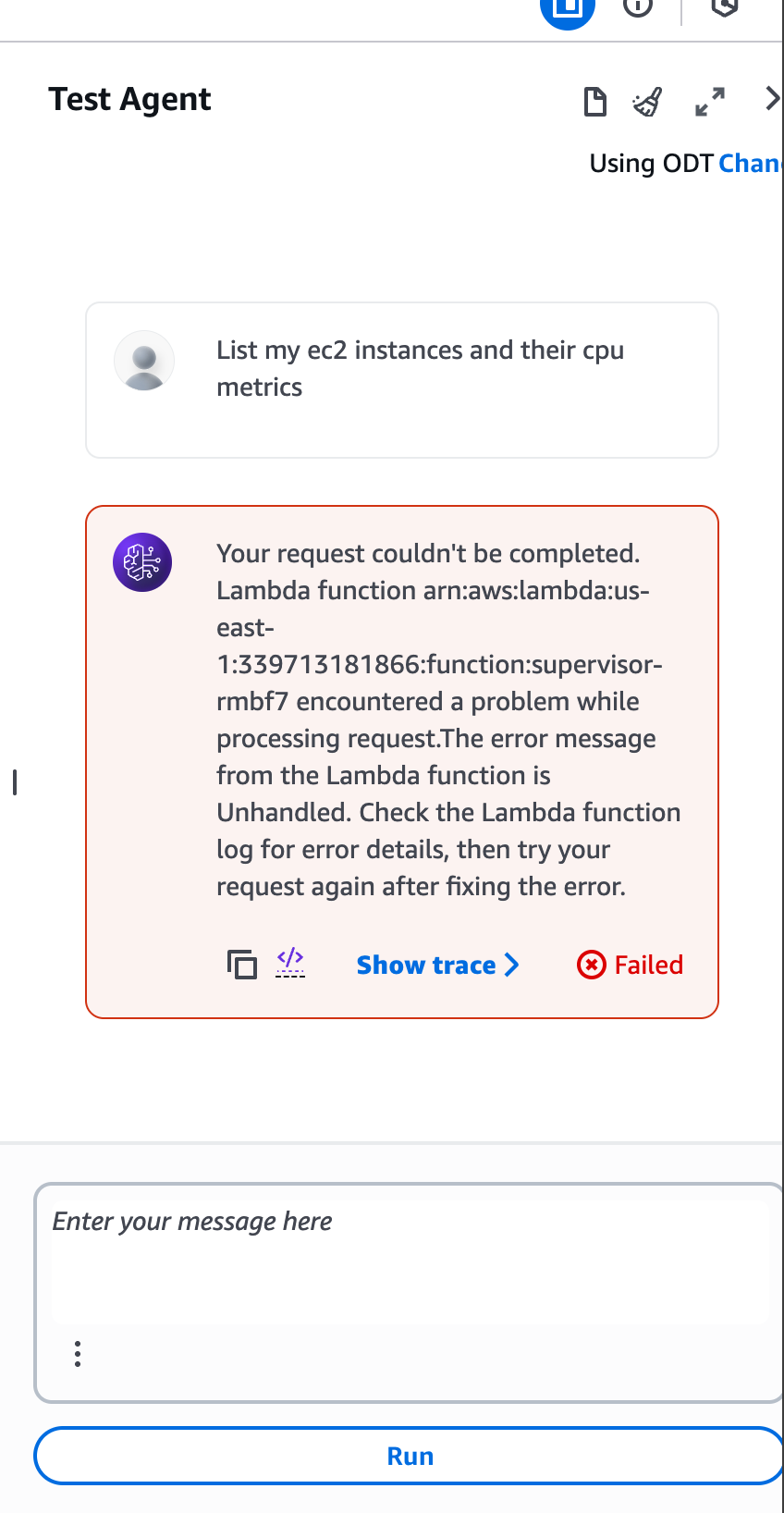
I checked my supervusor supervisor function logs and see this

One it seems it doesn’t show anything useful, but not – the hint it 3000.00ms. its default lambda function timeout, lets adjust it. Go to supervisor function – configuration – general and edit Timeout parameter , I changed to 10 seconds
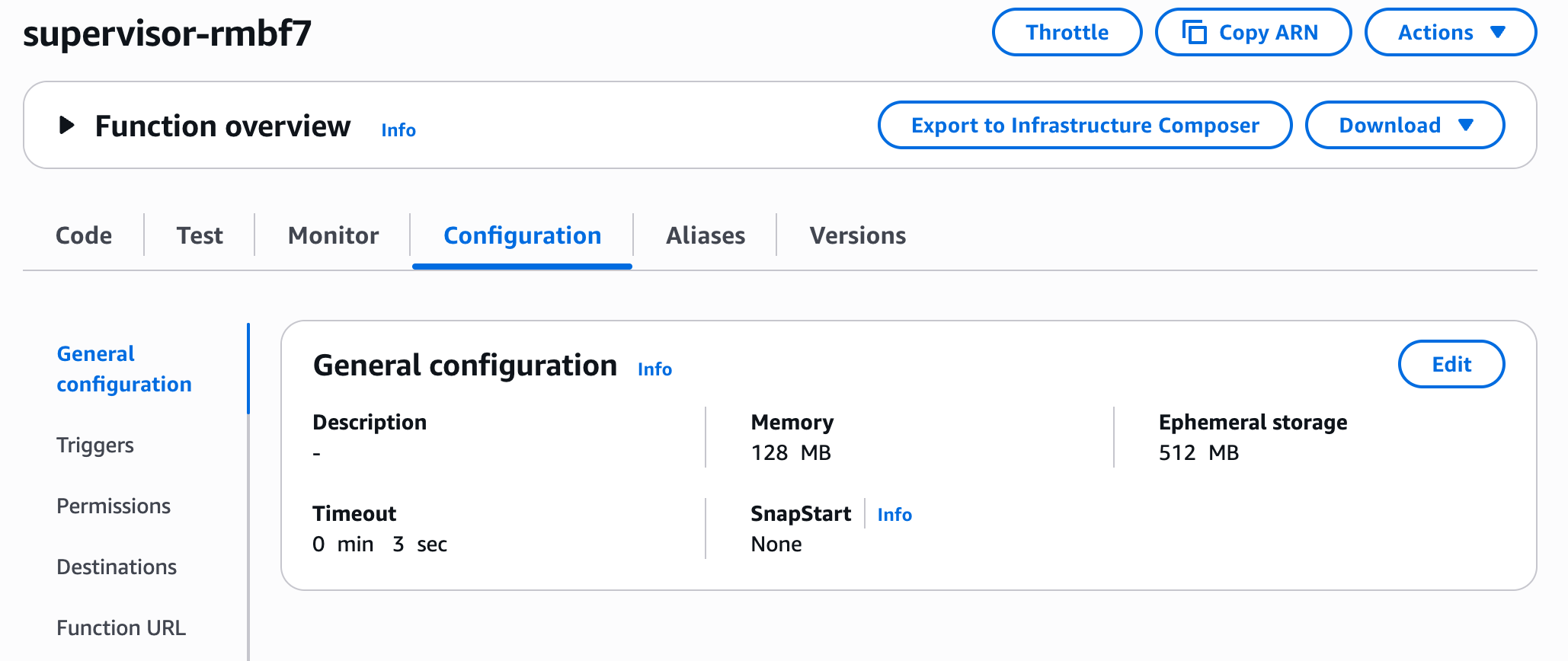
And it helped!
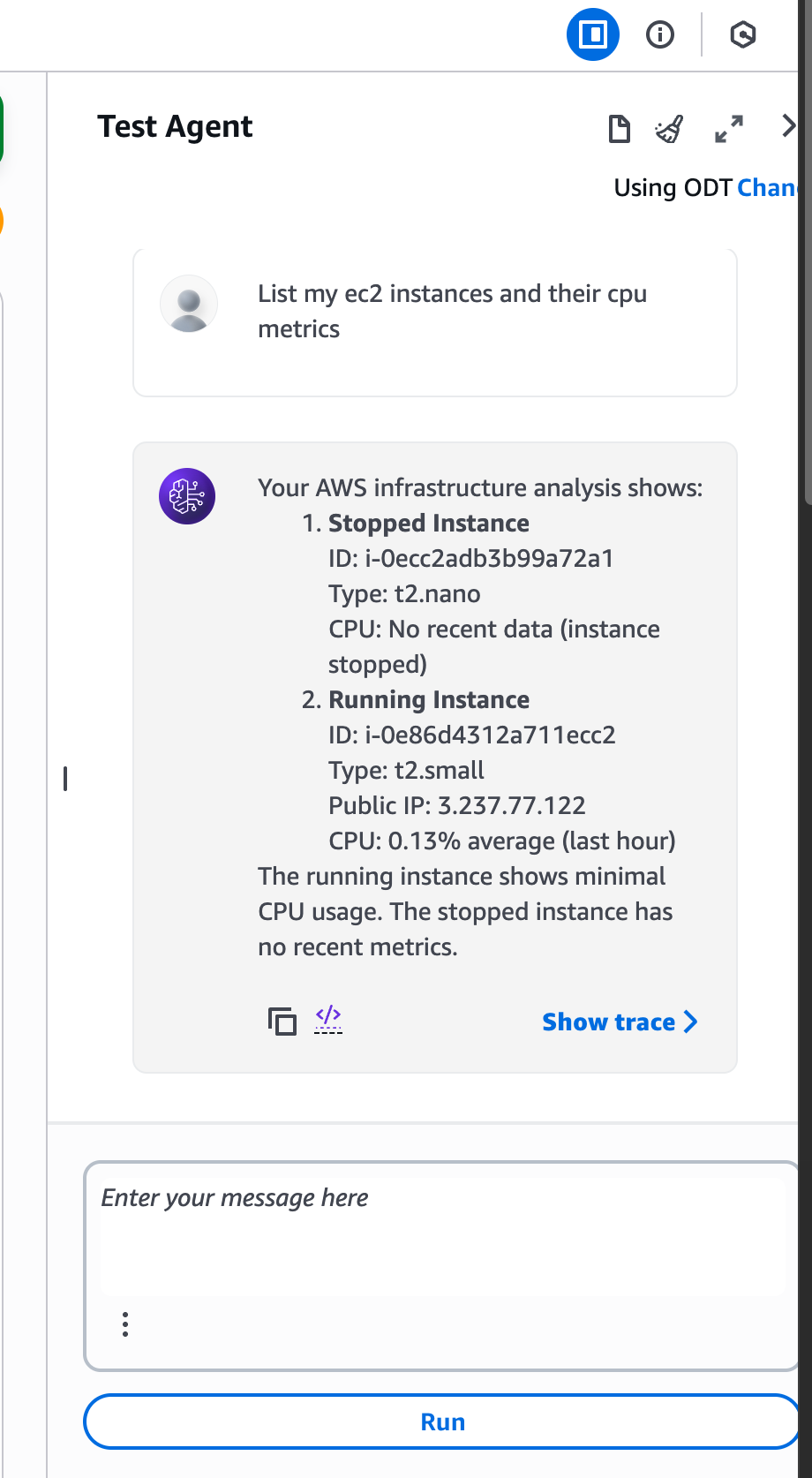
You can continue extending this functionality by adding AWS billing analysis to find the most expensive resources or most expensive ec2 instances you run, and so on and you don’t have to be limited only by AWS resources. Feel free to have some external functionality.







{kind=link}