Table of Links
Abstract and 1 Introduction
2 Related Works
3 Preliminaries
3.1 Fair Supervised Learning and 3.2 Fairness Criteria
3.3 Dependence Measures for Fair Supervised Learning
4 Inductive Biases of DP-based Fair Supervised Learning
4.1 Extending the Theoretical Results to Randomized Prediction Rule
5 A Distributionally Robust Optimization Approach to DP-based Fair Learning
6 Numerical Results
6.1 Experimental Setup
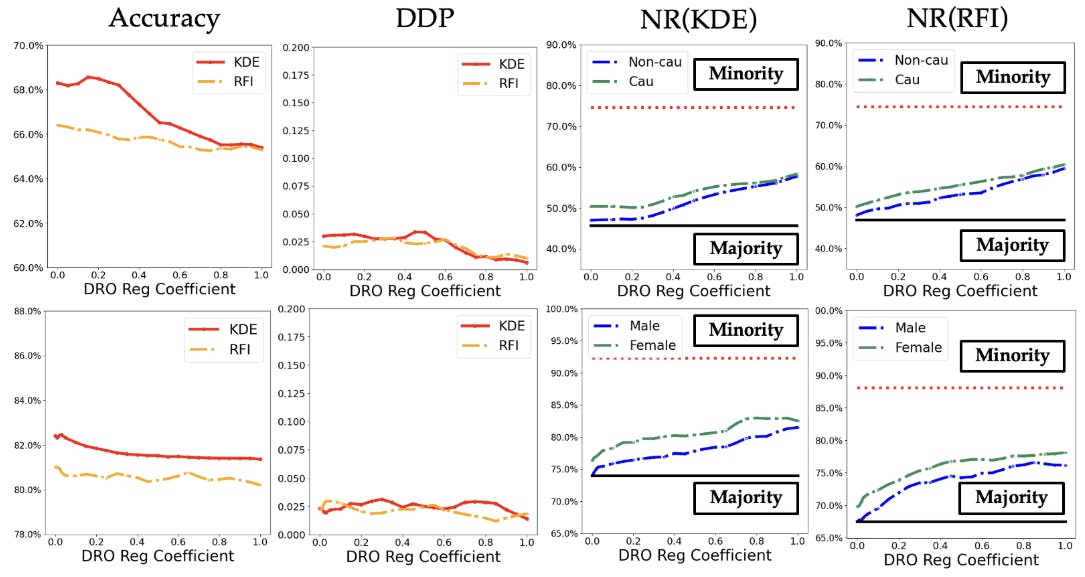
6.2 Inductive Biases of Models trained in DP-based Fair Learning
6.3 DP-based Fair Classification in Heterogeneous Federated Learning
7 Conclusion and References
Appendix A Proofs
Appendix B Additional Results for Image Dataset
7 Conclusion
In this work, we attempted to demonstrate the inductive biases of in-processing fair learning algorithms aiming to achieve demographic parity (DP). We also proposed a distributionally robust optimization scheme to reduce the biases toward the majority sensitive attribute. An interesting future direction to our work is to search for similar biases in pre-processing and post-processing fair learning methods. Also, the theoretical comparison between different dependence measures such as mutual information, Pearson correlation, and the maximal correlation on the inductive bias levels will be an interesting topic for future exploration. Finally, characterizing the trade-off between accuracy, fairness violation, and biases toward the majority subgroups will help to better understand the costs of DP-based fair learning.


References
[1] Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel. Fairness through awareness. In Proceedings of the 3rd innovations in theoretical computer science conference, pages 214–226, 2012. (Cited on page 1.)
[2] Moritz Hardt, Eric Price, and Nati Srebro. Equality of opportunity in supervised learning. Advances in neural information processing systems, 29, 2016. (Cited on pages 1, 3, and 4.)
[3] Toshihiro Kamishima, Shotaro Akaho, and Jun Sakuma. Fairness-aware learning through regularization approach. In 2011 IEEE 11th International Conference on Data Mining Workshops, pages 643–650. IEEE, 2011. (Cited on page 3.)
[4] Ashkan Rezaei, Rizal Fathony, Omid Memarrast, and Brian Ziebart. Fairness for robust log loss classification. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5511–5518, 2020. (Cited on page 3.)
[5] Brian Hu Zhang, Blake Lemoine, and Margaret Mitchell. Mitigating unwanted biases with adversarial learning. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, pages 335–340, 2018. (Cited on page 3.)
[6] Jaewoong Cho, Gyeongjo Hwang, and Changho Suh. A fair classifier using mutual information. In 2020 IEEE International Symposium on Information Theory (ISIT), pages 2521–2526. IEEE, 2020. (Cited on pages 3, 8, and 19.)
[7] Yuji Roh, Kangwook Lee, Steven Whang, and Changho Suh. Fr-train: A mutual information-based approach to fair and robust training. In International Conference on Machine Learning, pages 8147–8157. PMLR, 2020. (Cited on page 3.)
[8] Muhammad Bilal Zafar, Isabel Valera, Manuel Gomez Rogriguez, and Krishna P Gummadi. Fairness constraints: Mechanisms for fair classification. In Artificial intelligence and statistics, pages 962–970. PMLR, 2017. (Cited on page 3.)
[9] Alex Beutel, Jilin Chen, Tulsee Doshi, Hai Qian, Allison Woodruff, Christine Luu, Pierre Kreitmann, Jonathan Bischof, and Ed H Chi. Putting fairness principles into practice: Challenges, metrics, and improvements. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pages 453–459, 2019. (Cited on page 3.)
[10] Flavien Prost, Hai Qian, Qiuwen Chen, Ed H Chi, Jilin Chen, and Alex Beutel. Toward a better trade-off between performance and fairness with kernel-based distribution matching. arXiv preprint arXiv:1910.11779, 2019. (Cited on page 3.)
[11] Jaewoong Cho, Gyeongjo Hwang, and Changho Suh. A fair classifier using kernel density estimation. Advances in neural information processing systems, 33:15088–15099, 2020. (Cited on pages 3, 8, 9, and 19.)
[12] Jérémie Mary, Clément Calauzenes, and Noureddine El Karoui. Fairness-aware learning for continuous attributes and treatments. In International Conference on Machine Learning, pages 4382–4391. PMLR, 2019. (Cited on pages 3 and 8.)
[13] Sina Baharlouei, Maher Nouiehed, Ahmad Beirami, and Meisam Razaviyayn. Renyi fair inference. arXiv preprint arXiv:1906.12005, 2019. (Cited on pages 3, 8, and 9.)
[14] Vincent Grari, Boris Ruf, Sylvain Lamprier, and Marcin Detyniecki. Fairness-aware neural renyi minimization for continuous features. arXiv preprint arXiv:1911.04929, 2019. (Cited on page 3.)
[15] Vincent Grari, Oualid El Hajouji, Sylvain Lamprier, and Marcin Detyniecki. Learning unbiased representations via rényi minimization. In Machine Learning and Knowledge Discovery in Databases. Research Track: European Conference, ECML PKDD 2021, Bilbao, Spain, September 13–17, 2021, Proceedings, Part II 21, pages 749–764. Springer, 2021. (Cited on page 3.)
[16] Andrew Lowy, Sina Baharlouei, Rakesh Pavan, Meisam Razaviyayn, and Ahmad Beirami. A stochastic optimization framework for fair risk minimization. Transactions on Machine Learning Research, 2022. (Cited on page 3.)
[17] Michael Feldman, Sorelle A Friedler, John Moeller, Carlos Scheidegger, and Suresh Venkatasubramanian. Certifying and removing disparate impact. In proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, pages 259–268, 2015. (Cited on page 3.)
[18] Rich Zemel, Yu Wu, Kevin Swersky, Toni Pitassi, and Cynthia Dwork. Learning fair representations. In International conference on machine learning, pages 325–333. PMLR, 2013. (Cited on page 3.)
[19] Flavio Calmon, Dennis Wei, Bhanukiran Vinzamuri, Karthikeyan Natesan Ramamurthy, and Kush R Varshney. Optimized pre-processing for discrimination prevention. Advances in neural information processing systems, 30, 2017. (Cited on page 3.)
[20] Geoff Pleiss, Manish Raghavan, Felix Wu, Jon Kleinberg, and Kilian Q Weinberger. On fairness and calibration. Advances in neural information processing systems, 30, 2017. (Cited on page 3.)
[21] Tatsunori Hashimoto, Megha Srivastava, Hongseok Namkoong, and Percy Liang. Fairness without demographics in repeated loss minimization. In International Conference on Machine Learning, pages 1929–1938. PMLR, 2018. (Cited on page 3.)
[22] Serena Wang, Wenshuo Guo, Harikrishna Narasimhan, Andrew Cotter, Maya Gupta, and Michael Jordan. Robust optimization for fairness with noisy protected groups. Advances in neural information processing systems, 33:5190–5203, 2020. (Cited on page 3.)
[23] Preethi Lahoti, Alex Beutel, Jilin Chen, Kang Lee, Flavien Prost, Nithum Thain, Xuezhi Wang, and Ed Chi. Fairness without demographics through adversarially reweighted learning. Advances in neural information processing systems, 33:728–740, 2020. (Cited on page 3.)
[24] Hongseok Namkoong and John C Duchi. Stochastic gradient methods for distributionally robust optimization with f-divergences. Advances in neural information processing systems, 29, 2016. (Cited on page 7.)
[25] Dimitris Bertsimas, Melvyn Sim, and Meilin Zhang. Adaptive distributionally robust optimization. Management Science, 65(2):604–618, 2019. (Cited on page 7.)
[26] Hamed Rahimian and Sanjay Mehrotra. Distributionally robust optimization: A review. arXiv preprint arXiv:1908.05659, 2019. (Cited on page 7.)
[27] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Large-scale celebfaces attributes (celeba) dataset. Retrieved August, 15(2018):11, 2018. (Cited on page 8.)
[28] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. (Cited on pages 8 and 19.)
[29] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pages 1273–1282. PMLR, 2017. (Cited on page 11.)
[30] Gustavo L Gilardoni. On the minimum f-divergence for given total variation. Comptes rendus. Mathématique, 343(11-12):763–766, 2006. (Cited on page 17.)
[31] Shahab Asoodeh, Fady Alajaji, and Tamás Linder. On maximal correlation, mutual information and data privacy. In 2015 IEEE 14th Canadian workshop on information theory (CWIT), pages 27–31. IEEE, 2015. (Cited on page 17.)
Authors:
(1) Haoyu LEI, Department of Computer Science and Engineering, The Chinese University of Hong Kong ([email protected]);
(2) Amin Gohari, Department of Information Engineering, The Chinese University of Hong Kong ([email protected]);
(3) Farzan Farnia, Department of Computer Science and Engineering, The Chinese University of Hong Kong ([email protected]).






{kind=link}