I shared the benefits of cell-based architecture in my previous article. In this one, I’ll walk through a real-world scenario involving scaling challenges in our service caused by dependent service quota limitations, and how we overcame them using a cell-based approach. By adopting this architecture, we launched multiple cells to address the quota constraints and achieved a highly scalable service
Background
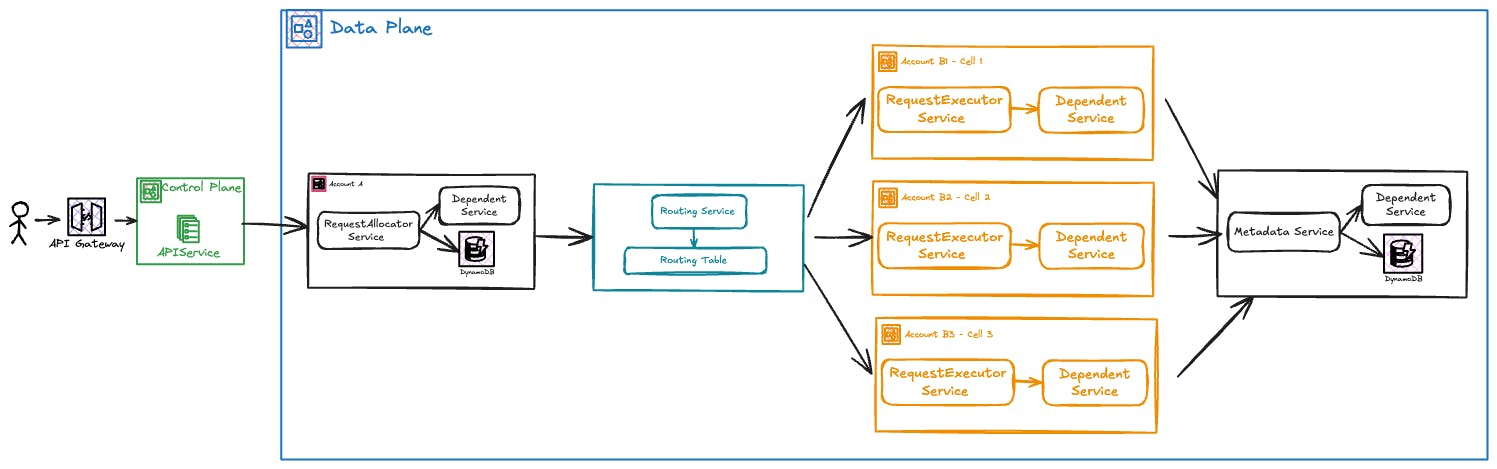
We launched our services in production without cells. The service was a single microservice which can be viewed as a service with a fixed giant cell. Every request went to a single instance of the service. After running it in production for 6 months, we noticed scaling bottlenecks—one of the dependencies was limiting our scaling. They had a fixed quota per account. The only way to deal with this challenge was to run services in multiple accounts so that every account got a fixed quota. By running multiple instances of a service in different accounts (cells) we could potentially serve many requests and hence achieve the desired scaling.


Problem Statement
When we decided to move to cell-based architecture, we found many challenges, such as stateful service and direct dependency, etc. Adopting a cell-based architecture became a daunting task for the whole team and required alot of effort.
Stateful services hinder moving into cell-based architecture as they restrict the processing of a request to a dedicated instance of the service. Furthermore, direct dependency creates a tight coupling between a request and a processing node. To achieve scalability, we should be able to process requests on any of our services instances.
Execution Plan
After running the service in production for 6 months, we got a fair understanding of its components. So, we started analyzing each service component to answer the following questions to evaluate cell adoption strategies:
- Which components should be moved to a cell-based architecture?
- What are the challenges of moving a component in a cell?
- How can a component/service be made stateless?
- What does it take to remove a direct dependency?
- How can cell creation, which includes account creation, be automated, and subsequently added to the deployment pipeline?
- What does it take to do the cell migration? Can avoid it be avoided?
- What would the routing layer look like?
- How would the service endpoint look for external and internal users/services?
Based on the evaluation, we figured out two important things:
-
Stateless service
-
Flexible Routing layer.


Stateless Service
We started analyzing all the storage components of our services. We mainly had DynamoDB and S3, where we store customer metadata and processing metadata. To make the service stateless, we built a metadata service and moved all the customer metadata and processing metadata that were making the service stateful. Exposed the storage layer functionality with well-defined APIs so that we can access it from any cell.
Flexible Thin Routing Layer
We used a hybrid approach where we use consistent ring hashing and table mapping. Consistent ring hashing is used to map most of the requests to a cel,l and table mapping is used to override some config. For example, if we want to segregate the processing for a large customer, we use table mapping. The table mapping is available in memory so that we keep the routing layer as thin as possible.
Outcome
Through contemplation and thorough analysis, we made our services stateless, which simplified the adoption of a cell-based approach in our product. Furthermore, following best practices such as using stateless components and maintaining a thin routing layer helped us build a flexible cellular service capable of continuously supporting growing scale demands. I highly encourage you to explore cell-based architecture to make your services more scalable.







{kind=link}