Table of Links
Abstract and 1. Introduction
-
Related Work
-
Method
3.1 Overview of Our Method
3.2 Coarse Text-cell Retrieval
3.3 Fine Position Estimation
3.4 Training Objectives
-
Experiments
4.1 Dataset Description and 4.2 Implementation Details
4.3 Evaluation Criteria and 4.4 Results
-
Performance Analysis
5.1 Ablation Study
5.2 Qualitative Analysis
5.3 Text Embedding Analysis
-
Conclusion and References
Supplementary Material
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
Anonymous Authors
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
7 DETAILS OF KITTI360POSE DATASET






We conduct an additional experiment to assess the impact of the number of queries on the performance of our instance query extractor. As detailed in Table 7, we evaluate the localization recall rate using 16, 24, and 32 queries. The result demonstrates that using 24 queries yields the highest localization recall rate, i.e, 0.23/0.53/0.64 on the validation set and 0.22/0.47/0.58 on the test set. This finding suggests that the optimal number of queries for maximizing the effectiveness of our model is 24.
9 TEXT-CELL EMBEDDING SPACE ANALYSIS
Fig. 8 shows the aligned text-cell embedding space via T-SNE [37]. Under the instance-free scenario, we compare our model with Text2loc [42] using a pre-trained instance segmentation model, Mask3D [35], as a prior step. It can be observed that Text2Loc results in a less discriminative space, where positive cells are relatively far from the text query feature. In contrast, our IFRP-T2P effectively reduces the distance between positive cell features and text query features within the embedding space, thereby creating a more informative embedding space. This enhancement in the embedding space is critical for improving the accuracy of text-cell retrieval.


10 MORE VISUALIZATION RESULTS
Fig. 9 shows more visualization results including both the retrieval outcomes and the results of fine position estimation. The results suggest that the coarse text-cell retrieval serves as a foundational step in the overall localization process. The subsequent fine position estimation generally improves the localization performance. However, there are cases where the accuracy of this fine estimation is compromised, particularly when the input descriptions are vague. This detrimental effect on accuracy is illustrated in the 4-th row and 6-th row if Fig. 9.


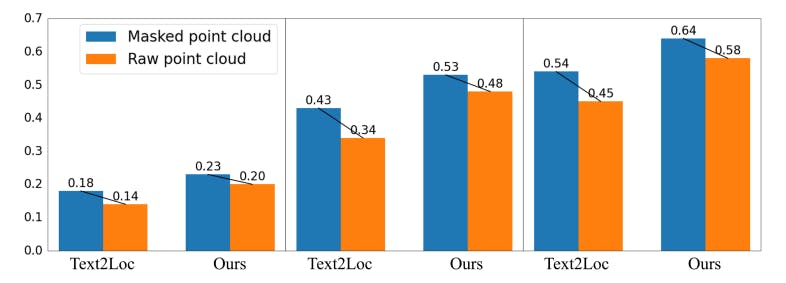
11 POINT CLOUD ROBUSTNESS ANALYSIS
Previous works [21, 39, 42] focused solely on examining the impact of textual modifications on localization accuracy, ignoring the impact of point cloud modification. In this study, we further consider the effects of point cloud degradation, which is crucial for fully analyzing our IFRP-T2P model. Unlike the accumulated point clouds provided in the KITTI360Pose dataset, LiDAR sensors typically capture only sparse point clouds in real-world settings. To assess the robustness of our model under conditions of point cloud sparsity, we conduct experiments by randomly masking out one-third of the points and compare these results to those obtained using raw point clouds. As illustrated in Fig. 10, when taking the masked point cloud as input, our IFRP-T2P model achieves a localization recall of 0.20 at top-1 with an error bound of 𝜖 < 5𝑚 on the validation set. Compared to Text2Loc, which shows a degradation of 22.2%, our model exhibits a lower degradation rate of 15%. This result indicates that our model is more robust to point cloud variation.


Authors:
(1) Lichao Wang, FNii, CUHKSZ ([email protected]);
(2) Zhihao Yuan, FNii and SSE, CUHKSZ ([email protected]);
(3) Jinke Ren, FNii and SSE, CUHKSZ ([email protected]);
(4) Shuguang Cui, SSE and FNii, CUHKSZ ([email protected]);
(5) Zhen Li, a Corresponding Author from SSE and FNii, CUHKSZ ([email protected]).
This paper is






{kind=link}