
Your engineering team needs to add semantic search. You’re running Algolia. They just added vectors. You enable it and wait for the magic.
Instead, you get three months of infrastructure hell. The semantic layer needs different data than your keyword index: product attributes, user behavior signals, business logic. Every relevance tweak means reindexing everything. Hybrid queries hit two separate systems, merging results in application code. You’re maintaining parallel infrastructure: Algolia for the search interface, your services for embeddings and personalization, glue code connecting them.
Three months in, you realize you’re spending more time fighting architectural constraints than improving search quality. Your team isn’t iterating on relevance. They’re managing infrastructure workarounds.
This is the moment you understand: you’re not adding a feature. You’re retrofitting AI native requirements onto infrastructure built for a different era.
What Keyword Search Was Built For
To understand why this happens, we need to look at what keyword search was actually designed to solve.
Keyword search engines like Algolia solved a specific problem brilliantly: fast, precise lookups across structured catalogs. Given a query like “red leather jacket size large,” return exact matches instantly, filter by facets (color, material, size), and rank by simple signals like popularity or price. The solution (inverted indices with BM25 scoring) is elegant and effective. Build a lookup table mapping terms to documents, add statistical weighting for term frequency, layer on faceting, and you have a system that scales beautifully.
This architecture makes perfect sense for classic e-commerce search, documentation lookups, catalog browsing. Keyword search delivers exact matches, fast faceting, and predictable ranking with impressive efficiency.
The problem isn’t that keyword search is bad technology. The fundamental requirements have shifted. Search used to mean “find documents matching these keywords.” Now it means “understand intent across multiple signals and rank by complex, contextual relevance.” That’s not a feature gap. It’s an architectural mismatch. The infrastructure that made keyword search fast and reliable is what makes AI native search complicated.
The AI Native Search Shift
That architectural mismatch isn’t theoretical. It’s driven by a fundamental shift in what search actually means.
Modern search queries aren’t simple keyword lookups. After ChatGPT’s launch, Algolia’s CTO reported seeing twice as many keywords per search query. Users expect natural language. A query like “comfortable running shoes for marathon training under $150” isn’t looking for keyword matches. It expresses intent spanning semantic understanding (what makes shoes comfortable for marathons?), numerical constraints (price), and categorical filters (product type, use case).
This isn’t gradual evolution. It’s a phase change. User expectations shifted overnight. The infrastructure choices you make today determine your search velocity for the next five years. Teams that rebuild on AI native foundations can iterate weekly on relevance. Teams patching keyword systems spend months on each improvement. Your competitors are making this choice right now.
AI native search requires:
- Semantic understanding across unstructured text, not term matching
- Multi-signal scoring combining embeddings, behavioral data, business rules, and metadata in coherent ranking
- Personalization adapting results to user context and history
- Multimodal reasoning handling text, images, structured attributes, and temporal signals
- Continuous iteration through evaluation loops, not config tweaks
These capabilities need integration at the infrastructure level: how you index data, structure queries, evaluate results. They’re not separate features you bolt together. The fundamental architectural assumptions have changed. Keyword first platforms weren’t designed for this, and the mismatch shows up in concrete ways.
Where Keyword-First Architecture Hits the Wall
The architectural mismatch surfaces in predictable ways. Here’s where teams consistently hit the wall.
Breaking Point #1: Schema Rigidity Meets Complex Scoring

You’re building e-commerce product search. You need to rank by semantic similarity, user behavioral signals, business constraints, and recency. Table stakes for competitive discovery.
In keyword first architecture, each signal lives separately. Text descriptions in the inverted index. Behavioral data in analytics. Business rules in application logic. Vectors bolted on through another service. You’re maintaining four systems and merging outputs in code you wrote.
Want to adjust how these combine? You’re fighting the architecture. To express “find semantically similar products, boost by conversion rate, filter by margin, decay by days since launch,” you’re writing custom merge logic, managing cache invalidation across systems, hoping your application layer scoring approximates what you want.
The pain comes during iteration. In AI native search, relevance is empirical: run evaluations, measure NDCG (ranking quality) or MRR (retrieval accuracy), adjust weights, deploy. When scoring logic scatters across multiple systems with different schemas and update cadences, evaluation becomes a research project. You can’t quickly test “weight user behavior 30% higher” without orchestrating changes across your entire stack.
Breaking Point #2: Vectors as Bolt-On vs. First-Class Primitive
Press enter or click to view image in full size 
The “we added vector search” announcement sounds promising. Then you build hybrid retrieval and discover the seams.
Keyword search happens in the inverted index. Vector search in a separate subsystem. Each has its own query path, ranking model, and performance characteristics. You want “recent articles about machine learning deployment challenges”: semantic understanding, keyword precision, temporal filtering. You get two independent searches merged in application code.
The merging is surprisingly hard. How do you normalize keyword relevance scores and vector similarity? What happens when keyword search returns 100 results but vectors find only 10 relevant ones? You’re writing ranking logic that should be the search engine’s job, without performance optimizations or evaluation frameworks that belong at the infrastructure layer.
Customer support search across tickets, docs, and chat logs: users ask in natural language but need exact matches on ticket IDs, error codes, product names. Semantic alone misses precision. Keywords alone miss the intent. You need both, tightly integrated, with unified understanding of “relevant.”
In bolt-on architecture, you manage this yourself. Separate indices, merge logic, debugging inconsistencies. The infrastructure treats vectors as an add-on, not a core primitive that changes how search works.
Breaking Point #3: The Iteration Gap

The most profound limitation surfaces when you improve search quality systematically.
In AI native search, relevance is empirical: define metrics, run evaluations, iterate. Keyword first platforms weren’t built for this. You get configuration parameters to tweak manually and evaluate by eyeballing results. No first class support for evaluation datasets, metric tracking, or A/B testing.
The ownership problem: you want your own embedding model, custom reranking, your personalization system. In closed SaaS, you either use what they provide or build parallel infrastructure.
So you run shadow systems. Algolia for keyword search, your infrastructure for embeddings, your code for hybrid scoring and personalization. You’re paying for managed search while building the components you actually need. The cost isn’t just financial. It’s operational complexity, data synchronization, managing Frankenstein architecture.
The feedback loop that should drive improvement (experiment, measure, iterate) becomes an engineering project. You can’t rapidly test new approaches or systematically evaluate whether changes improve relevance. You’re tweaking parameters in a system not designed for evaluation driven AI search.
Principles for AI-Native Search Infrastructure
A few architectural principles that address these breaking points directly.
Principle #1: First class AI primitives
Embeddings, models, and hybrid retrieval aren’t features bolted onto keyword search. They’re core architectural concepts. Index structure is designed for multi-signal retrieval from the ground up. Not separate systems for keyword and vector search, but unified infrastructure understanding both as complementary mechanisms. Queries naturally express “semantic similarity weighted at 0.7, keyword precision at 0.3, filtered by numerical constraints,” and infrastructure executes coherently.
Principle #2: Flexible logic ownership
The platform handles production problems: indexing at scale, query latency, reliability, observability. You control search logic: your embedding models, scoring functions, personalization. These aren’t configuration parameters. It’s programmable infrastructure. Plug in custom models, implement business specific ranking, integrate existing personalization systems, all without parallel infrastructure.
Principle #3: Multi-attribute architecture
Complex queries involve multiple data types: text, numerical constraints, categorical filters, temporal signals, behavioral data. AI search infrastructure represents these as separate but coordinated embeddings, not compressed into a single vector. Searching “affordable luxury hotels near the beach with good reviews” separately encodes semantic understanding, numerical constraints, and quality signals, then coordinates them at query time without losing attribute specific information.
Principle #4: Eval driven by design
Systematic improvement requires infrastructure supporting the full evaluation loop: defining metrics, running experiments, tracking performance, A/B testing changes. This isn’t an afterthought. It’s built into how the platform works. Iterate on relevance with the same velocity as any ML system, because infrastructure treats evaluation and experimentation as first class workflows.
The goal isn’t replacing every component of search infrastructure. It’s aligning infrastructure’s core assumptions with what AI native search actually requires.
Patch or Rebuild?
The architectural gap is widening. Every quarter, the distance between what keyword first platforms can deliver and what users expect grows larger. Meanwhile, the cost of maintaining hybrid architectures compounds.
This isn’t about ripping out your stack tomorrow. It’s about understanding the trajectory. Every workaround (the shadow infrastructure for embeddings, application layer merging logic, manual relevance tuning) is technical debt. That debt compounds. As search becomes more central to your product, as user expectations increase, as you want faster relevance improvements, architectural friction becomes the bottleneck.
The real question isn’t “can we make keyword search work for AI?” You can. People do, with enough engineering effort and compromise. The question is: what’s the cost?
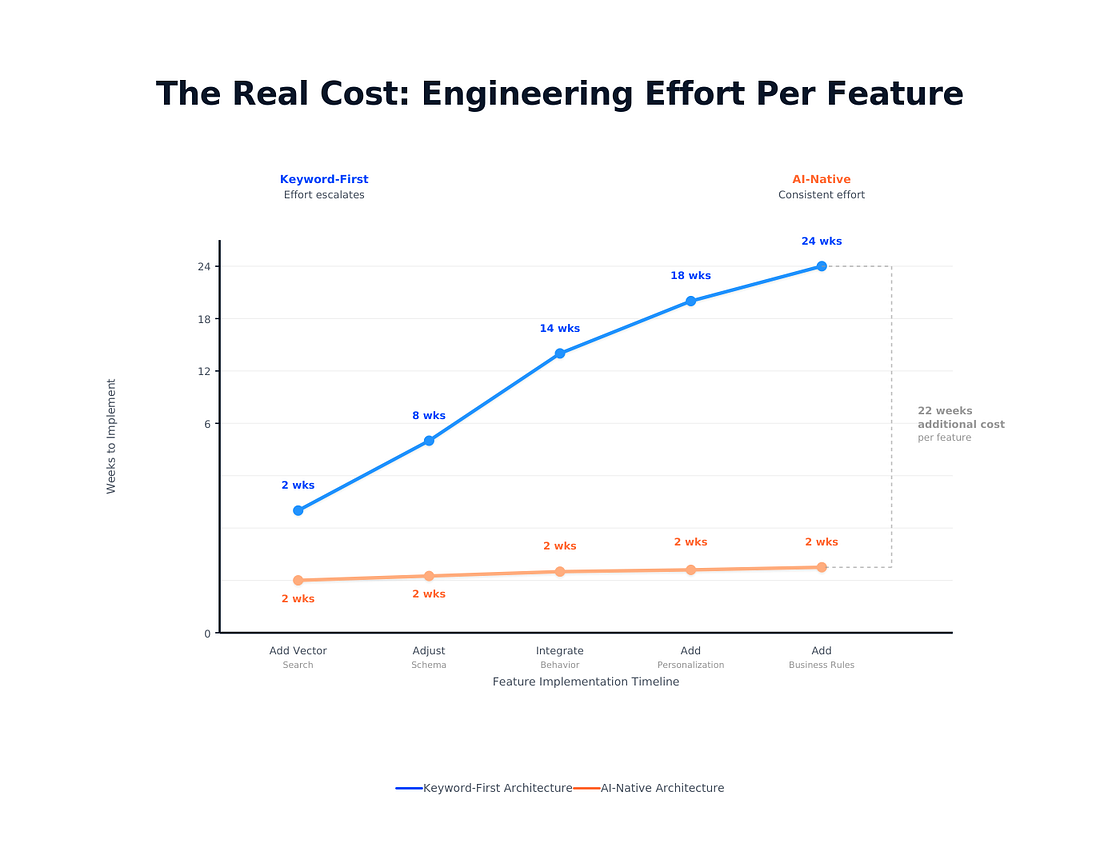
Engineering time on infrastructure plumbing instead of search quality. Velocity: how quickly can you experiment and improve? The quality ceiling: what’s possible within these constraints?
For teams where search quality is a competitive differentiator, where users expect natural language understanding and personalized results, where relevance needs continuous improvement through evaluation and iteration, the architectural mismatch matters. Keyword first platforms weren’t built for this. Infrastructure built for AI native search addresses these requirements at the foundation.
The infrastructure decisions you make today determine whether you’re iterating on relevance weekly or spending quarters on architectural rewrites. The teams moving fastest aren’t the ones with the most engineers. They’re the ones whose infrastructure aligns with what AI native search actually requires.
The transition isn’t about what’s possible. It’s about what’s sustainable. As your search requirements grow: are you fighting your infrastructure, or building with it?
Ready to evaluate your options?
- Vector DB Comparison — compare 30+ vector databases
- VectorHub — practical guides for building AI native search
- Superlinked — AI native search infrastructure platform







{kind=link}