
Table of Links
Abstract and 1 Introduction
2 Background
2.1 Large Language Models
2.2 Fragmentation and PagedAttention
3 Issues with the PagedAttention Model and 3.1 Requires re-writing the attention kernel
3.2 Adds redundancy in the serving framework and 3.3 Performance Overhead
4 Insights into LLM Serving Systems
5 vAttention: System Design and 5.1 Design Overview
5.2 Leveraging Low-level CUDA Support
5.3 Serving LLMs with vAttention
6 vAttention: Optimizations and 6.1 Mitigating internal fragmentation
6.2 Hiding memory allocation latency
7 Evaluation
7.1 Portability and Performance for Prefills
7.2 Portability and Performance for Decodes
7.3 Efficacy of Physical Memory Allocation
7.4 Analysis of Memory Fragmentation
8 Related Work
9 Conclusion and References
2.2 Fragmentation and PagedAttention
To improve serving throughput, production systems rely on batching which requires careful allocation of GPU memory. This is challenging because the total context length of a request is not known in advance. Serving systems worked around this challenge by pre-reserving KV-cache space assuming that each context is as long as the maximum length supported by the model (e.g.,200K for Yi-6B-200K). vLLM shows that this strategy is prone to severe internal fragmentation. In fact, vLLM showed that prior reservation wastes memory even if the context lengths are known in advance. This is because the per-request KV-cache grows one token at a time and hence prior reservation wastes memory over the entire lifetime of a request.

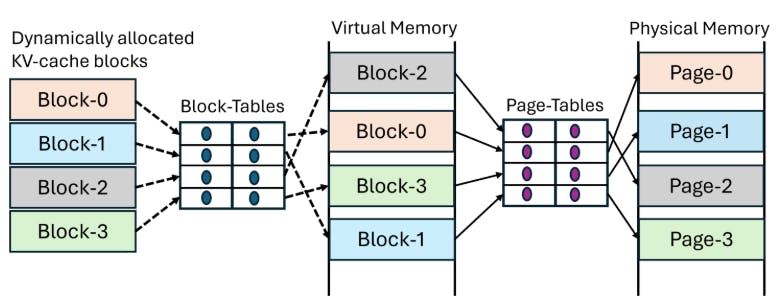
Inspired by the OS-based virtual memory systems, vLLM proposed PagedAttention to mitigate fragmentation by dynamically allocating memory for the KV-cache. PagedAttention splits KV-cache into fixed-sized blocks and allocates memory for one block at a time. This way, vLLM allocates only as much memory as a request needs, and only when required – not ahead-of-time. Figure 1 shows an example of how reservation-based systems such as Orca [47] can waste significant memory due to fragmentation and how vLLM avoids it with dynamic memory allocation.
Authors:
(1) Ramya Prabhu, Microsoft Research India;
(2) Ajay Nayak, Indian Institute of Science and Contributed to this work as an intern at Microsoft Research India;
(3) Jayashree Mohan, Microsoft Research India;
(4) Ramachandran Ramjee, Microsoft Research India;
(5) Ashish Panwar, Microsoft Research India.







{kind=link}