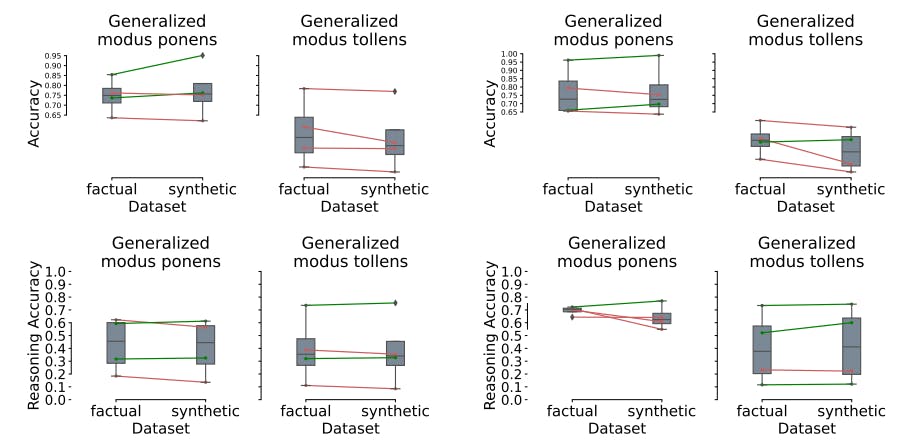
The lack of statistically significant differences (Fig. 7) in accuracy between biologically factual and artificial datasets across generalized modus ponens and generalized modus tollens schemes suggests that the models’ reasoning capabilities rely more on stated contextual knowledge and logical structure than on pre-existing background knowledge. This holds true for both accuracy and reasoning accuracy, as well as in both ZS and FS settings: models that perform well on a given scheme maintain their performance even when factual gene names are replaced by synthetic names, and the same consistency is observed for models with weaker performance. This ability to maintain accuracy with synthetic gene names in the artificial set demonstrates that models can abstract and apply logical reasoning independently of their internal domain-specific knowledge.
Authors:
(1) Magdalena Wysocka, National Biomarker Centre, CRUK-MI, Univ. of Manchester, United Kingdom;
(2) Danilo S. Carvalho, National Biomarker Centre, CRUK-MI, Univ. of Manchester, United Kingdom and Department of Computer Science, Univ. of Manchester, United Kingdom;
(3) Oskar Wysocki, National Biomarker Centre, CRUK-MI, Univ. of Manchester, United Kingdom and ited Kingdom 3 I;
(4) Marco Valentino, Idiap Research Institute, Switzerland;
(5) André Freitas, National Biomarker Centre, CRUK-MI, Univ. of Manchester, United Kingdom, Department of Computer Science, Univ. of Manchester, United Kingdom and Idiap Research Institute, Switzerland.






{kind=link}