
Microsoft AI, in collaboration with Renmin University of China, has introduced Chain-of-Retrieval Augmented Generation (CoRAG), a new AI framework designed to enhance Retrieval-Augmented Generation (RAG) models. Unlike traditional RAG systems, which rely on a single retrieval step, CoRAG enables iterative search and reasoning, allowing AI models to refine their retrievals dynamically before generating answers.
This improvement overcomes a significant drawback of traditional RAG systems: their lack of ability to effectively integrate information from multiple sources. In complex queries, particularly in multi-hop question answering (QA), traditional RAG models often struggle because they retrieve information only once, leading to incomplete or inaccurate results. CoRAG changes this by reformulating queries at each step, enabling AI to “think through” retrievals much like human researchers.
The core innovation in CoRAG is its dynamic query reformulation mechanism. Instead of relying on a single retrieval step, the model iteratively refines its queries based on intermediate reasoning states. This process ensures that information retrieved at each stage is contextually relevant and builds toward a more complete final answer.
To train CoRAG without expensive human annotations, researchers used rejection sampling, a technique that generates plausible retrieval chains from existing RAG datasets. The model is trained on these enhanced datasets, learning to generate sub-queries, sub-answers, and final answers.
During inference, CoRAG offers flexible decoding strategies, such as:
- Greedy decoding for efficiency,
- Best-of-N sampling for optimized accuracy, and
- Tree search for balancing computational cost with performance.
This scalability allows users to control retrieval depth, ensuring an optimal trade-off between accuracy and computational efficiency.
Source: https://arxiv.org/abs/2501.14342
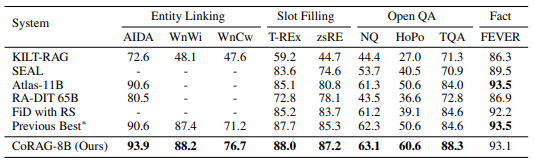
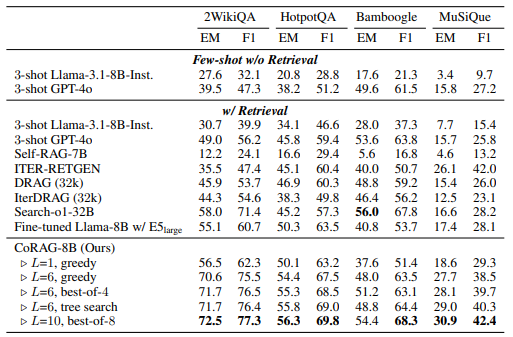
CoRAG has been tested on the KILT benchmark and multi-hop QA tasks, showing improved results compared to existing RAG models. The approach appears to be particularly effective in tasks that require retrieving and synthesizing information from multiple sources.
KILT benchmark (source: https://arxiv.org/abs/2501.14342)
Multi-hop QA tasks benchmark (source: https://arxiv.org/abs/2501.14342)
The AI community has noted the potential impact of CoRAG. Deepesh Jain, a founder & CEO of Durapid Technologies, commented:
This is a big step forward for RAG! Traditional methods often miss key details, but CoRAG’s iterative approach makes retrieval smarter and more dynamic. Letting models refine searches like humans do could unlock better answers for complex queries.
Moreover, Ekaterina Baru, a senior machine learning engineer at Velotix, highlighted the resemblance to human research methods:
This is a fascinating approach—using iterative retrieval to refine queries really mirrors how we, as researchers, naturally dive deeper into a problem. The performance gains on multi-hop QA tasks are impressive, and I’m curious how the trade-offs between longer chains and compute costs will evolve in production settings. Excited to see where this leads!
By shifting from static retrieval to an iterative approach, CoRAG introduces a different way of handling AI-driven search and reasoning. This could be useful in areas such as automated research, enterprise knowledge systems, and AI-assisted decision-making, where retrieving accurate and well-structured information is essential.






{kind=link}