
Table of Links
Abstract and 1 Introduction
-
Related Work
2.1. Multimodal Learning
2.2. Multiple Instance Learning
-
Methodology
3.1. Preliminaries and Notations
3.2. Relations between Attention-based VPG and MIL
3.3. MIVPG for Multiple Visual Inputs
3.4. Unveiling Instance Correlation in MIVPG for Enhanced Multi-instance Scenarios
-
Experiments and 4.1. General Setup
4.2. Scenario 1: Samples with Single Image
4.3. Scenario 2: Samples with Multiple Images, with Each Image as a General Embedding
4.4. Scenario 3: Samples with Multiple Images, with Each Image Having Multiple Patches to be Considered and 4.5. Case Study
-
Conclusion and References
Supplementary Material
A. Detailed Architecture of QFormer
B. Proof of Proposition
C. More Experiments
4.4. Scenario 3: Samples with Multiple Images, with Each Image Having Multiple Patches to be Considered
Thirdly, we assess the method in a comprehensive manner where each sample contains multiple images and considers multiple patches within an image. Specifically, we utilize the Amazon Berkeley Objects (ABO)[7] dataset, consisting of samples of e-commerce products. Each product is accompanied by multiple images illustrating various characteristics from different perspectives. Typically, one of these images provides an overview of the product, commonly displayed first on an e-commerce website. We refrain from utilizing the product title as the caption due to its limited descriptiveness. Instead, we rely on manually annotated captions [27] from the same dataset as reference captions to assess the quality of our generated captions. Specifically, there are 6410 product samples, and we randomly partition them into train, validation and test subsets with a ratio of 70%, 10%, 20%. Each product comprises images ranging from 2 to 21. In this dataset, we must consider both image details and multiple images simultaneously. Consequently, we apply MIL in both image and patch dimensions. To be specific, we employ AB-MIL (Equation 5) to generate image-level embeddings for images. Each image is then treated as an instance and passed to the QFormer as a sample-level MIL. Since the number of patches per sample is much smaller than that of WSIs, we do not apply PPEG in this setting.
We primarily compare the proposed method against BLIP2 with different settings: 1) Zero-Shot: Directly feed the overview image of a sample to query the BLIP2 without fine-tuning; 2) Single-Image: Fine-tune the original BLIP2 with the overview image of each product; 3) Patch-Concatenation: Fine-tune the original BLIP2 with multiple images, with patches concatenated in one sequence. We
repeat the experiments three times with different random seeds and report the mean and standard deviation. As shown in Table 2, results from the ABO dataset demonstrate that our method outperforms the use of a single image or images
with concatenated patches mostly, underscoring the efficacy of considering MIL from different dimensions. It is worth noting that fine-tuning BLIP2 with a single image has already achieved respectable performance, indicating that the overview image contains general information about a sample. Additionally, while fine-tuning BLIP2 with multiple concatenated image patches shows good results in terms of ROUGE, it should be emphasized that the concatenation results in a complexity of O(RNP). In contrast, the proposed method applied on different dimensions will only have a complexity of O(P + RN), ensuring computational efficiency.
Unlike the ground-truth captions that describe the details of a product, we find the zero-shot BLIP2 tends to provide less detailed information. This discrepancy can be attributed to the model’s pretraining, where it is predominantly tasked with describing an overview of an image, with less emphasis on details. Nonetheless, when we input multiple images for a single item, the model showcases its capacity to discern what aspects should be emphasized. This capability arises from the presence of common patterns across different images that collectively describe the item, thus affirming the effectiveness of utilizing multiple visual inputs.
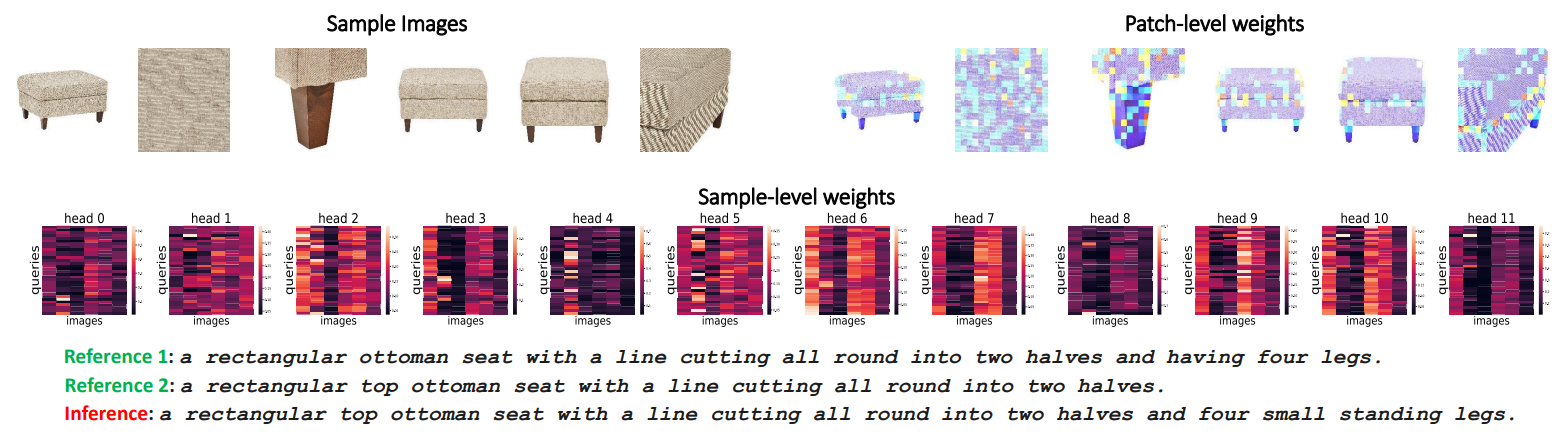
A visualization example can be seen in Figure 6, featuring an ottoman seat composed of six images. We present both patch-level attention weights and image-level attention weights. In the patch-level attention weights, the model emphasizes edges and legs of the seat, leading to an output that recognizes the rectangular shape and four legs. The image-level attention weights show maps for all twelve heads. Each row in a map represents a query, and each column represents an image. Notably, different heads and queries exhibit varying attention patterns towards images. Generally, the first, fourth, and fifth images attract the most attention.
4.5. Case Study
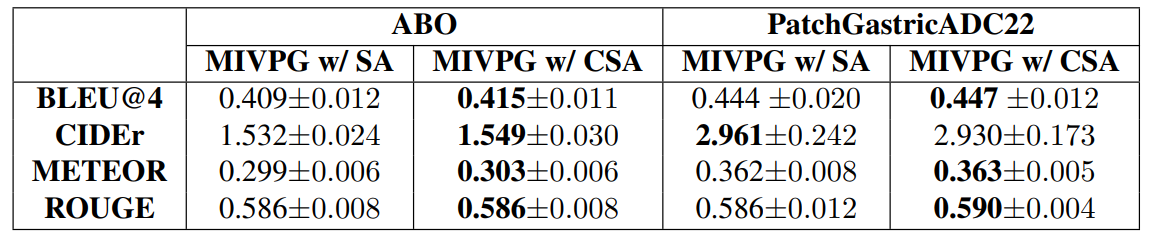
To assess the impact of instance correlation, we conduct additional ablation studies involving self-attention (SA) and correlated self-attention (CSA). Please refer to Table 3 for the results. The results in PatchGastricADC22 indicate that self-attention and correlated self-attention among instances yield similar performance. However, in the case of ABO, correlated self-attention outperforms self-attention. We posit that this discrepancy arises from the fact that images of e-commerce products typically do not exhibit explicit correlations. In the correlated self-attention mechanism, images are initially aggregated into query embeddings, which may help reduce the impact of irrelevant information. Due to space constraints, we have postponed additional case studies to supplementary C.2 and more visualization results to supplementary C.3.
:::info
Authors:
(1) Wenliang Zhong, The University of Texas at Arlington ([email protected]);
(2) Wenyi Wu, Amazon ([email protected]);
(3) Qi Li, Amazon ([email protected]);
(4) Rob Barton, Amazon ([email protected]);
(5) Boxin Du, Amazon ([email protected]);
(6) Shioulin Sam, Amazon ([email protected]);
(7) Karim Bouyarmane, Amazon ([email protected]);
(8) Ismail Tutar, Amazon ([email protected]);
(9) Junzhou Huang, The University of Texas at Arlington ([email protected]).
:::
:::info
This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::







{kind=link}