
Today, I will guide you through the whole process of creating a custom AI model, which is able to recognize images. We are going to:
- Set up the environment
- Prepare some data for training the model
- Choose a pre-trained model for fine-tuning
- Adjust the configuration
- Train the model
For our purposes, we will use Paddle OCR. Let’s learn a bit more about it.
Paddle OCR
That is an awesome toolkit for training models. Paddle OCR (Optical Character Recognition) is an AI technology that extracts text from images, videos, and more. It is an open-source framework designed to detect and recognize characters with impressive accuracy. Detection focuses on locating text within an image, while recognition converts that text into usable data.
This practical guide will walk you through the entire process, from gathering and preparing your dataset to creating a ready-to-use OCR model tailored to your needs.
Set up Your Environment
It is crucial to set up your environment properly before diving into the code. The precise setup plays a significant role in the smooth execution of the fine-tuning process. Make sure that your machine has a suitable GPU, sufficient memory, and storage.
To simplify the process, clone the Google Colab notebook, which I prepared for this article. It will allow you to jump right into the OCR journey without the need to set up hardware. This notebook includes step-by-step explanations and is available in the GitHub repository linked below.
Prepare the Data
The sample dataset for this tutorial can be found on
After that, you can create the training and evaluation .txt files to prepare the dataset for training. The dataset consists of two folders: Train for training data and Test for evaluation.
Mapping each image with its corresponding JSON file, we will use only those annotations with 8-point coordinates since PaddleOCR specifically works with these.
Even if you already have annotated text files, these scripts serve specific purposes crucial for the fine-tuning process and adapting the data to the format expected by PaddleOCR:
- Detection: The script generates a text file where each line corresponds to an image path and its associated bounding box coordinates along with the transcribed text. This file is used to train a model to detect text regions in images.
- Recognition: The script not only generates a text file that links image paths to transcriptions but also crops and saves individual text regions as separate images. This file is used to train a model specifically on recognizing and transcribing text within those regions.


Choose a Pre-Trained Model
Selecting the appropriate pre-trained model is crucial for the success of your OCR project. Pretrained models can be found on the
Furthermore, I have discovered a collection of highly relevant pre-trained models on this
Take a look at some factors, which are good to consider while choosing a model:
- Task Type (Detection vs Recognition):
-
Text Detection Models: Search for models specifically designed for detecting text regions within an image.
-
Text Recognition Models: Choose models that transcribe isolated text regions into readable data.
-
- Language Support:
-
Pick a model that supports the language(s) you need. PaddleOCR offers models tailored for languages like English, Chinese, Japanese, Korean, etc.
-
- Model Size and Speed:
-
Lightweight Models: Optimal for fast inference on devices with limited resources (e.g., mobile devices).
-
High-Accuracy Models: Better suited for applications where accuracy is more critical than speed, although they require more computational power.
-
- Pre-training Dataset:
- Customization Needs:
- Some pre-trained models allow more extensive fine-tuning. It is beneficial if your data is very specific or different from typical OCR datasets.
Adjust the Configuration
Now, let’s take a look at the configuration settings of our project.
Configuration files play a critical role in controlling the behavior of your model during training, evaluation, and inference processes. These files allow you to set parameters that define how your model operates, from data loading to model architecture and optimization.
Here is a detailed explanation of the main parameters in the configuration file:
-
use_gpu: true: Indicates that the training should use a GPU, essential for handling large datasets and complex models efficiently.
-
epoch_num: 500: Specifies the number of epochs, or complete passes through the training dataset. More epochs typically lead to better learning but increase training time.
-
save_model_dir: output/detection: Defines the directory where the trained model checkpoints will be saved. This is important for resuming training later or for inference.
-
eval_batch_step: [0, 2000]: Sets the evaluation frequency during training. The model is evaluated every 2000 iterations to monitor its performance.
-
pretrained_model: pretrained_models/detection/MobileNetV3_large_x0_5_pretrained.pdparams: Specifies the path to the pre-trained model that will be used as a starting point for fine-tuning.
Train the Model
Finally, after your datasets, models, and configuration files are ready, you can begin the training process. You need to follow these steps:
-
Load Configurations: Use the configuration file to load the necessary settings for the training process.
-
Initialize the Model: Set up the model architecture according to the specified backbone (e.g., MobileNetV3) and head (e.g., DBHead).
-
Load and Preprocess the Data: It will be loaded and transformed (e.g., resized, normalized, augmented) according to the settings in the configuration file.
-
Launch the Training Loop: The model undergoes iterative training, where it learns to minimize the error between its predictions and the actual data.
-
Save Checkpoints: It is a good practice to repeatedly save the model’s state because it allows to make recoveries and further fine-tuning.
-
Supervise Evaluation During Training: Keep an eye on the model’s performance on the validation dataset to ensure it is learning effectively.

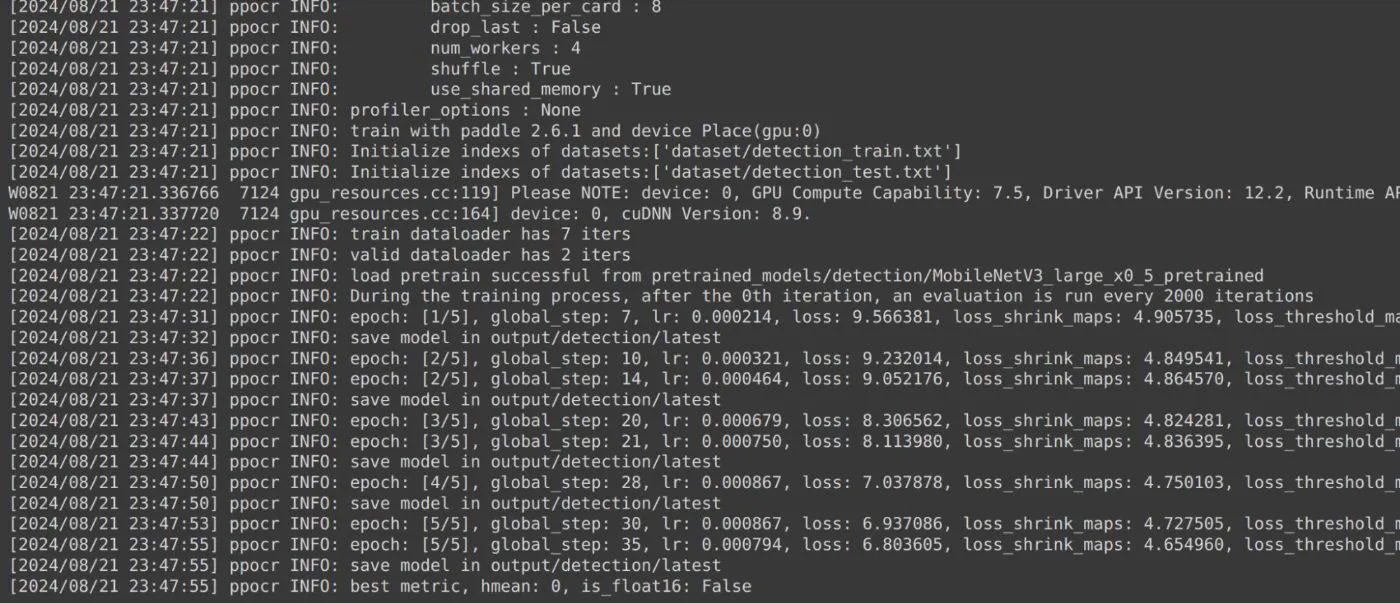
Final Result
After the training process is complete, the final model will be converted into an inference model. This inference model is optimized for deployment, allowing you to use it in real-world applications to perform OCR tasks on new data.
The inference model will be saved to a specified directory. It is ready to be integrated into your projects for efficient and accurate text recognition.


Conclusion
By following this guide, you’ve learned how to fine-tune PaddleOCR on your custom dataset. That was a long journey:
- setting up your environment
- preparing data
- selecting the right pre-trained model
- configuring the training process,
- ultimately deploying a customized OCR solution
Congratulations! Now, you are entirely ready to create robust and accurate models tailored to your specific text recognition needs.
For more details, please check the complete project on GitHub.






{kind=link}