OpenAI has introduced new speech-to-text and text-to-speech models in its API, focusing on improving transcription accuracy and offering more control over AI-generated voices. These updates aim to enhance automated speech applications, making them more adaptable to different environments and use cases.
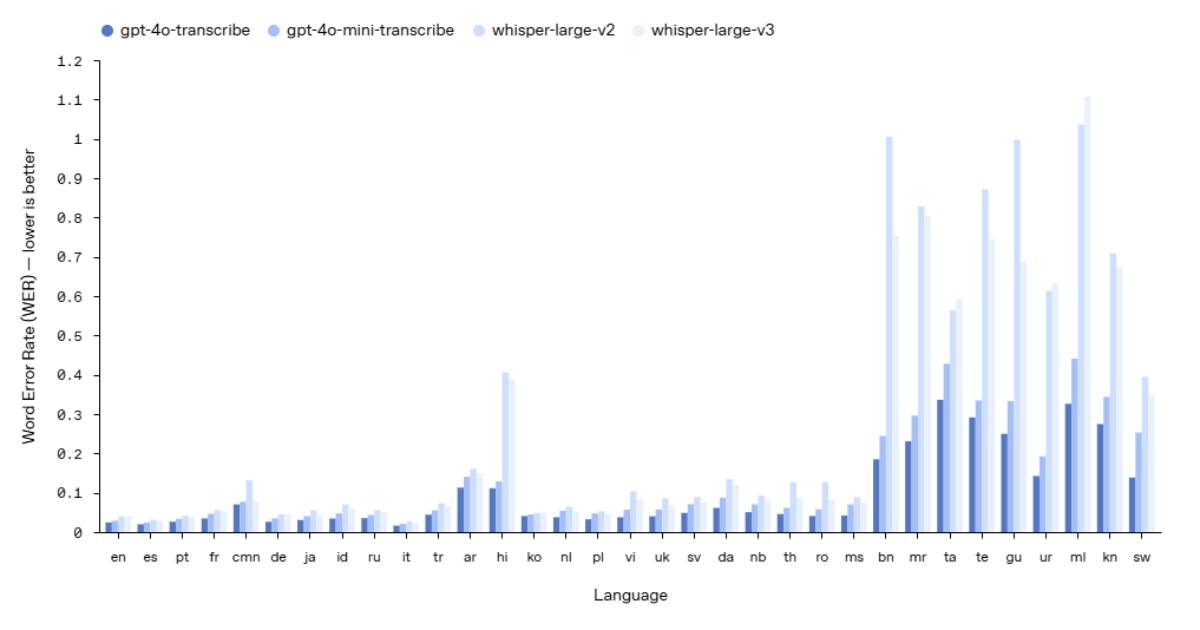
The new gpt-4o-transcribe and gpt-4o-mini-transcribe models improve word error rate (WER), outperforming previous versions, including Whisper v2 and v3. These models are designed to handle better accents, background noise, and variations in speech speed, making them more reliable in real-world scenarios such as customer support calls, meeting transcriptions, and multilingual conversations.
Source: OpenAI Blog
Training improvements, including reinforcement learning and exposure to a more diverse dataset, contribute to fewer transcription errors and better recognition of spoken language. These models are now available through the speech-to-text API.
The gpt-4o-mini-tts model introduces a new level of steerability, allowing developers to guide how the AI speaks. For example, users can specify that a response should sound like a sympathetic customer service agent or an engaging storyteller. This added flexibility makes it easier to tailor AI-generated speech to different contexts, including automated assistance, narration, and content creation.
While the voices remain synthetic, OpenAI has focused on maintaining consistency and quality to ensure they meet the needs of various applications.
Reactions to the new models have been positive. Harald Wagener, a head of project management at BusinessCoDe GmbH, highlighted the range of available voice options, saying:
Great playground to find the perfect style for your use case. And it sounds amazing, thanks for building and sharing!
Luke McPhail compared OpenAI’s models to other industry offerings, stating:
First impressions of OpenAI FM: It does not quite match AI audio leaders like ElevenLabs, but that might not matter. Its huge market share and easy-to-use API will make it appealing for developers.
Developers have also appreciated the models for their seamless integration and usability. Some noted that while OpenAI’s speech models may not yet surpass specialized audio solutions, their accessibility and well-structured API make them a practical choice for many applications.
These new speech-to-text and text-to-speech models are now available. Developers can integrate them into their applications using the Agents SDK, streamlining the process of adding voice capabilities.
OpenAI plans to further improve the intelligence and accuracy of its audio models while exploring ways for developers to create custom voices for more personalized applications. Ensuring these capabilities align with safety and ethical standards remains a priority.






{kind=link}