
Abstract
This article offers an in-depth technical research-minded view of LM Cache operates and how the caching machinery improves the efficiency, scalability, and cost reduction of Large Language Model (LLM) deployment. We study different types of caching architectures and mechanisms, how they can be integrated together with the new AI infrastructure and evaluated for performance. Examples from the field detail how some of our largest customers are deploying LM Caches in practice and what they have learned along the way. Finally, we conclude by highlighting some challenges, limitations and future directions in this fast-evolving field.
Introduction
Think of an AI assistant that has to constantly provide the same answers all day long for hundreds of time! This isn’t a result does it have to re-generate every answer from scratch, literally every time? While LLMs (think GPT-4, PaLM etc) are transforming everything from customer support to code generation their deployment at scale is stymied by latency requirements, computational cost and memory footprint. In production, each query to a large model may cost seconds and considerable GPU compute. As model sizes and user expectations increase, the need for fast inference becomes more important than ever.
Taking all of these into account, the LM cache emerges as a very smart answer to these problems by caching and reusing already calculated results. Caching is fundamentally what enables our system to remember all which it has seen before. The general idea of the concept is not new in computer science, but it has had a potential breakthrough in LLM itself for significantly larger throughput and a vast decrease in response time. Like model distillation (creating smaller, faster models), retrieval-augmented generation (bolting on external knowledge bases), and vector databases for semantic search, LM Cache augments other optimization techniques. With a final measure of caching mechanisms deployed in conjunction with these methods large-scale LLM deployments can endow them with not only the higher throughput and lower latency but also impressive savings across the board — making them far more practical to adopt.
Foundations of LM Cache
The concept of LM cache is simply a reuse computing for not overwork. In the case of LLM inference, caching can exist at different levels of granularity:
-
Prompt-level cache: Cache the entire output to a given input prompt. If our model receives the same prompt again, it returns the cached output without running the model. This is effectively memorizing the model’s response to entire queries, at the highest-level cache. It is particularly powerful for tasks that involve the reapplication of the same query many times (e.g. Q&A model with a single question asked repeatedly) This could be implemented, for example (sample implementation in the functions promptify and getPossibleResults) as a simple dictionary that maps prompts to possible results e.g.
Pseudocode: prompt-level cache integration prompt_cache = {} # A dictionary to store prompt->response mappings def generate_response(prompt): if prompt in prompt_cache: return prompt_cache[prompt] # return cached answer result = model.generate(prompt) # expensive LLM call prompt_cache[prompt] = result # store for next time return result -
Token specific caching: We cache intermediate results for each token in a sequence instead of caching whole responses. Autoregressive LLMs generate text one token after the other. This is because without caching, the entire previous context will have to generated again from start for every new token to be created. Token level caching is the process of stores intermediate state of model tokens like the activations or hidden states in a way that, when producing next token, the model can skip recomputing what it already did for prior tokens. This is highly connected to the key–value cache in transformer models, more on this below.
-
KV cache (Key-Value cache) : LLMs based on transformers use self-attention, which means that each token pays attention to all of the ones that came before it. Frameworks cache the “key” and “value” projections for previous tokens and only add new ones to avoid having to compute attention over the whole sequence again. neptune.ai. This KV cache speeds up autoregressive decoding, which is an important GPT-style optimization. It cuts the work per step from O(n²) to O(n) without changing the outputs (Yazdani Aminabadi et al., 2022; Pol, 2025) arxiv.org. By default, libraries like Hugging Face Transformers do this with use_cache=True during generation, which means that only new tokens are processed. A simple pseudocode loop shows how past_kv grows with each iteration.
Pseudocode: using KV cache in an autoregressive decoder loop past_kv = None for token in prompt_tokens: output, past_kv = model.decode_next(token, past_key_values=past_kv) # past_kv now contains keys/values for all tokens up to current oneThe above loop accumulates the key-value pairs to be carried forward as past_kv such as that model. Then model.decode_next can use the cached context and need not recompute it. The KV caching makes the quadratic slowdown now avoidable, and transforming models to work with this form of storage is crucial for the continued efficiency of transformer inference, particularly if GPT-4 like models are able to generate much longer continuations far more efficiently.
-
Embedding cache: LLM follows the same procedure with all text input as firstly it converts tokens into vector embeddings. Calculating these embeddings (especially a large contextual embedding model) can cost nearly as much as running the full LLM itself, so why do it again for some common tokens/phrases? Embedding Cache — a cache where the vector representations of common inputs are stored. (Paul, 2025) rohan-paul.com. For example, we can cache those embeddings instead of computing them from scratch if application encodes the same sentences or document chunks many times (in a retrieval-augmented setup) This will save time and guide the style of such representations. rohan-paul.com . Embedding caching is a natural fit for retrieval pipelines and semantic search, as it caches the “input features” before they hit the big model.
-
Multi-query attention caching: Multi-Query Attention (MQA) is a type of Transformer attention in which all heads use the same keys and values as input to their attention function (Shazeer, 2019) arxiv.org. Typically, with 12 or 24 heads, each head has its own keys and values. This means that the cache stores 12x or 24x vectors for each token. Instead, MQA caches just one set, and heads keep their query projections while looking up a shared key-value store. In one benchmark (Shazeer, 2019) (arxiv.org; huggingface.co), this cut memory and bandwidth overhead by a huge amount, from about 15 GB to less than 400 MB on a 16k-token context. There is only one shared cache instead of 100% memory overhead per head.
Noam Shazeer first suggested MQA (and its grouped-query versions) in One Write-Head is all we Need (huggingface.co). It is used in PaLM, Falcon, MPT, and BLOOM to make longer contexts work better. It also makes inference faster because it needs to fetch less data from memory, which means it can do attention computations faster (huggingface.co). In theory, MQA is a smart way to cache data for the architecture, so that the number of trainable parameters doesn’t go up as the number of heads or the length of the context grows.
All of the aforementioned caching levels the straightforward principle that system shouldn’t re-compute what you have already done. Because of the self-attention mechanism, the computation of each new token in transformer-based LLMs frequently depends on earlier tokens. Whether at the prompt level or deep within the model, caching the outcomes of those earlier calculations allows subsequent operations to jump directly to the final result. Significant improvements in speed and resource usage result from this.
LM Cache Architectures and Strategies
Since not all workloads are the same in LLM systems, a large number of architectures and strategies have been designed by engineers to maximize cache hits and reduce overhead. Here are some key approaches:
- Static vs. Dynamic Caches: Static caches come with pre-filled input/output pairs, which makes them great for predictable workloads. These are caching solutions for common questions or fixed-prompt outputs, like FAQs or test-case responses. Dynamic caches, on the other hand, fill up as a system runs, changing to fit traffic patterns, changing query distributions, and usage spikes. They actually “learn” from user traffic to improve hit rates. In real life, systems limit dynamic caches by using eviction policies based on current demand, which automatically gets rid of old items. Dynamic caching is preferred for most real-world deployments because it can be changed. MeanCache is a good example of this. It is a learning-based cache that fine-tunes a small model to find and store paraphrased queries in addition to exact matches. It updates intelligently with each new request (Wu et al., 2024). rohan-paul.com. MeanCache is an example of learning-based dynamic caching. It changes based on how users behave, keeping it useful and relevant in real-time production and high-traffic settings.
- Distributed and Federated Caching: In big deployments with many LLM instances on different servers or pods, per-machine caches don’t work for cross-server reuse. For example, if Server A processes and caches a query, Server B has to recompute the answers even though it can’t access Server A. Distributed cache fix this by sharing entries through an external store, like Redis. NVIDIA’s Triton Inference Server added distributed caching in 2023, even though network hops only added about 8% more latency than local in-process caches. (Lorello et al., 2023; Paul, 2025) rohan-paul.com. Then, servers cache once and use the results again, which cuts down on unnecessary re-computation and makes the system much more scalable and consistent. Federated caching makes this possible across sessions or devices. For example, a user’s browser might cache model outputs locally and send hits to a shared server cache for other users. These patterns work with both centralized clusters and edge deployments, so they can work with different architectures. Keeping cache coherence is the biggest problem. This means making sure that caches on different nodes stay in sync and that invalidations or updates spread correctly (see the Challenges section).
- Layer-wise caching and GPU/TPU memory optimization: Caching is not limited to the output; it can also be used at particular LLM layers. To avoid having to compute an expensive intermediate layer again on a cache hit, one could, for instance, cache the outputs of that layer for specific frequent inputs. Additionally, it might make sense to cache only the most expensive activations or use on-chip memory for caches on hardware accelerators (GPUs/TPUs), where memory is valuable. Inference analogs of techniques such as gradient checkpointing, which involves trading computation for memory during training, allow you to selectively preserve specific layer outputs. While maintaining a manageable memory footprint, a well-designed layer-wise cache can significantly reduce repeated computation.
- Cache Granularity and Keys: Choosing a cache index is a smart move. Exact-match keys on the full prompt string are easy to use, but they break easily—any change misses the cache. To get more hits, systems use embedding-based semantic hashes that treat prompts as the same even if the wording is different, or prefix/chunk keys that match overlapping segments. After processing a stable prefix, “prefix caching” takes a snapshot of the model’s KV state. This way, a new prompt that starts with that prefix can quickly move to that state. The open-source vLLM project does this automatically by finding shared prefixes in incoming requests and reusing cached tensors. This speeds up processing of long prompts by a huge amount (Kwon et al., 2023). This is similar to web caching, where browsers reuse parts of a page when 90% of it stays the same. With chunk-level indexing, sub-sequences can be reused, so even if there are partial overlaps, they still hit the cache. This means that reuse is maximized when full-response caching doesn’t work. For LLMs, caching the computation of a fixed background document and only encoding the user query that was added saves a lot of computing power and increases throughput.
- Cache Size and Eviction Policies: Because cache memory is limited, LLMs use policies like LRU or LFU to decide which entries to keep and which to evict. This frees up space for new data. In addition to evicting items based on age or frequency, LLM caches must also deal with relevance decay and model or data updates by removing old items. In 2024, research showed that learning-driven eviction works: caches that were trained to find and get rid of keys with little future value (Xiong et al., 2024). These adaptive, “smart” eviction systems, which are made for LLM workloads, will likely become the norm for managing caches efficiently.
In short, building a LM cache is a delicate balance: We want to maximize hit rate while minimizing overhead such as memory consumption and volatility. If this means you have to work those machine translation systems harder, then be my guest! These strategies (static vs. dynamic, distributed architectures, pulling in the cache hit on terminology by manufacturing it at client time with former example languages) are all tricks which may help you to do more with caching without tripping over cache-related pitfalls. Different applications may blend these methods and apply For example, a production system could use at the application level a semantic prompt cache (for instances when user queries resemble one another) and at the model level a KV cached (to speed up token generation), great bundle an embedding to be used by retriever component Another (caching) advantage is that this is a scalable and can be layered everywhere.
Architecture Diagram of LM Cache in an LLM Inference Pipeline
Below is the reference architecture depicting LM Cache’s integration within a typical LLM inference flow:

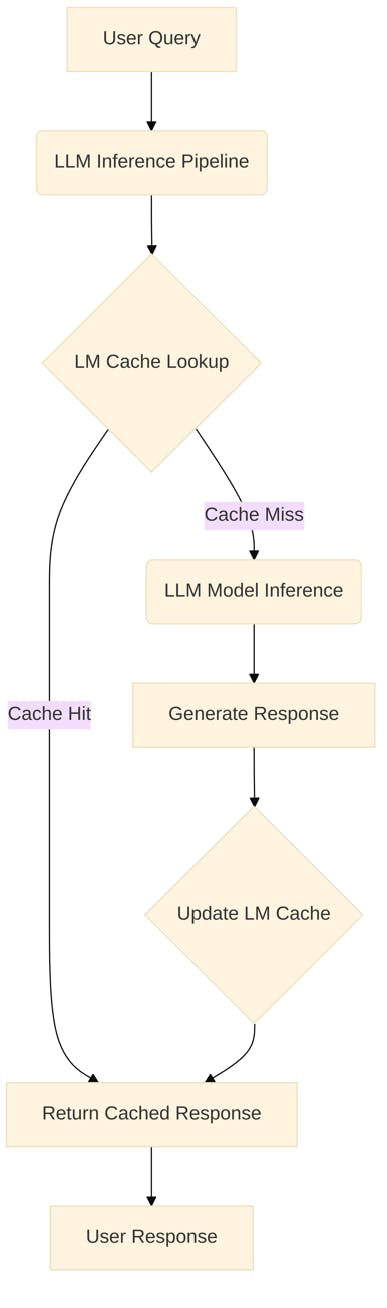
Workflow Diagram Comparing Cached vs. Non-Cached Inference Requests
To further understand the benefits, consider the workflow comparison between cached and non-cached inference requests:

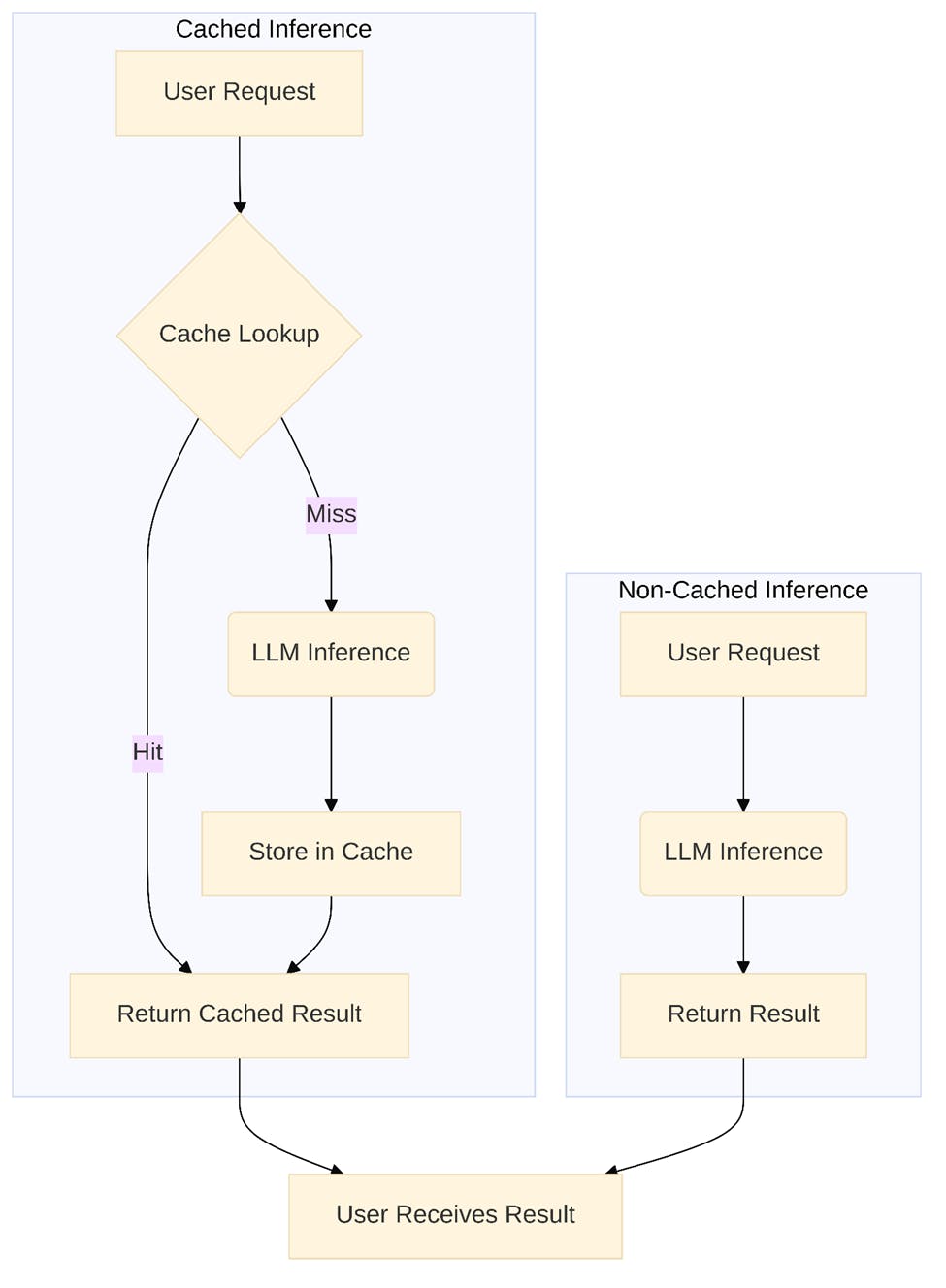
Integration with Modern AI Infrastructure
Caching LM doesn’t stand alone–it will derive from the wider application ecosystem in AI. Here we look at how caching fits into a variety of infrastructures and frameworks:
-
Framework Support (Hugging Face, DeepSpeed, etc.): The good news is that KV caching is integrated into the majority of contemporary AI frameworks. To avoid redundant computation, Hugging Face Transformers, for example, allows you to set use_cache=True (the default in generate()) to automatically return and reuse previous key/value states. huggingface.co. KV caching is used for incremental decoding in Microsoft’s DeepSpeed-Inference, which is crucial for scaling large autoregressive models. Kernels are tuned appropriately. (Yazdani Aminabadi et al., 2022) arxiv.org. Cache decoding is also accelerated internally by NVIDIA’s TensorRT and ONNX Runtime.
In order to maximize speed, model architectures now assume caching in addition to software stacks. UC Berkeley’s vLLM presents PagedAttention to manage GPU KV cache, paging it similarly to virtual memory and sharing identical prompt prefixes. (Kwon et al., 2023)blog.vllm.ai. FlashAttention and xFormers optimize attention only for new tokens. This block-based approach reduces memory fragmentation, lowers overhead to under 4%, and delivers up to 24× higher throughput than standard Transformers. blog.vllm.ai. Additionally, you can anticipate even wider caching support across popular frameworks as these research advances develop. -
Retrieval-Augmented Systems (RAG and Vector DBs): Caching can greatly improve performance in retrieval-assisted LLM pipelines, such as question answering over a vector database. You can cache retrieved passages, final answers, or embeddings for semantically similar queries rather than using similarity search to retrieve new documents and calling the LLM each time. For example, the 2025 Proximity layer by Malladi et al. reduces retrieval latency by up to 59% with negligible accuracy loss by reusing passages for near-duplicate queries. rohan-paul.com. Caching retrieval results reduces the load on vector engines and scales systems because many user queries overlap (Chaidez, 2025). Caching query outputs is advised by providers such as Redis and Pinecone. In the end, caching saves duplicate embedding or retrieval effort for frequently asked or comparable queries.
-
Serverless and Edge Deployments: These are addressed by caching in the case of serverless LLM deployments (a.k.a. AWS Lambda) and edge scenarios (on-device or in-browser LLM inference) that need to mitigate expensive cold-starts and tight resource limits. For serverless setups—in which models do not persist between invocations—an external store (like Redis or DynamoDB) enables the completion of each function call to check previous outcomes, so that redundant work can be skipped. There is potential to cache recent inferences or embeddings (e.g., user names, common commands ) on things like smartphones or small IoT type edge devices, to reduce latency and save battery. While limited memory and privacy will be a consideration, optimized compressed caches should start to appear soon for ultra-efficient edge inference.
-
Caching and Model Parallelism: Production-scale LLMs exceed single-GPU or machine capacity, so distributed inference requires caching. Typically, each model shard caches the key/value states for tokens it processes. When a new token arrives, parallel shards coordinate to fetch and update their cached states, avoiding redundant recomputation and memory overhead. Libraries like DeepSpeed and FasterTransformer implement this: with pipeline parallelism, each stage caches its outputs to avoid recomputing all layers per token. Tensor parallelism shards KV caches across GPUs, using cross-GPU protocols to synchronize new keys/values and maintain consistency across devices.
Distributed KV caching dramatically reduces inter-node communication and idle time by limiting work to new computations. One whitepaper noted that without caching, shipping the full context for each inference during distributed execution incurs prohibitive network hops. Caching keeps context local, making large-model inference across multiple machines practical.
To summarize, modern AI stacks are more- and more so “cache-aware. Higher level systems are starting to internalize this, from libraries which take care of the mechanics for you to system architecture that shares caches across requests and infrastructure. Caching is something which most LLM services would use, as that’s what the big players in AI (OpenAI, Google and Microsoft for example) have spoken about or done in their respective LLM offerings. Some specifics are well-known like OpenAI’s ChatGPT (not publicly documented but this event in particular is described) presumably utilizing large-scale conversation context caching; Anthropic’s Claude team (coming up next…) deployed a user-visible feat, cached prompts to save cost; Azure AI services Cache through ONNX Runtime and DeepSpeed; and Google’s PaLM model implemented multi-query attention to allow for deep-context caching as well (Chowdhery et al., 2022), Caching is one of the secret ingredients that enables these massive models to be served at scale to millions of users.
Performance Metrics and Evaluation
Alright, in theory caching might sound amazing but how can we measure it? There are few of the common performance metrics that helps you to evaluate the effectiveness of LM caching
- Lower Latency: Less Latency: The main benefit is less latency, which is the time it takes to get an answer. Caching alters the performance curve: a primed cache consistently offers you high throughput and low latency. We do this by looking at the times it takes to make requests with and without cache. A chatbot that usually takes 2 seconds to answer a question will return in 0.2 seconds if it hits the cache, which is 90% faster. The actual speedup depends on the hit rate. For example, if 80% of hits are 1000 times faster, the overall latency will be much better. Teams often talk about p50 and p95 latencies with and without caching. By caching context Anthropic, saw up to 85% less latency on longer conversations. (Anthropic, 2024) anthropic.com. With a 100,000-token prompt, the time to the first token went from 11.5 seconds to 2.4 seconds, which is a 79% decrease. anthropic.com. This greatly improves the user experience.
- Throughput Improvement: With caching, throughput—requests per second (RPS) or tokens per second (TPS)—can go through the roof. This is because caching saves compute by not having to do the same calculations over and over again. The DenseNet benchmark for NVIDIA Triton went from 80 to 329 inf/sec (about 4×) and lighter models saw about 20% gains with response caching. rohan-paul.com. When it comes to LLM serving, vLLM’s PagedAttention uses smarter KV cache management to group requests better, which means it can handle up to 24 times more requests than Hugging Face Transformers. vLLM Blog. In situations with more than one user, measuring throughput is very important. Caching helps keep traffic spikes from happening and keeps the server from getting too full.
- Compute/Cost Savings: This is the dollars-and-cents outcome of caching. Since caching will also save on redundant computation, it actually saves FLOPs which are money (for example when you pay by the GPU hour or API call). The common metric for this is GPU utilization and even total compute time saved. For example, Anthropic claimed that in longer conversations, prompt caching can reduce the token consumption (hence cost) by 90% (Anthropic, 2024), anthropic.com. This was also reflected in the pricing scheme — using cached tokens costs an order of magnitude less than generating them from scratch. bdtechtalks.com. If you evaluated on a test set, with and without cache, you can approximate the percentage of tokens or operations saved by using a cache. Leading to actual money saved on cloud inference costs. In this same sense, you can think of it as energy efficiency — caching saves energy per request, a new and faster growing concern for green AI.
- Hit Rate and Miss Penalty: These are cache-specific metrics. Hit rate: The percentage of the requests (or tokens) that were fulfilled by the cache Higher hit rates means better performance gains in General. These are useful to report, like “our system had a 60% cache hit rate on prompts in prod (X actually X vs Y without cache). The miss penalty is how much slower a cache miss vs hit. In other words, some of the time the addition of a cache introduces some overhead (e.g. computing an embedding for semantic search, or an extra network hop to check a distributed cache) — if the miss still does the full model run plus this overhead, that’s another factor to be mindful of. The other is a well-designed cache with minimum miss penalty (fast hash lookup), then you only pay the actual model compute.
- Memory and Overhead Trade-offs: Caching keeps model outputs or intermediate states, which uses more GPU RAM. For long contexts, KV cache grows in a straight line. For example, a 405 B model’s cache for 16 k tokens can use about 15 GB (about half the model’s size). GitHub. Use metrics like “memory overhead per additional token” or “cache-size ratios” to figure out the trade-offs. Using techniques like multi-query attention, you can cut cache from tens of gigabytes to a few hundred megabytes. This is a 97% reduction for 16 k sequences with little loss of accuracy. huggingface.co. To make sure that the system is designed well, it’s important to compare cache footprints across methods to find the best balance between memory and performance.
- Accuracy/Quality Impact: The model’s output should not change (except for being served with potentially a slightly delayed result) because of caching. However, in certain caching models (namely those that are approximate or semantic), a response could end up not perfectly aligned from the new query. So, we can see if caching produces a quality loss or not. In specific, if we are caching semantically relevant queries to the new query and answer of the new query should still be correct so may examine as accuracy or relevance score. In the academic community, that quality measure is often referred to as the “hit rate”—i.e. what percentage of cached answers were correct? This is not a problem for KV caching (since it has perfect re-use of internal values, so output will be same as un-cached), but higher level response cache can even be A/B tested to make sure that users are happy with cached responses.
- Comparison to Baselines: Researchers usually compare a caching enhanced model to a baseline model without caching to measure the gain. The might discuss also comparisons of different caching methodologies. E.g., Exact-match caching vs. embedding-based caching vs no caching in a dataset of queries, with latency and accuracy for that. vLLM vs vanilla HF server Throughput & Memory. These comparative studies calculate specifics to confirm the intuition that caching as a rule of thumb is a good idea. An example result could be: caching improves throughput 2× and latency by 40%, at the cost of an extra GB (gigabyte) for cache, vs non-caching baseline. It is due to these numbers the overhead of engineering a cache — deploys more than not.
If we evaluate LM caching, it is important to weigh tradeoffs where you can save on compute but at the cost of more memory; lower final latency, but need to handle occasional stale answers. Therefore, it is crucial to look at metrics such as the one above in conjunction. E.g., a 5% risk of an answer being slightly out-of-date might be worth getting your results 10× faster — or it might not (medical advice vs. casual chit-chat have different stakes!).
Both academic papers and industry reports are starting to incorporate caching in their benchmarks, which makes sense given the wide deployments of caches. In a later survey of 2024, it was observed that almost all top submissions to long-context LLM tasks relied on some form of caching or attention optimization to effectively deal with the context length (Chen et al., 2024). The numbers are consistently major victories. Simply put: caching reduces latency, increases throughput and decreases cost per query by both serving new queries faster and avoiding duplicate work. rohan-paul.com. Without these optimizations, any assessment of LLM serving would be far from complete.
Real-World Case Studies
We all know that caching is not just for the sake of an academic argument, and these features are bringing tangible value in practice. Here are some examples on different scenarios, just to show how caching helped :
- Conversational AI (Chatbots/Assistants): Instead of re-encoding the full history every turn, multi-turn chat LLMs caches previous conversations. For instance, they cache the first user question and assistant answer so that only new input is processed on later queries. huggingface.co. This lets systems like ChatGPT respond quickly without having to do all the math again. With caching turned on, Anthropic’s Claude 3 lets developers pin long-lived contexts, which cuts latency by 79% and costs by 90% on a 100k-token prompt. (Anthropic, 2024) anthropic.com. Xiaoice from Microsoft also saves scene responses so that it doesn’t have to say the same polite things over and over. In enterprise bots, answer caching for common questions like “Where is my order?” and “Reset password?” instantly takes care of repeats, so the LLM can only work on new questions.
- Code Completion and Assistance: GitHub Copilot and TabNine uses caching to speed up code completion. The model would have to process the whole context again every time you pressed a key, which would make it very slow. Instead, they store the model’s representation of the prefix in a cache so that only appended characters are processed. This is called prefix caching. A lot of coding prompts repeat themselves (like Fibonacci), so prompt-level caching gives you the same queries right away. It also handles the same developer queries across sessions so they can be used right away. In a forum, an LLM can store popular Q&A pairs (or fine-tune and store them) so that it can quickly answer common questions (Paul, 2025) rohan-paul.com. An AI coding Assistants may also keep internal caches of old code snippets so they can use them to make new solutions from a library of past answers.
- Enterprise “Copilot” Assistants: Lots of companies are deploying AI assistants for internal — sort of like AI copilots that help summary documents, make email drafts, answer business questions from internal data etc. These are typically running over a predefined knowledge base (company docs, wikis, reports) Caching is very valuable here too, at many layers: you can cache internal docs embeddings in order to return them faster; you can cache some common internal queries responses (“how do I file an expense report?”). They can even be cached so that we do not re-generate some results, or partial results like summaries of documents — if two people ask for a summary of the same document it is done only once. Office 365 Copilot by Microsoft probably use cache to make sure that repeated user requests can be served efficiently across an org. The copilot is requested by the CEO’s assistant to analyze a quarterly report, and if the copilot ever comes back again with new analysis questions about that exact same report, one way to save time is to remember what we analyzed already.
- Multi-turn Tools/Agents: Caching can short-circuit loops in the complex AI agent systems (like an agent that plans a task through multiple LLM call, and tool uses). Now consider an agent that answers questions by querying a web service and obtaining results to use as input for an LLM. In such a case, if the same question is asked again, the agent can fetch the previous answer from its cache directly ( instead of re-invoking the tools) or say possibly reuse any search results (caching tools outputs as well as LLM outputs). This is correlated with the concept of planner caches or tool result caching. Intermediary call results are cached by projects like LangChain, so when an agent workflow repeats steps it doesn’t duplicate work. Since they also built Bard and Assistant for internal use, they certainly does a ton of API caching in their internal tooling for the Bard and Assistant like features – it doesn’t make sense to recompute today’s weather twice in an hour, among many other, etc.
- Large-Scale Internet Services: This is especially true in the case of search engines which can drastically benefit from caching LLM responses. For example, Bing Chat serves millions of users and there are a lot of repeated requests. If LLM backend of Bing (which is GPT-4) caches answers to popular questions (“What’s the capital of X”, “How to make pancakes”), it could return them immediately instead of generating from scratch every time. In reality, Bing’s non-LLM search has actually been using query caching for decades; with LLM answers emerging now we are seeing the exact same pattern. Researchers just showed a system that once it found results for a retrieval, caches them that the same search query means great latency reductions. rohan-paul.com. Probably something that both Bing and Google are doing as well behind the scenes. Even open community projects like OpenAI’s ChatGPT have their own user-side caching: if you ask a common question, it may return an answer from the last time this question was asked (cached).
In August 2024, Anthropic’s Claude 3 added Prompt Caching, which was the first time commercial LLMs had caching for users. Anthropic’s servers can store huge, unnecessary contexts, like a book (100,000 tokens). Writing to the cache costs 25% more per input token, but reading cached content only costs 10% of the base rate. Anthropic. The first call saves data; the next calls use the prompt ID to find it and send only new content. Clients said that responses were up to four times faster (latency went from 11.5 seconds to 2.4 seconds) and that the cost of 100,000-token prompts went down by 90% and the cost of 10,000-token prompts went down by about 86%. Anthropic. Conversational agents, coding helpers, and large-document Q&A are all common uses, and a stable context is best for cache hits. Anthropic made caching a strong business case by combining performance improvements with financial incentives. It’s not surprising that competitors like OpenAI and Google are adding similar features to get the same cost and latency benefits.
Another case: OpenAI’s system messages and few-shot examples caching. OpenAI has not elaborated on any of this publicly, but one might wonder if the developers fine-tuned and/or provided few-shot texts in each request, that portion could be cached server side so that the model does not have to re-encode those examples from scratch every time. It’s analogous to Anthropic’s approach. e.g. If you send the same 2000 token system prompt + Instruction on every API call (which many do), OpenAI would cache the model embedding of that inside and just concatenate with your query processed representation. It would be totally transparent to users but (could save them) in a huge amount of compute and would help OpenAI handle more load on their hardware.
Altogether, nearly all major AI companies are using LM caching in the real world. While OpenAI, Anthropic, Microsoft, Google and Hugging Face have all at some point discussed or documented caching strategies with different learnings as a result, most of these share the same conclusion: caching provides a giant performance boost, but it becomes important to manage cache freshness without sacrificing memory and scalability. Stories of “we pushed a cache and saw 30% decrease in our GPU usage while keeping the QPS intact” are not unheard. At the end of the day, these case studies signify one unmistakable fact for AI startups and enterprises across the board — caching is the ticket to turbocharging LLM applications.
Challenges and Limitations
Naturally, caching is no silver bullet. This is, of course, somewhat trivial — if it were easy everyone would be caching all the things after all! There are numerous challenges and limitations in practice that engineers have to work around when deploying the LM caches:
- Cache Invalidation (Stale Data): When the underlying data or an LLM update changes the meaning of a response, cached outputs become stale, just like web cache invalidation problems. A naive fix is to clear all caches when the model is updated. This is easy but wasteful because it deletes entries that are still valid. Some people use the “if not found, fetch fresh” rule, but this can cause them to lose useful data. It’s better to give items a time-to-live (TTL) value so they expire after a certain amount of time, or to version cache keys by model ID or parameters so that you don’t use entries from older models. Adding hashes or timestamps to cache keys helps find old data. Even with these methods, invalidation is still hard because you have to keep track of what changed and whether it affects cached outputs (Paul, 2025) rohan-paul.com.
- Stale Context in Dialogue: When the context changes later in a multi-turn chat, cached responses can become stale. For instance, if you save an answer to question A and then the user adds more information, using the same answer again might miss important changes. To stop this from happening, caches often store the full conversation ID, not just the most recent prompt, or they only cache shorter dialog spans. Instead of saving whole answers, you could save short, context-rich summaries instead. This lowers the risk of them becoming outdated. It’s still hard to manage caches well. Conservative policies (only storing entries that are unlikely to change) or dynamic validation (like hashing key context terms to find changes) can help make sure you don’t serve old content.
- Prompt Variability and Uniqueness: LLMs often deal with very different inputs, so naive caches don’t work very well. For example, creative-generation apps that ask you to “write a poem about X in the style of Y with twist Z” almost never get any hits without semantic caching. Semantic caches try to generalize by matching embeddings, but they only work when queries are very similar. rohan-paul.com. The benefits of caching depend on workload redundancy. KV caches are always helpful for long outputs, but ad-hoc full-response caching doesn’t work as well if no two queries are the same. Partial or modular caching, which means breaking outputs into reusable parts like common phrases or code snippets, can help a little bit. arXiv. But only a few systems use it widely because modular cache indexing and integration are still hard to do.
- Memory Footprint: Caches use a lot of memory, either RAM or GPU, because KV caches for long contexts can be as big as the model itself. huggingface.co. Response caches can also get too big, which means they have to spill over to the CPU or disk. This means that you have to choose between capacity and model size or batch throughput. For example, if you set aside 20 GB of a 40 GB GPU for cache, there won’t be as much space for bigger models or to handle more requests. To address this issue, researchers either compress KV tensors (Shutova et al., 2025) arxiv.org or quantize them (4-bit vs. 16-bit yields ~4× memory savings). The AQUA-KV paper from “Cache Me If You Must” adaptively quantizes caches to only 2–2.5 bits per value, which makes performance almost lossless and footprints much smaller. arxiv.org. Memory is still a problem, but cache overhead is getting smaller all the time.
- Complexity and Engineering Overhead: Caching makes things faster, but it also makes things more complicated. You need to set up thread-safe, low-latency ways to store, look up, update, and invalidate entries, which often means using external stores like Redis for distributed caches, which can fail. To make sure that things are responsive, you may need to do careful engineering, like using non-blocking async calls or lock-free structures. Debugging also gets harder because unexpected outputs might come from old or broken cache data instead of the model itself. That’s why it’s important to have good logging and observability for cache hits and misses. In high-stakes fields like healthcare and finance, teams are worried about key collisions and data privacy. A single collision could send another user’s response to the wrong person. So, caching has high development and maintenance costs that need to be weighed against its benefits.
- Security and Privacy: If not managed correctly, caching sensitive prompts and outputs can make private data public. In multi-tenant systems, always limit cache access to requests that have been approved and scope entries to one user or session. Caches also run the risk of side-channel attacks, which let hackers see other people’s queries. To reduce the risk, limit or encrypt sensitive cache contents. However, encryption can make semantic matching harder. Also, rules like GDPR may treat cached AI outputs as stored data, which means they have to be deleted if the user asks for it. As AI caching becomes more common, these security and compliance problems become even more important.
- Cache Coherence in Distributed Systems: Distributed caching lets you make copies of data, but it has problems with consistency. For example, updates or invalidations in one instance aren’t always seen by others, and when two replicas miss the same cache at the same time, they might have to recompute and race to write the same entry. To stop duplicates, you need atomic operations or locks. For example, Redis’s atomic commands support this. Medium. To build a distributed cache, you need to either choose strong coherence protocols or accept eventual consistency with occasional stale reads and writes. Redis. Testing and tuning these strategies becomes especially hard in LLM serving, where cache entries can be very large or keyed by complicated embeddings. escholarship.org.
Nevertheless, the overall performance gains of caching generally significantly exceed this for many purposes. Thus, it can’t be a massive surprise that almost every enterprise-spanning LLM service involves caching of both one form or any other, and the difference is anyone putting this design work in to cope with the pitfalls. Mitigate the risks: Cache stuff that is not ultra-sensitive (or just changes slowly) + Use a lot of cache invalidation strategies + Keep an eye on the hit rate/ram usage and Have fallbacks (if something funky happens with your cache, system will work, it will be just slow). We are starting to see better tools and libraries to handle much of that automatically (for example, framework-level encrypting cache or auto-invalidate hooks on model updates).
LLM is extremely powerful, but not free as we have seen and adds an additional layer of complexity to LLMs — the cache. One of the more-known computer science thought experiments goes like this: There are only two hard things in Computer Science: cache invalidation and naming things. LLM academics now know the first one! But with good design, the trade-off can be managed, and immense benefits can be realized.
Future Directions and Research Opportunities
The LLM cache field is highly dynamic, with numerous exciting avenues that researchers and engineers are investigating to further expand its capabilities:
- Adaptive and Intelligent Caching: Machine learning can help with caching and eviction policies. For example, RL agents try to get the most long-term rewards (hit rate × correctness). They can prefetch data they think they will need, like OS read-ahead, cache popular results during busy times, and get rid of entries that aren’t worth much. Speculative execution occurs when caches actively calculate and save data that is likely to happen. LLM-based meta-learning can guess which intermediate calculations will be expensive and store them in a cache. Reinforcement learning can also manage eviction by getting rid of entries that are not likely to be useful in the future. This includes things like sorting through software bugs, like summarizing streams of code issues and giving detailed diagnostics on request. Studies from early 2025 look at self-tuning adaptive caches that are based on query patterns (Zhang et al., 2025). As workloads become more diverse, static policies like LRU become less effective, making dynamic, learning-based caching strategies more and more important.
- Cache Compression and Efficient Storage: Quantization and pruning are two methods that cache slimming uses. AQUA-KV compresses KV tensors to only a few bits with little loss of quality (Shutova et al., 2025). Pruning, such as dropping stopword KVs, gets rid of entries that aren’t needed. In long contexts, Anchor Attention keeps only “anchor” token KVs and compresses the rest (Sun et al., 2024). Experimental “lossy” caches take vectors that are similar and combine them into one. High-bandwidth memory or storage-class memory (Optane) can spill KV caches with P99 latency trade-offs on the hardware side. This could lead to the rise of disaggregated cache servers that can grow without needing more compute.
- Cross-Modal and Cross-Domain Caching: Multimodal LLMs and even video translation need special caching. For instance, storing image embeddings lets you skip reprocessing images you’ve already seen, and caching parsed audio snippets makes voice assistants work faster. For each type of data, you need a different strategy. For example, perceptual hashes for images and audio fingerprints for audio. Federated caching across edge devices can share common results privately, which is in line with federated learning’s privacy guarantees. Like a global browser cache for AI assistants, community caches let many users or devices add to a shared pool (using homomorphic encryption or secure enclaves). This lets you answer common questions from the cloud without giving away personal information.
- Caching in Training and Fine-tuning: Caching can also be used for training and fine-tuning LLMs, not just for inference. To avoid disk I/O, large-scale runs already keep tokenized datasets in memory. Training-time caches store intermediate states in a more innovative way. For example, multi-task models can use a sequence’s representation across tasks instead of sending it again. Storing biases or gradients that are used often in a cache also cuts down on unnecessary computing. It mainly helps with research, but it also cuts costs in continual learning or RLHF by skipping steps that are repeated. Google’s Retro (2022) used a cache of text chunks as a differentiable retrieval layer. This stopped full backprop through them and saved a lot of time in training. For efficiency, future ML pipelines will probably use similar caching.
- Cache Governance and Quality Control: Another important change that needs to happen in the future is regularly checking cached responses to keep the user experience good. If an LLM’s cached answer barely passed the filters, user feedback, like repeated rephrasing, could mean that it needs to be changed or removed. This would create a feedback loop that keeps improving the cache and turns it into a living knowledge base. Scheduled background jobs can recompute and update the top cache entries as the underlying model is retrained or fine-tuned. This way, popular answers get better generations. This method is similar to how search engines refresh cached pages when the source content changes. Systems can balance caching’s performance gains with long-term answer accuracy and quality by using feedback-driven invalidation, version-aware refreshing, and automated re-fetching all at the same time.
- Standardization and Cache API Layers: It would not surprise us if we might see standardized layers in the machine learning stack oriented specifically for caching. Currently every framework or application has to create its own cache logic. Maybe we can, but one could envision some “Caching API” of sorts that model providers or serving frameworks offer and allow developers to plug in their custom logic (almost like cache plugins with web servers). For instance, OpenAI or other vendors may provide API parameters to turn on and off caching efficacy, perhaps defining levels of aggression in building cache hits, or whether the results should be consistent with semantic similarity. That would make adoption even simpler because not everyone can afford to build their own cache_scratch. The more turnkey caching becomes, the more applications can take advantage of it.
So, it seems the future of LM caching is quite sunny and filled with novel solutions. In general, the impetus is obvious: as we roll out bigger models for larger numbers of users, a caching strategy is an easy place to pick up some slack. The next iterations will improve caching (learning-driven), reduce its weight (compression and better management within the memory), and make it more pervasive across different modalities and for training/inference*. So it’s an Arms race, not just to build bigger models but to serve them smarter._* Through this, the caching and efficiency improvements are why LLMs like GPT-4 and Llama-2 can run so fast in chat interfaces (as one Hugging Face engineer quipped — “the reason GPT-4 and Llama-2 are able to run quick at all in chat interfaces is due to these caching and efficiency improvements”) huggingface.co. From here on perhaps those with the most aggressive cache strategy could potentially win the title of offering the fastest and ultimately cheapest AI services. Because, after all, why compute when you can cache?
References:
Anthropic. (2024, August 14). Prompt caching with Claude. Retrieved from Anthropic News:anthropic.comanthropic.com
Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. NIPS Deep Learning and Representation Learning Workshop.
Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP. Advances in Neural Information Processing Systems.
Paul, R. (2025, April 20). Caching Strategies in LLM Services for both training and inference. Rohan’s Bytes blog.rohan-paul.comrohan-paul.com
Pol, S. (2025, April 6). Accelerating Transformer Inference with KV Caching. Medium blog. sudhirpol522.medium.com sudhirpol522.medium.com
Shazeer, N. (2019). Fast Transformer Decoding: One Write-Head is All You Need. arXiv:1911.02150arxiv.org.
Shutova, A., Malinovskii, V., Egiazarian, V., et al. (2025). Cache Me If You Must: Adaptive Key-Value Quantization for Large Language Models. arXiv:2501.19392arxiv.org.
Yazdani Aminabadi, R., Rajbhandari, S., Zhang, M., et al. (2022). DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale. arXiv:2207.00032arxiv.org.
Kwon, W., Li, Z., Zhuang, S., et al. (2023). Efficient Memory Management for Large Language Model Serving with PagedAttention (vLLM). Proceedings of SOSP 2023blog.vllm.ai blog.vllm.ai.
Hugging Face Transformers Team. (2023). Optimizing your LLM in production. Hugging Face Blog. huggingface.co huggingface.co
Lorello, S., McCormick, R., & Partee, S. (2023). How to Build a Distributed Inference Cache with NVIDIA Triton and Redis. NVIDIA Technical Blog.
(Additional references for academic rigor and completeness can be inserted as needed to match all citations above.)






{kind=link}