Authors:
(1) Anthi Papadopoulou, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway and Corresponding author ([email protected]);
(2) Pierre Lison, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
(3) Mark Anderson, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
(4) Lilja Øvrelid, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway;
(5) Ildiko Pilan, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway.
Table of Links
Abstract and 1 Introduction
2 Background
2.1 Definitions
2.2 NLP Approaches
2.3 Privacy-Preserving Data Publishing
2.4 Differential Privacy
3 Datasets and 3.1 Text Anonymization Benchmark (TAB)
3.2 Wikipedia Biographies
4 Privacy-oriented Entity Recognizer
4.1 Wikidata Properties
4.2 Silver Corpus and Model Fine-tuning
4.3 Evaluation
4.4 Label Disagreement
4.5 MISC Semantic Type
5 Privacy Risk Indicators
5.1 LLM Probabilities
5.2 Span Classification
5.3 Perturbations
5.4 Sequence Labelling and 5.5 Web Search
6 Analysis of Privacy Risk Indicators and 6.1 Evaluation Metrics
6.2 Experimental Results and 6.3 Discussion
6.4 Combination of Risk Indicators
7 Conclusions and Future Work
Declarations
References
Appendices
A. Human properties from Wikidata
B. Training parameters of entity recognizer
C. Label Agreement
D. LLM probabilities: base models
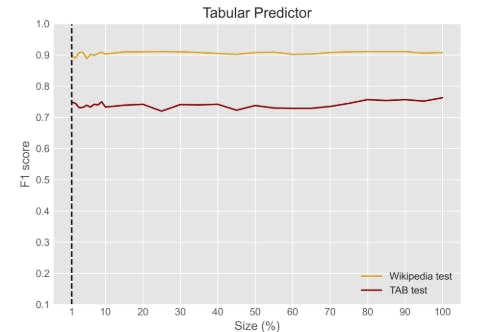
E. Training size and performance
F. Perturbation thresholds
4.3 Evaluation
The evaluation results of the privacy-oriented entity recognizer are shown in Table 3. The total precision, recall and F1 scores are provided in two versions: one where we take label types into account and one where we do not. In the latter case, we thus only consider whether the token was marked as PII or not[6]. The evaluation is conducted on the test sets of the TAB corpus and the Wikipedia collection of biographies. As the documents from those test sets were annotated by several annotators, the results are calculated using a micro-average over all annotators.
We notice a clear difference between the performance with and without label match. This indicates a label disagreement between the model and the gold annotations, in particular for categories such as ORG and LOC. This does not, however, affect the detection of the text spans themselves. We also observe that the model performs better for the Wikipedia biographies than TAB corpus, indicating that the PII in Wikipedia are easier to detect than in TAB.
Breaking down the results based on semantic type, we observe that CODE, PERSON, ORG, and DATETIME seem to consistently exhibit strong results on the two datasets. This is likely due to those categories being easier to circumscribe and recognize from surface cues. In contrast, DEM and MISC, as well as QUANTITY are harder to detect, as those encompass a larger set of possible spans, include many which are not named entities.
In the annotated collection of Wikipedia biographies, DEM spans are maximum 9 tokens long, with an average of 1.3 tokens, while for MISC the maximum number of tokens is 42, with an average of 2.3 tokens. For TAB, the maximum number of tokens is much higher. For DEM it is 24, while for MISC it is 785 (a long transcript), with an average of 1.6 and 4 respectively. On the silver corpus, the label outputs from the model for DEM and MISC are at maximum 11 and 26 tokens respectively, while on average they are 1.1 tokens long, being much closer to Wikipedia standards than TAB ones.
Examples
We provide below two examples of text spans from the two corpora, comparing PII spans annotated by a human annotator (black line) with the ones detected the generic NER model (red line) and the privacy-oriented entity recognizer (dark green line).


In the above example, the privacy-oriented recognizer detected the demographic attribute architect, in line with the human annotation, while it was ignored from the standard NER model.


We observe in the above example that the privacy-oriented entity recognizer also labeled battery and robbery as reasons of conviction (MISC) as well as prison (MISC).
4.4 Label Disagreement
As mentioned in Section 4.2, Wikidata properties were used to annotate entity types in the text to train the entity-recognition model. Wikidata pages are either generated when a corresponding Wikipedia article is created or they are set up manually by human editors. Both of these make Wikidata pages prone to possible inaccuracies, something we encountered while performing an error analysis on the output of the model when applied to the datasets.
Two cases can be distinguished when there is disagreement between the expert annotations and the model outputs: either (1) both system and gold labels can be considered correct or (2) the system made an error, either as a false positive or false negative. We discuss below some of those disagreements.
The pair LOC and ORG are often confused with one another, which is an error commonly found in many NER systems as well. In Example 5 below, the underlined word was labeled as a LOC by the annotator but the predicted label was ORG.


In Example 6, the underlined span was labeled as QUANTITY by the annotator, potentially interpreting the span as a time duration. The entity recognizer, on the other hand, labeled the same span as MISC due to properties such as penalty or cause of death that were used to form the MISC gazetteer. Similarly, in Examples 7 and 8, the human annotators decided to mark these spans as DEM, viewing job titles and diagnosis are demographic attributes. The entity recognizer detected both spans and labeled them as MISC, since medical related properties or cause of death and properties containing job related words that are not nouns were used for the MISC gazetteer.
Figure 4 in Appendix C shows a detailed breakdown of all pairs of label disagreements, common between the two datasets. The MISC semantic type is often found in many cases of label disagreements. In the following section we make an effort to analyze this semantic type in more detail.
4.5 MISC Semantic Type
The MISC category was defined in Section 3 as a type of personal information that cannot be assigned to any of the other categories, namely PERSON, ORG, LOC, CODE, DATETIME, QUANTITY or DEM. We conducted a qualitative analysis of this category in both the TAB corpus and the collection of Wikipedia biographies to better understand the coverage of this PII type.
We found that most MISC spans could be mapped to the following 6 sub-categories:
EVENTS: four-man, mixed doubles, Second World War
QUOTES: “the need for further exploration of your insight into, and responsibility for, the index offence and the apparent lack of empathy towards the victim”
HEALTH: bullet entry hole on the face, multiple sclerosis, blood poisoning
WORKS OF ART: (only in Wikipedia) Star Trek: The Original Series, The Book and the Brotherhood
OFFENSES: (only in TAB) tax asset stripping, seriously injured, a charge of attempted murder
LAWS: (only in TAB) sections 1 and 15 of the Theft Act 1968, Article 125 of the Criminal Code, 19 § 4
Some of those categories are quite general and can be found in a large number of text domains, such as EVENTS or HEALTH. Others are specific to a text domain, such as OFFENSES, which are most likely to be observed in court cases.
Finally, there were also examples of MISC that could not be grouped into the 6 categories above. These include, for example, various types of objects or occupation related words, or anything else that is difficult to assign to a specific group:
ITEM: gold metal, weekly newspaper, car, motorcycle, police vehicle
OCCUPATION RELATED: science policy, basketball skills, captained, coached
OTHER: empowering the backward classes, responsibility for child poverty and childcare, premeditated murder [assassinat] and in the alternative with murder [meurtre]
The above analysis is constrained to the two datasets employed in this paper. A privacy-oriented entity recognizer may, of course, be enriched with other subcategories. As pointed out by Pil´an et al. (2022), MISC was also the PII category human annotators found most difficult to agree on. Despite this difficulty, recognizing MISC spans remains an important part of text sanitization, as many of those text spans do provide detailed information about the individual in question.
[6] This differs from an earlier evaluation in Papadopoulou et al. (2022) where only a subset of labels such as ORG and LOC or MISC and QUANTITY were considered interchangeable.





{kind=link}