
:::info
Authors:
(1) Muhammad Ibraheem Siddiqui, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi ([email protected]);
(2) Muhammad Umer Sheikh, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi;
(3) Hassan Abid, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi;
(4) Muhammad Haris Khan, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi.
:::
Table of Links
Abstract and 1. Introduction
-
Related Work
-
Method
3.1 Class-label Extraction and Exemplar Selection for FSOC
3.2 Instance Detection Module (IDM) and 3.3 Point Prompt Selection Module (PPSM)
3.4 Feedback Mechanism
-
New Dataset (PerSense-D)
-
Experiments
-
Conclusion and References
A. Appendix
Abstract
Leveraging large-scale pre-training, vision foundational models showcase notable performance benefits. While recent years have witnessed significant advancements in segmentation algorithms, existing models still face challenges to automatically segment personalized instances in dense and crowded scenarios. The primary factor behind this limitation stems from bounding box-based detections, which are constrained by occlusions, background clutter, and object orientation, particularly when dealing with dense images. To this end, we propose PerSense, an end-to-end, training-free, and model-agnostic one-shot framework to address the Personalized instance Segmentation in dense images. Towards developing this framework, we make following core contributions. (a) We propose an Instance Detection Module (IDM) and leverage a Vision-Language Model, a grounding object detector, and a few-shot object counter (FSOC) to realize a new baseline. (b) To tackle false positives within candidate point prompts, we design Point Prompt Selection Module (PPSM). Both IDM and PPSM transform density maps from FSOC into personalized instance-level point prompts for segmentation and offer a seamless integration in our model-agnostic framework. (c) We introduce a feedback mechanism which enables PerSense to harness the full potential of FSOC by automating the exemplar selection process. (d) To promote algorithmic advances and effective tools for this relatively underexplored task, we introduce PerSense-D, a dataset exclusive to personalized instance segmentation in dense images. We validate the effectiveness of PerSense on the task of personalized instance segmentation in dense images on PerSense-D and comparison with SOTA. Additionally, our qualitative findings demonstrate the adaptability of our framework to images captured in-the-wild.
1 Introduction
Suppose you work in a food processing sector and you are asked to automate the quality control process for potatoes using vision sensors. Your objective is to automatically segment all instances of potatoes in dense and crowded environments, which are challenged by object scale variations, occlusions, and background clutter. We formally refer to this relatively underexplored task as personalized instance segmentation in dense images (Figure 1). To accomplish this task, your first reflex would be to look for an off-the-shelf SOTA segmentation model. One of the notable contributions in this domain is the Segment Anything Model (SAM) [1] trained on the SA-1B dataset that consists of more than 1B masks from 11M images. SAM introduces an innovative segmentation framework, capable of generating masks for various objects in visual contexts by utilizing custom prompts, thereby enabling the segmentation of diverse elements within images. However, SAM lacks the inherent ability to segment distinct visual concepts as highlighted in [2]. It predominantly provides a mask for individual objects in the image using a point grid, or users can carefully draw a box or point prompt in complex scenarios to segment specific object instances which is a labor-intensive and time-consuming process and hence not scalable.
An alternative method is to utilize the box prompts generated by a pre-trained object detector to isolate the object of interest. A very recent work proposing an automated image segmentation pipeline is Grounded-SAM [3], which is a combination of open-vocabulary object detector GroundingDINO [4] and SAM [1]. When provided with an input image and a textual prompt, it initially utilizes GroundingDINO to produce accurate bounding boxes for objects or regions within the image, using the textual information as a conditioning factor. These annotated bounding boxes then act as the input box prompts for SAM to generate precise mask annotations. However, bounding boxes are limited by box shape, occlusions, and the orientation of objects [5]. In simpler terms, a standard bounding box (non-oriented and non-rotated) for a particular object instance may include portions of other instances. Furthermore, bounding box-based detections, when thresholded with intersection over union (IoU) using non-max suppression (NMS), can encompass multiple instances of the same object [6]. Although techniques like bipartite matching introduced in DETR [7] can address the NMS issue but still bounding box-based detections are challenged due to the variations in object scale, occlusions, and background clutter. These limitations become more pronounced when dealing with dense and crowded images [8]
Considering the SOTA approaches discussed above, there are two options to accomplish the task of personalized instance segmentation in dense images. Firstly, SAM can segment all objects within the image using a grid of points, allowing for precise localization of each object instance. However, despite this precision, it still requires to manually separate the desired class instances. Alternatively, with Grounded-SAM, utilizing “potato” as the text prompt facilitates the segmentation of the desired class. However, due to inherent bounding box limitations (discussed above), proper delineation of class instances may not be achieved (Figure 2). This motivates a segmentation pipeline for dense images that can not only deal with limitations associated with bounding box-based detections but can also provide an automated pipeline capable of achieving instance-level segmentation through the generation of precise point prompts. Such capability will be pivotal for industrial automation which uses vision-based sensors for applications such as object counting, quality control, and cargo monitoring. Beyond industrial automation, it could be transformative in the medical realm, particularly in tasks demanding segmentation at cellular levels. In such scenarios, relying solely on bounding box-based detections could prove limiting towards achieving desired segmentation accuracy.
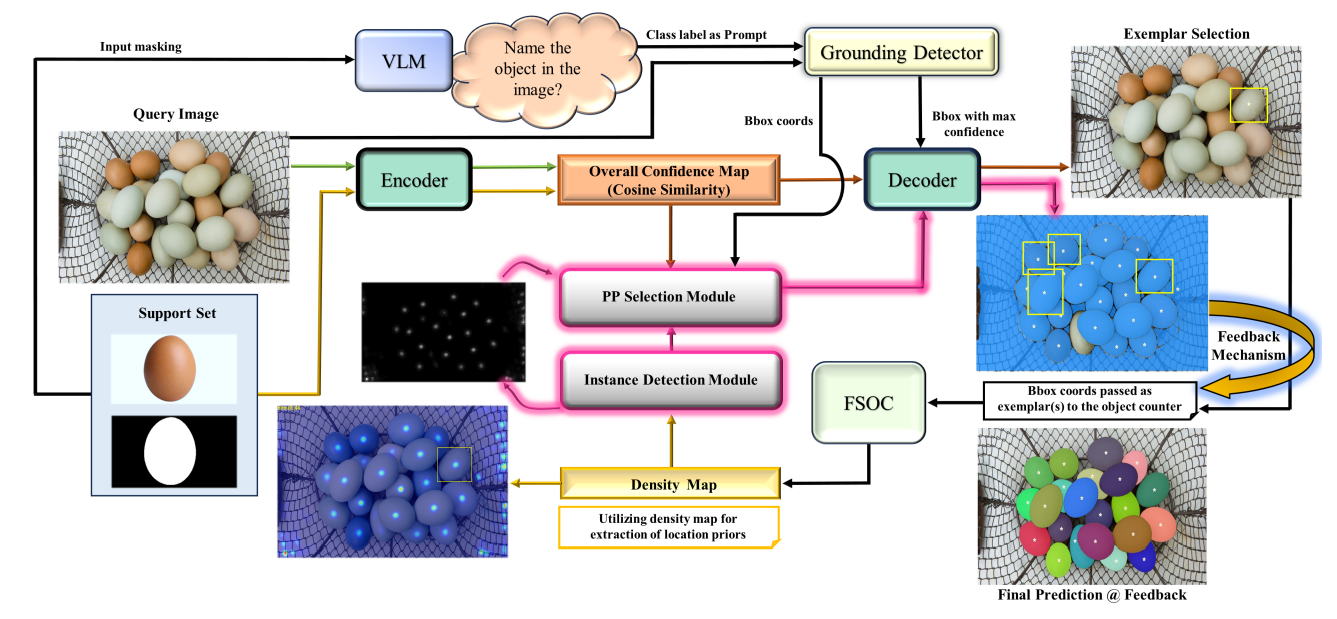
We therefore begin to approach this problem by following the route of density estimation methods, which provide a density map (DM), a (naive) alternative to bounding box-based detections. Although DMs are effective in computing global counts, they often fall short in providing precise localization of individual objects at the instance-level. While some studies have attempted to leverage DMs for instance segmentation in natural scenes [9, 10], there remains a potential gap for a streamlined approach that explicitly and effectively utilizes DMs to achieve automated personalized instance segmentation in dense images. To this end, our work introduces an end-to-end, training-free, and model-agnostic one-shot framework titled PerSense (Figure 1). First, we propose an Instance Detection Module (IDM) to transform DMs into candidate point prompts and then leverage a VLM, a grounding detector, and a few-shot object counter (FSOC) to develop a new baseline for personalized instance segmentation in dense images. Second, we design a Point Prompt Selection Module (PPSM)

to mitigate any false positives within the candidate point prompts in our baseline. The IDM and PPSM are essentially plug-and-play components and seamlessly integrate with our model-agnostic framework. To allow automatic selection of effective exemplars similar to the support set, for obtaining improved DMs from FSOC, we automate the mostly manual process using a VLM and a grounding detector. Third, we introduce a robust feedback mechanism, which automatically identifies multiple rich exemplars for FSOC based on the initial segmentation output of PerSense.
Finally, to our knowledge, there exists no dataset specifically targeting segmentation in dense images. While some images in mainstream segmentation datasets like COCO [11], LVIS [12], and FSS1000 [13], may contain multiple instances of the same object category, the majority do not qualify as dense images due to the limited number of object instances. We introduce PerSense-D, a personalized one-shot segmentation dataset exclusive to dense images. PerSense-D comprises 717 dense images distributed across 28 diverse object categories. These images present significant occlusion and background clutter, making our dataset a unique and challenging benchmark for enabling algorithmic advances and practical tools targeting personalized segmentation in dense images.
2 Related Work
Vision foundation models for segmentation: Unifying vision foundation models is becoming a focal point of research as they exhibit proficiency in addressing multiple vision tasks. Notably, certain approaches [14, 15] advocate for training multiple tasks concurrently using a single model, thus enabling the model to adeptly handle all training tasks without the need for fine-tuning on each specific task. Conversely, alternative strategies [1, 16] have been proposed to train models in a zeroshot manner that allows them to effectively tackle new tasks and adapt to different data distributions without requiring additional training. For instance, SAM [1] is trained on a comprehensive promptable segmentation task which enables it to handle downstream tasks including single point prompt, edge detection, instance segmentation, object proposal generation, and text-to-mask, in a zero-shot manner. Despite exhibiting robust zero-shot performance, SAM segmentations lack semantic meaning, which limits it in segmenting personalized visual concepts. Achieving personalized segmentation with SAM requires the utilization of its manual interactive interface with custom prompts, but this process is very time-consuming and labor-intensive.
One-shot personalized segmentation: To overcome this challenge, PerSAM is introduced in [2], which offers an automated framework for one-shot personalized segmentation using SAM. However, PerSAM is limited to segmenting only a single instance of the personalized class due to its process of localizing a single positive point prompt based on the maximum similarity score. Relying solely on similarity score can result in false positive location priors. See Appendix A.2 for more details. Unlike PerSAM, our PerSense generates precise instance-level personalized point prompts for dense images, utilizing not only the similarity map but also complementary information from the grounding object detector for accurate localization of class instances.
Matcher [17] integrates a versatile feature extraction model with a class-agnostic segmentation model and leverages bidirectional matching to align semantic information across images for tasks like semantic segmentation and dense matching. However, its instance-level matching capability inherited from the image encoder is relatively limited, which hampers its performance for instance segmentation tasks. Matcher employs reverse matching to eliminate outliers and uses K-means clustering on matched points for instance-level sampling. In scenarios involving dense and cluttered images, this sampling strategy can act as a bottleneck, given the challenges posed by object scale and variability during clustering. Additionally, Matcher forwards the bounding box of the matched region as a box prompt to SAM, which can potentially be affected by discussed limitations associated with
bounding box-based detections, especially in crowded environments. To address these challenges, PerSense leverages an FSOC to obtain a personalized density map which obviates the need for clustering and sampling. With IDM and PPSM, PerSense accurately generates at least a single-point prompt for each detected instance. Another recent one-shot segmentation method, SLiMe [18], allows personalized segmentation of images based on segmentation granularity in the support set, rather than object category. Despite its strong performance, SLiMe tends to produce noisy segmentations for small objects. This is due to the attention maps extracted from Stable Diffusion [19] being smaller than the input image. Since our aim is instance segmentation in dense images with varying object scale, SLiMe may not be the most suitable choice.
Interactive segmentation: Recently, the task of interactive segmentation has received a fine share of attention. Works like InterFormer [20], MIS [21] and SEEM [22] provide a user-friendly interface to segment an image at any desired granularity, however, these models are not scalable as they are driven by manual input from the user. To address this challenge, Grounded-SAM [3] establishes a robust framework for automatically annotating images while addressing various segmentation tasks. Essentially, it integrates GroundingDINO with SAM. Leveraging the capabilities of cuttingedge object detectors and segmentation models, Grounded-SAM provides a comparative basis for evaluating the segmentation performance of our PerSense framework. We conduct this evaluation using the proposed PerSense-D dataset, specifically targeting the task of personalized instance segmentation in dense images.
:::info
This paper is available on arxiv under CC BY-NC-SA 4.0 Deed (Attribution-Noncommercial-Sharelike 4.0 International)D license.
:::







{kind=link}