
We believe the industry’s broad interpretation of Jensen’s Law — “Jensen’s Law accelerates Moore’s Law” — understates a fundamental economic reality of artificial intelligence factories.
Nvidia Corp. Chief Executive Jensen Huang’s own language and Nvidia’s operating model point to a financial law of motion for AI factories: When power is the binding constraint and demand is elastic, performance per watt increases raise monetizable throughput faster than they raise total cost. The result is an extension to existing laws of tech that we’ve come to know.
Specifically, Huang’s invoking of Buy more to make more (that is, revenue up) and buy more to save more (unit cost down) has explicit economic implications that we believe need further examination. In addition, there is a corollary in this new regime in that, under certain conditions, fabric‑driven utilization unlocks are so valuable that high‑speed networking becomes “economically free” (where utilization gains exceed amortized fabric cost).
In this Breaking Analysis, we explain in detail what we’re referring to as a new Jensen’s Law. We’ll explore why this phenomenon is so important, review the math behind it, share some concrete examples of where the law is applicable, when the corollary of “the network is free” holds, implications for investors and operators — and where the law is not applicable.
Note on scope and conditions. Our interpretation of Jensen’s law applies primarily to power-limited AI factories operating at high utilization on communication-heavy training and long-context inference workloads, with elastic demand and operator-retained margins. Outside these conditions (for example, capex-limited or demand-limited sites or batchable inference, or where vendor rents are constrained by poor operating leverage), the relationship weakens or can even invert. In this research note, we refer to our interpretation of Jensen’s Law, Jensen’s law, the new Jensen’s law or true Jensen’s law and use them interchangeably.
Why is the new Jensen’s Law important and why now?
As we move beyond single-shot prompts, reasoning and agentic AI multiplies compute per task (100X-1,000X according to Nvidia and other sources). We hear all the time that data centers are increasingly power‑constrained. Nvidia’s GB300/NVLink 72/Spectrum‑X stack explicitly targets tokens per watt as the metric to optimize along with improving achieved utilization. The assumption is, together, these variables directly allow AI customers to monetize power‑limited factories.
Remember, our interpretation of Jensen’s law assumes a new dollar of spend is worth it only if the lifetime extra revenue from better efficiency and utilization is bigger than the lifetime extra costs, after accounting for risk.
With that as context, let’s look at some of the supporting statements from Nvidia’s Q2 FY2026 call on Aug. 27.
The core of Jensen’s Law is that performance per watt drives revenue. In a power-limited data center, the number of tokens you can produce in a year is directly tied to how efficient you are. Or as Huang (pictured above) put it: “Performance per watt drives directly to revenues… the more you buy, the more you grow.”
On the latest earnings call, Nvidia cited massive efficiency gains — 10 to 50 times more energy efficiency with GB300 versus Hopper, depending on configuration and the use of FP4 precision and NVLink 72. Nvidia gave no indications of workloads, configurations or levels of accuracy, which we’ll continue to research.
Nonetheless, we heard concrete return-on-investment proof points. Nvidia cited an example where $3 million spend on GB200 infrastructure generated $30 million in token revenue. That’s a 10X return, presumably not a model, but actual operating data from the likes of Microsoft Corp. and OpenAI (not cited specifically).
And networking is playing a much bigger role. Nvidia’s stack itself spans all three dimensions: NVLink for scale-up inside the rack, Spectrum-X Ethernet and InfiniBand for scale-out across clusters, and Spectrum-XGS for scale-across multisite AI factories. By lifting network utilization from about 65% toward 85% to 90%, the company argues that “networking is effectively free” because the throughput gain more than covers the fabric cost. Our interpretation here is networking can be economically free in communication-heavy environments where utilization gains are greater than fabric cost.
Put in context with spending, Nvidia claims the “Big 4” hyperscalers (big three of Amazon Web Services, Microsoft Azure and Google Cloud, plus Meta Platforms Inc.) are on pace to spend about $600 billion this year on data centers, a figure we peg lower, at just north of $400 billion – nonetheless, still huge. Perhaps Nvidia is sizing the entire data center buildout spend, which still exceeds our estimates. Nvidia sizes the remaining decade’s AI infrastructure build at $3 trillion to $4 trillion, which also are significantly higher than our market projections — but still huge and this is the capex flywheel Jensen is pointing to.
Perhaps Jensen has better visibility on demand than we do.
Reframing ‘Jensen’s Law’: From faster chips to factory economics
The common usage in the press (for example, IEEE Spectrum, the WSJ, Tom’s Hardware and others) positions “Jensen’s Law” as Nvidia’s acceleration beyond Moore’s Law — shorter cycles and outsized generation‑over‑generation gains. That’s directionally spot on, but we want to put a finer point on the law. In our view, the missing lever is one of economics.
Jensen marketing hype or true economic substance?
Our premise today is there’s a version of Jensen’s Law that is more than just marketing and it relates to the economics of AI Factories. Let’s review the core principle that’s emerging in the economics of AI factories.
In a power-limited environment, every incremental dollar of spend that improves performance per watt and fabric efficiency drives monetizable throughput — tokens per second — faster than it raises total cost.
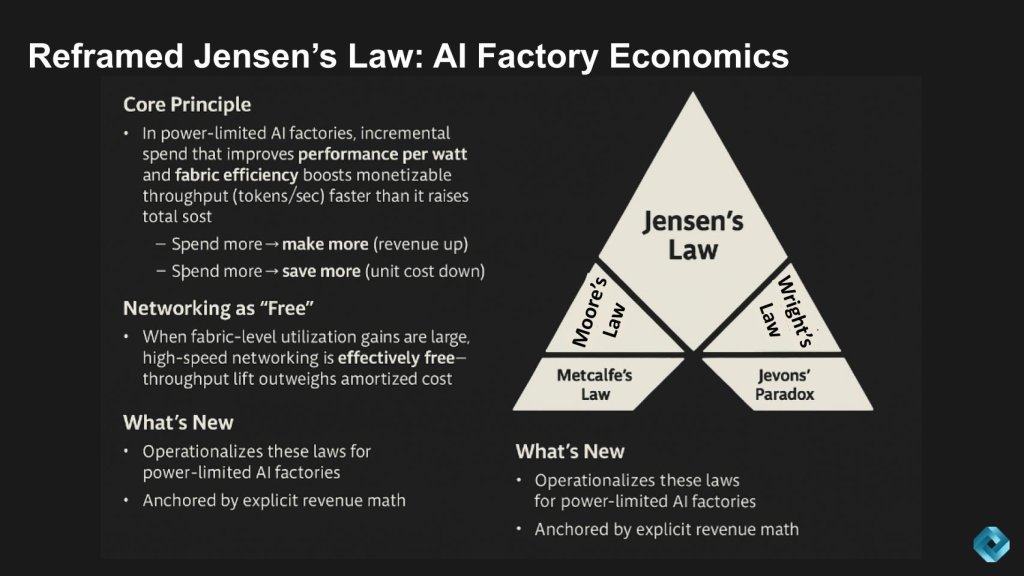
That dynamic leads to two outcomes:
- Buy more, make more — revenue goes up.
- Buy more, save more — unit cost goes down.
Further, when utilization gains at the fabric level are significant, high-speed networking becomes economically free. The throughput lift outweighs the amortized cost of the networking gear. This of course is dependent on the existing utilization assumptions, the workload and the potential gains in utilization.
This framing ties directly back to some of the classic laws of technology economics as shown on the right-hand side of the graphic above. What’s new is that these principles are being operationalized specifically for power-limited AI factories, and we’re anchoring them with explicit revenue math, which we’ll share shortly. That’s the shift — moving from abstract laws of progress to concrete, financial drivers of the AI economy.
The historic laws driving the tech industry
It might be helpful to review these classical laws, and we’ll tie them into our new interpretation of Jensen’s Law.

The following is a brief summary of the laws shown above and the role they play in the new Jensen’s Law as we’ve described:
Moore’s Law: speaks to device scaling and feeds the performance/watt gains – that is, the more tokens you can produce per year at a fixed power envelope the better the economics.
Wright’s Law: cost declines by a constant as cumulative volume doubles – this explains the cost/token falling a deployments scale – core to the “save more” side of the equation.
Metcalfe’s Law: value grows exponentially as a function of connectivity. This speaks to the network utilization – scale up, scale out, scale across, making networking economically “free.”
Jevons’ Paradox: efficiency increases consumption and supports the flywheel effects of Jensen’s Law as we’ve defined it.
The math behind new Jensen’s Law
Let’s break down the math behind our interpretation of this new Jensen’s Law.
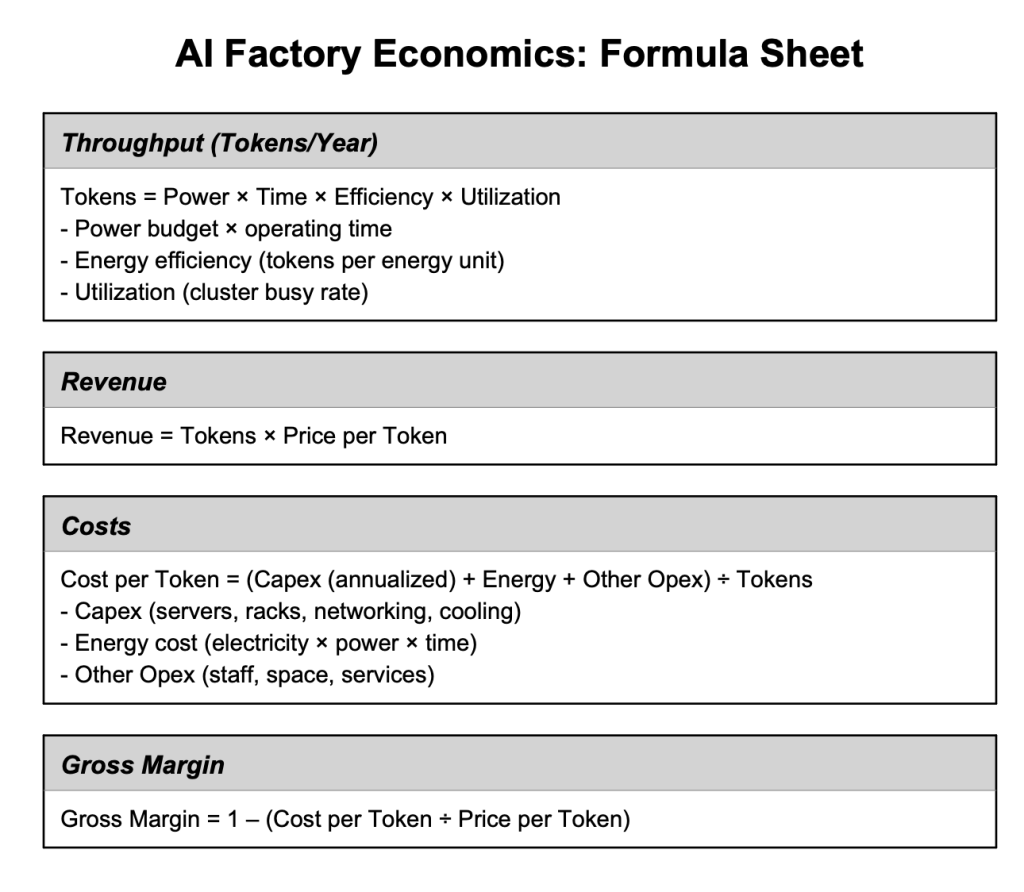
We can boil it down to three things: how many tokens you can generate, how much revenue those tokens produce, and what each token costs to make.

Start with throughput — tokens per year. That’s a function of four variables: the power budget, the amount of operating time in a year, the efficiency of the system — meaning tokens per unit of energy — and how well you can utilize the cluster. Put those together, and the formula is as follows:
[Tokens per year = power X efficiency X utilization.]
Once you know throughput, revenue is just a matter of multiplying tokens by dollars per token. That gives you the top line.
[Revenue = tokens X dollars per token.]
Now let’s look at the cost side of the equation. Cost per token is your total annualized expense — servers, racks, networking, cooling, electricity, staff, real estate — divided by tokens per year. In other words, take capex plus energy plus other operating expenses and spread it across your token output.
[Cost per token = capex (annualized) + energy costs + other opex/annual token output.]
Finally, gross margin. That’s one minus cost per token over price per token. Put simply, the more efficient you are at generating tokens and keeping the system utilized, the more your margin expands.
[1-cost per token/price per token.]
So when we say performance per watt times utilization equals revenue, this is the math. It’s not just a marketing slogan when the conditions are right, rather it’s a financial model for AI factories.
Here’s a simplified graphic that lays this out more clearly:
The accretive-spend rule: The importance of networking
Jensen’s economic argument for networking goes something like this: If you buy more on a faster fabric, better cooling, or smarter software and it improves efficiency or utilization enough, then the extra revenue from more tokens will outweigh the extra cost of that upgrade.
If efficiency and utilization gains are greater than the added costs…buy more, make more applies, because cost per token also falls… leading to buy more, save more.
The Jevons-style booster
When efficiency cuts unit cost, you can charge less per token. If demand is elastic (customers want more when it’s cheaper), revenue grows even faster — reinforcing the Jensen flywheel as we discussed earlier.
Follow the money: The value flow of new Jensen’s Law
Let’s put this in a picture and look at the value flow of Jensen’s Law – “Follow the Money.” To do so,we’ll put our version of Jensen’s Law in plain language.
Think of an AI factory like a cafeteria. The cafeteria has ovens (GPUs), cooks (software) and a delivery system (networking). The point is to serve as many meals (tokens) as possible every day, while keeping costs low and making money.
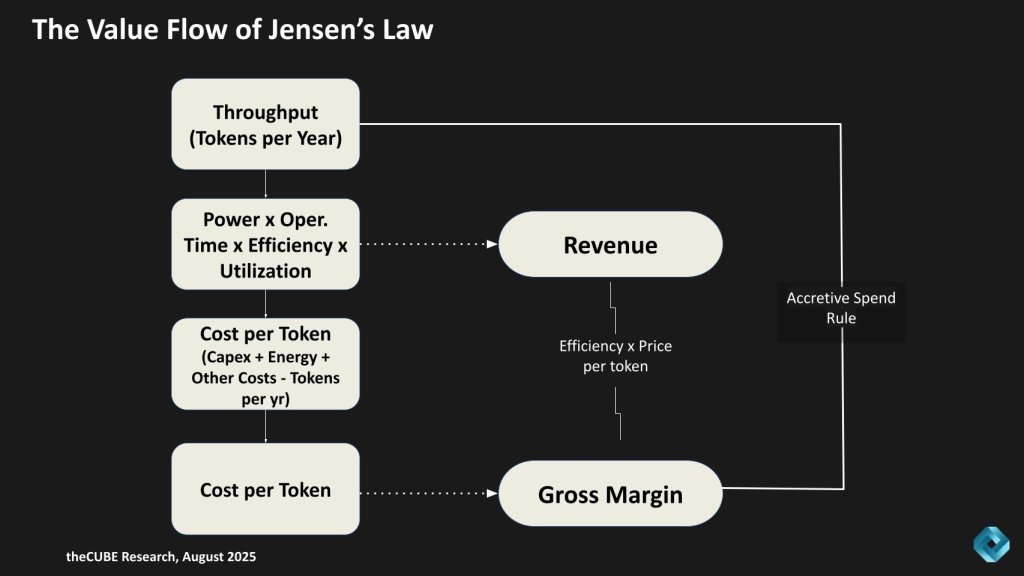
Here’s the flow shown in the chart above:
- Throughput (tokens per year): Think of this as the total number of meals served in a year. More ovens, faster cooking and smoother operations mean more meals.
- Power × time × efficiency × utilization: That’s just a way of saying how much energy you put in, how long you run the cafeteria, how good the ovens are, and how busy you keep them. If ovens sit idle, the factory is underutilized.
- Cost per Token: Every meal has a unit cost — ovens (capex), electricity (energy), and staff/supplies (opex). Divide that by the number of meals served, and you get cost per meal (cost per token).
- Revenue: If you charge money for each meal, revenue is simply how many meals you sell times the price per meal. Same for tokens.
- Gross margin: This is the profit leftover after costs. The lower the cost per token, or the higher the number of tokens sold, the more money you keep.
So the new Jensen’s Law is: Buy more to upgrade the cafeteria, and you’ll either serve more meals (make more) or serve each meal cheaper (save more). If both happen, your profit gets a double whammy.
Networking fits right in. Better networking is like upgrading the cafeteria’s conveyor belts so every oven stays busy. Even if conveyor belts cost extra, they pay for themselves because the cafeteria serves way more meals. That’s why Nvidia says the “network is free.”
The loop on the right is the accretive-spend rule. It means:
- If you buy more (extra capex, better fabric, smarter software) and it increases efficiency or utilization enough…
- Then revenue grows faster than cost.
- The result: higher throughput, more revenue and often lower unit costs.
So the test is:
Does the revenue uplift from higher efficiency/utilization outweigh the added cost of the upgrade?
- If yes… the spend is accretive (profitable).
- If no… you’ve spent money without improving economics.
The key is you have to take a systems view, which is something that Jensen always stresses – “we’re don’t just build chips, we build systems.” This is a key part of Nvidia’s moat, which is underappreciated in our view. If one part of the system is optimized (for example, more ovens create more meals) but the conveyor belt is not fast enough then the system is out of balance and revenue is not maximized.
Digging into Nvidia’s claims
Nvidia’s Q2 results included some proof points for our interpretation of Jensen’s Law. The company gave several examples showing how new architectures and fabrics translate directly into revenue multiples and lower costs per token. Below is our take on some of those.

First, reasoning and agentic AI: Unlike simple chatbots, these agents plan, use tools and iterate. That makes workloads 100 to 1,000 times more compute-intensive, which means efficiency and utilization gains matter a lot more. A key question to ask here is how is Nvidia accounting for utilization? For example, how does the calculation account for multi-tenant overheads, queueing efficiency, I/O fragmentation and restarts?
Second, GB300 with NVLink 72: At rack scale, it delivers about 10X the tokens per watt compared to Hopper. With four-bit floating point math, energy efficiency improves up to 50X per token. CoreWeave Inc. says it’s already seeing 10X better inference on reasoning models in production. We’d be interested in details around what tokenization standards are most productive? What Quality of Service limits (if any) were in place to achieve these 10X to 50X claims?
Third, the fabric story: Networking isn’t a side note, it’s fundamental to the economics. Spectrum-X Ethernet is already running at a $10 billion rate, and NVLink 72 gives you 14X the bandwidth of PCIe Gen5. That’s why Jensen says the network is effectively free — because if utilization gains outweigh the cost – it is economically free. We’d like to understand this further in terms of what reasonable incremental revenue over the fabric costs would constitute “free.” In other words, what kind of save NPV:Fabric TCO ratio should operators assume to achieve that economic freedom? Is it 1X? 2X? 3X – what is a reasonable cushion to guarantee results?
Fourth, the $3 million to $30 million example. Jensen cited a real case where a $3 million spend on infrastructure produced $30 million in token revenue. That’s the “buy more, make more” flywheel in action. Key questions we have include: What was the time window in which this benefit was achieved – i.e. is this a snapshot benefit or one that is sustainable over a period of time? What were the price/token assumptions? What’s a reasonable range of benefit (we assume 10X is a best case scenario for marketing purposes)?
And finally, cadence. Nvidia is shipping new architectures every year — Blackwell to Rubin and beyond. Each one drives higher performance per watt, higher utilization and higher revenue. It’s compounding economics. A key issue we see here is if a new Nvidia generation hits before I realize my payback (for example, I hit delays which is a clear risk) and the value of my infrastructure tanks I’m left with a failed business case and will get fired. We see this as especially pressing as AI moves from hyperscale/cloud to enterprise and edge.
Bottom line: Nvidia isn’t just selling chips; it’s proving the economic engine of our version of Jensen’s Law. Heavier workloads drive the value of efficiency improvements higher, fabrics keep the graphics processing units busy, and each architecture turn compounds the “buy more, make more” cycle. But operators and enterprise customers must cut through the marketing hype, understand their unique environment and how Nvidia’s impressive claims translate into value for them.
Investor considerations: What the new Jensen’s Law changes
We were somewhat surprised by investor reaction to Nvidia’s latest earnings print. Other than a hit to free cash flow margin, we thought the quarter was quite remarkable. And Nvidia addressed the free cash flow in comments about its days sales outstanding, which to us was of no concern.

From an investor perspective, Jensen’s Law changes four things in our view as bulleted above and described in more detail below.
First, the unit of competition is no longer the chip, it’s the AI factory. What matters is system-level performance per watt and utilization, which rewards rack-scale designs, integrated fabrics, software and cadence.
Second, networking isn’t overhead, it can be a profit lever. Utilization gains are so significant that fabric routinely pays for itself — often multiple times over. The caveat is the conditions have to be right. They are today for the large hyperscalers. Will this translate to mainstream enterprises to the same degree?
Third, pricing power is being redefined by elasticity. If elasticity exists, as cost per token collapses, providers can still grow revenue by lowering prices, because demand expands even faster. Note: Operators must take the risk that elasticity is greater than 1 (that is, as price drops customers will buy enough to grow revenue). We’re seeing some positive signs in the scramble for capacity and the shift to reasoning workloads – indicating an insatiable appetite for AI services. The caveat here is price per token is ever-changing and very quickly. Often it’s a race to zero between API pricing, free tiers, price cuts, advertising subsidies and the like. The operator’s margin will be affected by these dynamics, which can alter the outcome.
And fourth, cadence is a cash machine. Nvidia’s product cadence isn’t just about faster chips, it’s about turning capital spending into a recurring monetization flywheel. Each year, new architectures deliver higher efficiency (more tokens per watt) and better utilization (keeping clusters busier). That combination means every dollar of capex spent on GPUs, networking, and racks generates more revenue in the following cycle. But a key consideration for investors is the degree to which customers can move at the speed of Nvidia. Clearly the hyperscalers and Meta, X.ai, the neoclouds and some service providers can keep up. But mainstream enterprises will struggle to maintain pace. If and when the capex gusher dries up, enterprises and new uses cases like robotics will be the growth engine. The dynamics in these markets will be different.
Nonetheless, in today’s hyperscale-led market this is what Jensen means when he says: “the more you buy, the more you grow.” Customers that continually reinvest ride the curve of annual improvements, effectively compounding returns with each generation.
We believe this flywheel is in place until the end of this decade at least.
Operator view: How to measure new Jensen’s Law in the field
Here’s how we think operators should measure Jensen’s Law in the field.
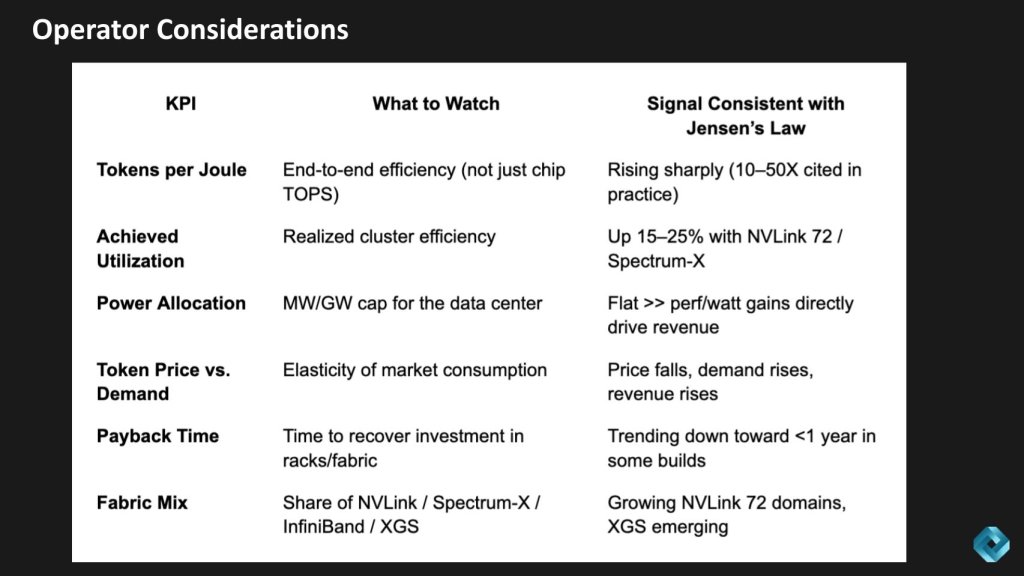
First, tokens per joule — true efficiency is rising fast, 10 to 50 times in some cases.
Second, utilization — some operators claim clusters run 15% to 25% more efficiently with NVLink 72 and Spectrum-X.
Third, power allocation — when the megawatt cap can be flat, every gain in performance per watt drops straight to revenue.
Fourth, token price and demand — as price falls, demand rises, and so does revenue (Jevons’ Paradox)
Fifth, payback time — some builds now recover in under a year.
And finally, fabric mix — NVLink 72 domains are scaling, and XGS (data center to data center) is just starting to emerge.
When the new Jensen’s Law doesn’t hold
We believe the AI factory math is compelling, but only under strict operating conditions. Jensen’s new Law isn’t guaranteed. There are risks and conditions where it may not hold.

First, if a data center isn’t power-limited, then performance per watt isn’t as tightly tied to revenue.
Second, if token prices fall faster than efficiency and utilization rise, growth stalls — especially if demand isn’t elastic.
Third, workloads matter. If the model isn’t sensitive to fabric speed or collective operations, the return on fabric spend moderates.
Fourth, practical constraints like supply chain delays, power or cooling bottlenecks can push out the payoff.
Fifth, If alternative stacks or application-specific integrated circuits start to match Nvidia’ end-to-end efficiency, then the economics begin to normalize.
The following specific details should be monitored over time in our view:
Efficiency claims of 10X to 50X must be validated end-to-end, taking into consideration tokens per joule at accuracy and latency parity. This should be measured at the system level, not on a single GPU. Further, business cases should assume headroom with returns of 3X to 5X over cost to account for the risks.
Utilization uplift is equally nuanced. Gains of 15 to 25 points from NVLink 72 and Spectrum-X are real for collective-heavy training and long-context inference, but may be negligible on parallel inference. Operators should expect meaningful sustained improvement over many weeks under production load before scaling.
Remember, performance per watt only translates to revenue if power is the binding constraint. If capacity is capped by capex or demand, the linkage weakens. In our opinion, upgrades should proceed only when power will be a constraint for 12 to 24 months. Have high confidence that incremental throughput will be consumed – or ideally is presold.
Elasticity assumptions must be grounded. Revenue uplift from price cuts applies only where elasticity is greater than 1. Otherwise, protect margins with tiered QoS. Similarly, sub-year paybacks depend on high utilization, stable token pricing and on-time installations. Our research indicates many investments face unforeseen delays. Assume higher internal rate of return/hurdle rates and longer payback periods in business cases.
Operators must retain margin uplifts. In our view, upgrades are accretive only when power is constrained, utilization lifts are proven, demand is elastic, and the surplus accrues to the operator —not only to the infrastructure supplier.
Finally, this interpretation of Jensen’s Law works well for hyperscalers and consumer Internet companies. It’s unclear how well it translates to enterprise AI and edge customers. We’ll dig into that as those markets evolve.
These are the stress points we need to watch.
Conclusions
Hopefully our reframe of Jensen’s Law is clear. The shorthand of “Moore’s Law on steroids” is catchy but incomplete. The economics show that in power-limited AI factories, efficiency (tokens per joule) and utilization (keeping clusters busy) are the true revenue levers. When those improve faster than costs rise, two dynamics follow: Buy more to make more, and buy more to save more.
Earnings calls continue to supply supporting evidence: Nvidia cites 10X to 50X efficiency gains, examples of $3 million in infrastructure yielding $30 million in token revenue, and fabric-driven utilization lifts that can make networking effectively free. But we caution that these outcomes only hold under strict conditions —measured end-to-end at the system level, with sustained utilization improvements, when power is truly the limiting constraint; and where demand elasticity supports revenue growth rather than price erosion.
For investors and operators, the actionable takeaway is to judge vendors by factory economics, not chip specs alone. The durable winners will be those who compound efficiency and utilization year after year, with software and fabrics carrying as much weight as silicon — while ensuring the efficiency margins accrue to the operator, not just the supplier.
Disclaimer: All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by News Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of theCUBE Research. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.
Photo: Nvidia/livestream
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
- 15M+ viewers of theCUBE videos, powering conversations across AI, cloud, cybersecurity and more
- 11.4k+ theCUBE alumni — Connect with more than 11,400 tech and business leaders shaping the future through a unique trusted-based network.
About News Media
Founded by tech visionaries John Furrier and Dave Vellante, News Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.






{kind=link}