
Authors:
(1) Martyna Wiącek, Institute of Computer Science, Polish Academy of Sciences;
(2) Piotr Rybak, Institute of Computer Science, Polish Academy of Sciences;
(3) Łukasz Pszenny, Institute of Computer Science, Polish Academy of Sciences;
(4) Alina Wróblewska, Institute of Computer Science, Polish Academy of Sciences.
Editor’s note: This is Part 8 of 10 of a study on improving the evaluation and comparison of tools used in natural language preprocessing. Read the rest below.
Table of Links
Abstract and 1. Introduction and related works
- NLPre benchmarking
2.1. Research concept
2.2. Online benchmarking system
2.3. Configuration
- NLPre-PL benchmark
3.1. Datasets
3.2. Tasks
- Evaluation
4.1. Evaluation methodology
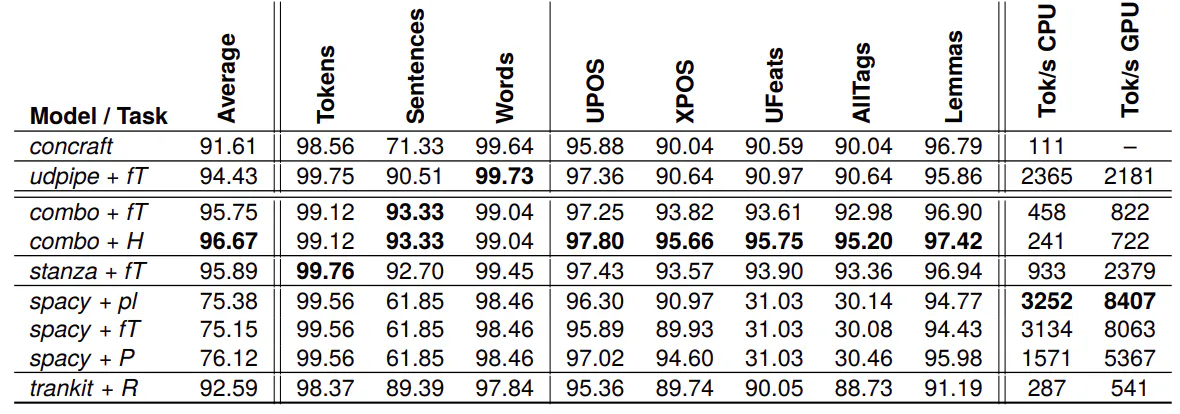
4.2. Evaluated systems
4.3. Results
- Conclusions
- Appendices
- Acknowledgements
- Bibliographical References
- Language Resource References
4.2. Evaluated systems
Based on the NLPre-PL benchmark, we evaluate both well-rooted rule-based disambiguation methods and modern systems based on neural network architectures to enable an informative and thorough comparison of different approaches. We use the most up-to-date versions of available tools at the time of conducting experiments: (1) pipelines of separate tools (Concraft-pl, UDPipe), (2) systems integrating separate models for NLPre tasks (spaCy, Stanza, Trankit), (3) end-to-end systems with a model for all NLPre tasks (COMBO), and large language model GPT-3.5.
Concraft-pl (Waszczuk, 2012; Waszczuk et al., 2018) [12] is a system for joint morphosyntactic disambiguation and segmentation.[13] It uses Morfeusz morphological analyser (Woliński, 2014; Kieraś and Woliński, 2017) to extract morphological and segmentation equivocates and then disambiguates them using the conditional random fields model. We train the Concraft-pl models with default parameters.
UDPipe (Straka and Straková, 2017) is a language-agnostic trainable NLPre pipeline.[14] Depending on the task, it uses recurrent neural networks (Graves and Schmidhuber, 2005) in segmentation and tokenization, the average perceptron in tagging and lemmatization, a rule-based approach in multi-word splitting, and a transition-based neural dependency parser. We train the UDPipe models with the default parameters. The dependency parser is trained with the Polish fastText embeddings (Grave et al., 2018).
SpaCy (Montani and Honnibal, 2022) is an NLP Python library shipped with pretrained pipelines and word vectors for multiple languages.[15] It also supports training the models for tagging and parsing, inter alia. We use spaCy to train pipelines for morphosyntactic analysis with: feed-forward network





based text encoders with static embeddings (fastText and pl-core-news-lg) or transformer-based encoders with the Polbert embeddings (Kłeczek, 2021), taggers (linear layers with softmax activation on top of the encoders), and transition-based parsers.
Stanza (Qi et al., 2020) is a language-agnostic, fully neural toolkit offering a modular pipeline for tokenization, multi-word token expansion, lemmatization, tagging, and dependency parsing.[16] It mainly uses recurrent neural networks (Graves and Schmidhuber, 2005) as a base architecture and external word embeddings (fastText). Each module reuses the basic architecture.
Trankit (Nguyen et al., 2021b) uses a multilingual pre-trained transformer-based language model, XLM-Roberta (Conneau et al., 2019) as the text encoder which is then shared across pipelines for different languages.[17] The resulting model is jointly trained on 90 UD treebanks with a separate adapter (Pfeiffer et al., 2020a,b) for each treebank. Trankit uses a wordpiece-based splitter to exploit contextual information.
COMBO (Rybak and Wróblewska, 2018; Klimaszewski and Wróblewska, 2021) is a fully neural language-independent NLPre system[18] integrated with the LAMBO tokeniser (Przybyła, 2022). It is an end-to-end system with jointly trained modules for tagging, parsing, and lemmatisation. We train the COMBO models with the pre-trained word embeddings – fastText and HerBERT (Mroczkowski et al., 2021).
GPT-3.5 (Brown et al., 2020) is a large language model, notable for its outstanding performance in NLU tasks. It is a fined-tuned version of the GPT-3 model. GPT-3.5’s architecture is based on a transformer neural network with 12 stacks of decoders blocks with multi-head attention blocks.
For segmentation tasks, we train modules integrated with the tested NLPre systems. The only aberration is in spaCy, where poor segmentation results of the dependency module[19] forced us to use an out-of-the-box sentenciser available in spaCy.
For each model, we initialise training with possibly the most prominent and congruent embedding model available. Virtually all models are capable of fully capitalising from that addition, apart from Concraft and UDPipe. The first does not use embeddings at all, and the latter uses them only for dependency parsing training. If embeddings based on BERT architecture are feasible to use, we select their base versions. This ensures fairness of comparison between NLPre systems, as not all of them support BERT-large embeddings.
[12] Polish is a fusional language for which a two-stage tagging procedure is typically applied: first, a rule-based morphological analyser outputs all morphological interpretations of individual tokens, and then a tagging disambiguator selects the most likely one for each token. The tools implemented in accordance with this procedure are still imminent.
[13] https://github.com/kawu/concraft-pl (v2.0)
[14] https://ufal.mff.cuni.cz/udpipe (v1)
[15] https://github.com/explosion/spaCy (v3.4.1)
[16] https://github.com/stanfordnlp/stanza (v1.4.0)
[17] https://github.com/nlp-uoregon/trankit (v1.1.1)
[18] https://gitlab.clarin-pl.eu/syntactic-tools/combo (v1.0.5)
[19] Dependency parsing module is responsible for sentence segmentation in the spaCy implementation.



/cdn.vox-cdn.com/uploads/chorus_asset/file/25813560/monitors.jpg)


{kind=link}