
Table Of Links
ABSTRACT
1 INTRODUCTION
2 DEPENDENTLY-TYPED OBJECT-ORIENTED PROGRAMMING
3 CASE STUDY
4 DESIGN CONSTRAINTS AND SOLUTIONS
5 FORMALIZATION
6 DE/REFUNCTIONALIZATION
7 FUTURE WORK
8 RELATED WORK
9 CONCLUSION AND REFERENCES
DE/REFUNCTIONALIZATION
In our system, de- and refunctionalization can transform any data type into a codata type and vice versa. The key insight behind these transformations is that any data or codata type in the program can be represented in matrix form as shown in Figure 11. A data type is fully determined by specifying an expression for each constructor-definition pair, while a codata type is fully determined by giving an expression for each destructor-codefinition pair. Using these matrix representations, the process of de- and refunctionalization simplifies to matrix transposition. With this intuition in mind, we will now formally define de- and refunctionalization and state our main propositions.
Definition 6.1 (Defunctionalization). We write DT (Θ) to denote the defunctionalization of T in Θ. The precondition for applying DT (Θ) is that codata T Ψ { … } ∈ Θ. Defunctionalization transforms the codata type into a data type. For each destructor d and each codefinition C in Θ: codata T Ψ { (z : T𝜌2). d Ξ2 : 𝑡, … }, codef C Ξ1 : T 𝜌1 { d Ξ2 ↦→ 𝑒, … }
the program DT (Θ) contains a corresponding constructor C and a definition d:
data T Ψ { C Ξ1 : T 𝜌1, … }, def (z : T 𝜌2).d Ξ2 : 𝑡 { C Ξ1 ↦→ 𝑒, … }
Definition 6.2 (Refunctionalization). We write RT (Θ) to denote the refunctionalization of T in Θ. The precondition for applying RT (Θ) is that data T Ψ { … } ∈ Θ. Refunctionalization transforms the data type into a codata type. For each constructor C and each definition d in Θ:
data T Ψ { C Ξ1 : T 𝜌1, … }, def (z : T 𝜌2).d Ξ2 : 𝑡 { C Ξ1 ↦→ 𝑒, … }
the program RT (Θ) contains a corresponding codefinition C and a destructor d:
codata T Ψ { (z : T𝜌2). d Ξ2 : 𝑡, … }, codef C Ξ1 : T 𝜌1 { d Ξ2 ↦→ 𝑒, … }
We write XT (·) for both DT (·) and RT (·), when their difference doesn’t matter. Using these definitions, we can now state our main propositions. Notice that de- and refunctionalization do not affect the program on the expression level. This is because we reuse the syntax for producers for both constructor and codefinition calls and the syntax for consumers for both destructor and definition calls (see Figure 9). Therefore, in the proposition statements below, de-/refunctionalization is only applied to the program Θ.
TheoRem 6.3 (De/Refunctionalization pReseRves typing and judgmental eality). The following implications hold:
• Γ ⊢Θ 𝑒 : 𝑡 =⇒ Γ ⊢XT (Θ) 𝑒 : 𝑡
• Γ ⊢Θ 𝑒1 ≡ 𝑒2 : 𝑡 =⇒ Γ ⊢XT (Θ) 𝑒1 ≡ 𝑒2 : 𝑡
• Γ ⊢Θ 𝜎 : Ξ =⇒ Γ ⊢XT (Θ) 𝜎 : Ξ
• Γ ⊢Θ 𝜎1 ≡ 𝜎2 : Ξ =⇒ Γ ⊢XT (Θ) 𝜎1 ≡ 𝜎2 : Ξ
• ⊢Θ Γ ctx =⇒ ⊢XT (Θ) Γ ctx
• Γ ⊢Θ Ξ tel =⇒ Γ ⊢XT (Θ) Ξ tel
TheoRem 6.4 (De/Refunctionalization pReseRves well-foRmedness of pRogRams). If ⊢Θ Θ OK, then ⊢Θ XT (Θ) OK
FUTURE WORK
In this paper, we described a dependently typed programming language based on data and codata. How to extend this programming language to a proof assistant is one of the problems that we want to address in the future. In the following sections, we describe the problems that have to be solved to make our system consistent, in a way that is compatible with the transformations we described.
7.1 Specifying Termination and Productivity
The system we presented does not have any form of termination or productivity checking. We could, of course, use any of the existing off-the-shelf solutions for checking termination and productivity. The problem with that approach is that, in general, a program that typechecks and is verified to only have terminating recursive definitions and productive corecursive definitions might not be verifiably total after de/-refunctionalization. We illustrate this with the following example:

We could check termination for the program on the left in the usual way. We check the definition of plus first and verify that it is only called on the structurally smaller argument m. We then add plus to the context of functions which are checked to be total. We then check the definition of mul, having the function plus as a total function in the context. We see again that mul is called on the structurally smaller argument m.
Refunctionalizing the program on the left results in the program on the right. In this program, we have to check the productivity of the definitions of Z and S. If we want de/refunctionalization to be a transformation that maps valid programs to valid programs, then the evidence for the productivity of Z and S has to be composed of the evidence for the termination of plus and mul. But it is not at all clear how this can be formally specified at the moment.
7.2 Universe Hierarchy
Another reason why our system is inconsistent is that we use one impredicative universe with the Type-in-Type axiom. This axiom is known to make the theory inconsistent [Hurkens 1995]; on the other hand, it vastly simplifies the presentation and implementation of the theory if we don’t have to care about universe levels. We want to investigate how de- and refunctionalization interact with the assignment of type universes to types. This was also identified as a problem by Huang and Yallop [2023].
7.3 The Variance Problem
Most proof assistants enforce strict positivity in the definition of data types. The strict positivity restriction says that recursive occurrences of the type that is defined are only allowed at strictly positive positions, and is required to avoid Curry’s paradox. The only source of contravariance in most systems is the function type, where arguments are contravariant. In a system with user-defined codata types many different types are the source of contravariance, but this is quite simple to specify. The problem is that many useful types from object-oriented programming require both positive and negative occurrences of the type being defined. For example, consider the following type7 : codata NatSet { member(x: Nat): Bool, union(x: NatSet): NatSet }
In this example, the NatSet type occurs both positively and negatively in the union destructor. But this definition is a sensible one; it is not an obscure definition at all. So if we want to enable the user to work with such definitions we have to replace the strict positivity check by something more refined. One avenue that we want to explore is guarded type theory (e.g. [Clouston et al. 2017]). Guarded logic was introduced by [Nakano 2000] precisely in order to fix problems with binary methods in object-oriented programming, and was later developed by other authors into guarded type theories.
7.4 Strong Behavioural Equality
There is no universally satisfactory definition of equality as the appropriate definition depends on the object being modeled. For many data types, syntactic equality is sensible. For instance, two natural numbers 𝑛0, 𝑛1 : N are considered judgmentally equal if they are built from the same constructors, i.e. Z ≡ Z and 𝑛0 ≡ 𝑛1 =⇒ S(𝑛0) ≡ S(𝑛1). However, the situation is very different as soon as we consider functions 𝑓 , 𝑔 : N → N. Syntactic equality of the function definitions does not seem appropriate, because multiple definitions can define the same function. A more reasonable approach is to regard two functions as equal if they behave identically on all inputs. This principle is known as functional extensionality:
fun_ext : ∀𝑓 𝑔, (∀𝑥, Eq(N → N, 𝑓 𝑥, 𝑔 𝑥)) =⇒ Eq(N → N, 𝑓 , 𝑔)
Functional extensionality is the prototypical example of behavioral equality. It is a special case of bisimilarity: We consider any two objects equal if they behave identically with regard to their observations. For codata types, we often desire behavioral equalities such as bisimilarity.
In most proof assistants, one can pose those propositional behavioral equalities as axioms. But this approach does not work in our system. This is because the functional extensionality axiom is inconsistent for the data representation Fun of functions N → N, which can be seen in the following example:
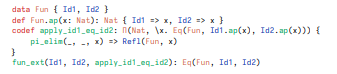
Here we can derive the propositional equality Eq(Fun, Id1, Id2), which is a contradiction to the provable proposition that Id1 is not propositionally equal to Id2. Hence, this counterexample shows that we cannot formulate behavioral equalities as axioms in our system. However, stating behavioral equalities as axioms is often considered unsatisfactory. Axioms break canonicity, i.e., the property that any closed term can be reduced to a canonical value. Further, bisimilarity is always relative to a given set of observations. To see this, consider the functional extensionality axiom from above.
It assumes that the function type has a single elimination form, namely function application. Identifying all types that behave identically on application is, without further conditions, only reasonable if application is the only observation we can make. Hence, we have the principal problem that it is unclear how to specify behavioral equalities given that we are extensible in the observations. Luckily, there are better approaches for working with behavioral equality that are expected to be compatible with our system. For instance, we can resort to the typical Setoid approach of defining a type together with an equality relation:

Unfortunately, the Setoid approach is known for bad usability. To achieve a more ergonomic solution, we need a system that allows us to define a type in conjunction with its equalities. In particular, it must be possible for distinctly named constructors to be equal. Future work in this direction could look into extending de- and refunctionalization to observational type theory [Altenkirch and McBride 2006] or a system with higher inductive types.
:::info
Authors:
- David Binder
- Ingo Skupin
- Tim Süberkrüb
- Klaus Ostermann
:::
:::info
This paper is available on arxiv under CC 4.0 license.
:::







{kind=link}