Modern enterprises often face common DevOps challenges—sprawling toolchains, flaky pipelines, manual bottlenecks, and blind spots—that slow delivery and frustrate engineers. A 2023 survey of 300 IT pros found that rapid tech changes, hidden IT blind spots, and complex systems make observability a major challenge. Without unified visibility, organizations can suffer frequent outages costing ~$13.7M annually. Likewise, when every team adopts its own niche tools, it leads to tool sprawl and fragile integrations.
Common pain points include:
- Tool Sprawl: Dozens of point solutions for SCM, builds, security, etc. each requiring custom glue code leading to integration headaches.
- Pipeline Instability: Long, monolithic CI/CD pipelines tend to break under changing code, causing frequent build/test failures and rework.
- Lack of Observability: Limited monitoring/metrics means slow diagnosis of issues. As one report notes, lack of clear visibility over the entire process leads to finger-pointing and delays.
- Manual Processes: Human approvals and hand-offs are slow and error-prone. Any manual steps lead to extensive labour and risks incorrect updates due to human error.
These challenges translate to slow feature delivery and stress on DevOps teams. To turn chaos into control, enterprises must modernize their pipelines with automation, declarative infrastructure, and observability.
Infrastructure as Code and GitOps
A first step is infrastructure as code (IaC) – managing servers, networks, and services via declarative code. Storing infrastructure configs in Git makes environments repeatable and auditable. In practice, a tool like Terraform can automate cloud provisioning.
For example:
provider "aws" {
region = "us-west-2"
}
resource "aws_instance" "web" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
tags = {
Name = "web-server"
}
}
This Terraform snippet defines a simple EC2 instance. When committed to Git, a CI/CD pipeline can automatically apply it, ensuring consistent environments every time.
Building on IaC, GitOps practices make Git the single source of truth for both code and infrastructure. In a GitOps workflow, any change is made via pull requests and merged into Git; an automated system then deploys or reverts the live state to match the desired state in Git. As GitLab explains, “GitOps uses a Git repository as the single source of truth for infrastructure definitions… and automates infrastructure updates using a Git workflow with CI/CD”. By treating infra configs just like application code, GitOps brings collaboration to ops and eliminates configuration drift.
Automated CI/CD Pipelines
At the heart of modern DevOps are automated CI/CD pipelines that build, test and deploy software on every commit. Instead of days-long releases, automated pipelines run linting, unit tests, integration tests and packaging with every push. For instance, a typical pipeline starts with a code push (or PR) trigger, checks out the code from GitHub/GitLab, then executes build and test steps. After successful tests, the pipeline can automatically deploy the artifact to a VM or container cluster. In short:
-
Trigger & Checkout: Any commit or pull request fires the pipeline. The pipeline “authenticates to an SCM and checks out the code,” including any build scripts.
-
Build & Test: The code is compiled, and unit tests are executed (using tools like Maven, npm, or others). Additional steps run code quality checks (SonarQube, linting) and integration or end-to-end tests. If any test fails, the pipeline halts and notifies developers immediately.
-
Package & Deploy: If all tests pass, the pipeline packages the application and deploys it to the target environment. Advanced workflows may include canary or blue-green deployments and automated rollbacks on failure.
Leading CI/CD tools that support these stages include Jenkins, GitHub Actions, GitLab CI, Azure Pipelines, and newer cloud-native systems like Tekton or Harness. For example, a Jenkinsfile or GitHub Actions YAML can define a multi-stage pipeline with steps for building, testing, and deploying the code.


on: [push]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Run Tests
run: make test
- name: Deploy to Kubernetes
run: kubectl apply -f k8s/deployment.yaml
By automating and separating CI from CD steps, teams avoid ad-hoc scripts and manual handoffs. As one expert notes, mature organizations “deploy to production as often as possible,” leveraging CI to catch errors early and CD to push reliably.
Tooling matters: companies often consolidate around a few key platforms to reduce sprawl. Automated pipelines also enable shift-left practices (like running tests and security scans early) and integrate with container registries, artifact stores and service meshes for a cohesive flow.
Containerization and Orchestration
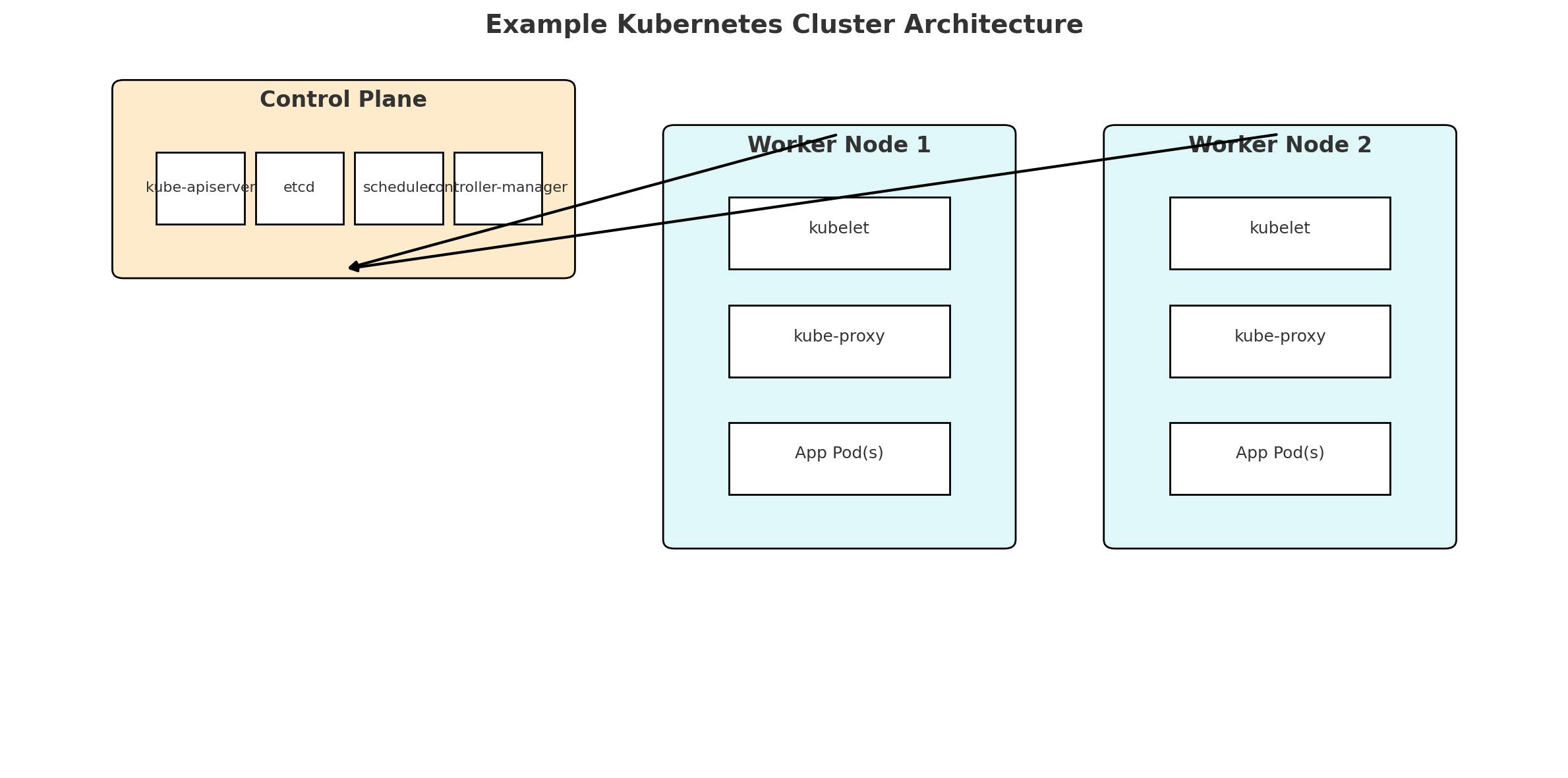
Enterprises benefit greatly by standardizing on containers and orchestration. Packaging applications in Docker containers ensures they run the same in testing, staging, and production. These containers are then managed by orchestrators like Kubernetes. Kubernetes clusters consist of a control plane (API server, etcd, schedulers) and many worker nodes running pods and services.


Figure: Example Kubernetes cluster architecture. The control plane (master) includes components like kube-apiserver and etcd, while worker nodes run kubelets and application pods.
Using Kubernetes, DevOps teams gain self-service environments and rapid scaling. Infrastructure definitions are often stored in Git and deployed via CI/CD. As noted above, GitOps tools like Argo CD continuously compare the “live state against the desired target state”, automatically correcting any drift. For instance, if someone manually changes a deployment, Argo CD will flag it “OutOfSync” and can roll back or update it to match Git, ensuring safety and consistency.
Containers and orchestration also make it easy to incorporate modern deployment strategies. CI/CD pipelines can build a new container image, push it to a registry, and then trigger Kubernetes rolling updates or canary deployments. Service meshes and operators can automate database provisioning, storage, and more. In practice, many enterprises run Kubernetes clusters on public clouds or on-prem, with IaC tools creating the underlying nodes and networking. The result is a repeatable, elastic platform where development teams can reliably deliver services.
Observability and Monitoring
A strong DevOps practice requires not just automation, but insight. Enterprise systems must be continuously monitored. Popular open-source stacks include Prometheus for metrics collection and Grafana for dashboarding. Prometheus scrapes metrics (application, infrastructure, custom), and Grafana lets teams visualize them in real time. Centralized logging (EFK/ELK) and distributed tracing (Jaeger, OpenTelemetry) add further observability.
This matters because without it, teams “cannot define granular metrics” and wastes time chasing unknown failures. High-performing DevOps organizations invest in full-stack observability so problems are detected early. Alerts on key metrics (latency, error rates, pipeline duration) and dashboard summaries help ops teams drill down when things go wrong. In fact, SolarWinds reports that enterprises are now embracing observability platforms to “investigate the root cause of issues that adversely impact businesses”. By instrumenting every layer (from hardware to application code), teams achieve “autonomous operations” potentials with AI-driven insights.
Key tools here include Prometheus/Grafana for metrics, Alertmanager or Grafana Alerts for notifications, and centralized log management tied to dashboards. Many teams also use Tracing for microservices. The result: when pipelines fail or apps crash, rich telemetry avoids guesswork. Observability closes the loop – enabling data-driven feedback to improve CI/CD processes and accelerate mean-time-to-recovery.
Conclusion
Enterprise DevOps need not be a source of frustration. By consolidating tools, codifying infrastructure, and automating pipelines, teams can move from chaos to control. Key practices include adopting GitOps for infrastructure, building robust CI/CD with automated testing, and running workloads in orchestrated containers. Observability and monitoring then provide feedback and guardrails. As a result, organizations can achieve rapid, reliable delivery – for example, Netflix-style multiple daily deployments or BT’s sub-10-minute releases instead of cumbersome, error-prone processes. In short, modern DevOps is about turning complexity into streamlined, repeatable workflows. By learning from industry examples and using the right tools, any enterprise can optimize its software delivery pipeline and reclaim control over its software lifecycle.





{kind=link}