
Authors:
(1) Yanpeng Ye, School of Computer Science and Engineering, University of New South Wales, Kensington, NSW, Australia, GreenDynamics Pty. Ltd, Kensington, NSW, Australia, and these authors contributed equally to this work;
(2) Jie Ren, GreenDynamics Pty. Ltd, Kensington, NSW, Australia, Department of Materials Science and Engineering, City University of Hong Kong, Hong Kong, China, and these authors contributed equally to this work;
(3) Shaozhou Wang, GreenDynamics Pty. Ltd, Kensington, NSW, Australia ([email protected]);
(4) Yuwei Wan, GreenDynamics Pty. Ltd, Kensington, NSW, Australia and Department of Linguistics and Translation, City University of Hong Kong, Hong Kong, China;
(5) Imran Razzak, School of Computer Science and Engineering, University of New South Wales, Kensington, NSW, Australia;
(6) Tong Xie, GreenDynamics Pty. Ltd, Kensington, NSW, Australia and School of Photovoltaic and Renewable Energy Engineering, University of New South Wales, Kensington, NSW, Australia ([email protected]);
(7) Wenjie Zhang, School of Computer Science and Engineering, University of New South Wales, Kensington, NSW, Australia ([email protected]).
Editor’s note: This article is part of a broader study. You’re reading Part 8 of 9. Read the rest below.
Table of Links
Discussion
In this research, we construct a functional material KG by fine-tuned LLMs and ensuring the traceability of all information. During the process, we encountered two main challenges and proposed corresponding solution: 1) Fine tuning LLM reduces the requirement for training set volume, but requires higher quality for each data in training set. when the quality of training dataset is limited, the performance of NER and RE is not good. Recursively generating training set data automatically from inference result is a good solution. High recall and precision data from each inference can be put into the training set after simple manual check. 2) Fine-tuned LLMs perform well on NER and RE task, but for ER task, they can not shows a same. However, the ER is also important in graph construction. To address the issue, we apply several ER methods and technologies including ChemDataExtractor, mat2Vec, Word Embedding Clustering and construct an expert dictionary storing information about energy material. Theses methods and technologies can not only achieve high perfromance ER task, but also remove some erroneous entities and relations.
To better demonstrate the reliability of our method and FMKG, we compare them with existing structural information extraction method and material KG. We employ a similar approach to NERRE task of John Dagdelen et al.[21] to extract structured information from the text. The difference is that we have applied ER method to correct entities and relations, and finish ER tasks before graph construction. We evaluated our pipeline on NERRE’s evaluation dataset. It worth to mention that cross dataset evaluation allow for flexibility of multiple plausible annotations of an entity under different labels (e.g., “cathode”


in NERRE is placed in “Application” label while our expert tend to place it in “Descriptor” since “cathode” and “anode” are component of “battery” which is an application.), and presented the results in a Table 5. From the results, it is evident that our pipeline has slightly lower recall across labels compared to the NERRE task, but our method holds a competitive edge in precision. This is because we believe that the primary goal of KG construction is to ensure the accuracy of the data. Hence, in the process of ER, our strategy tends to sacrifice a portion of recall in exchange for higher precision. However, when considering both recall and precision, our method scores higher in F1 across the “Acronym”, “Application”, “Structure/Phase”, and “Descriptor” labels compared to NERRE, with the improvement in “Acronym” being particularly significant due to its lower precision in NERRE. This underscores the advantage of our ER pipeline and indirectly attests to the credibility of the FMKG.


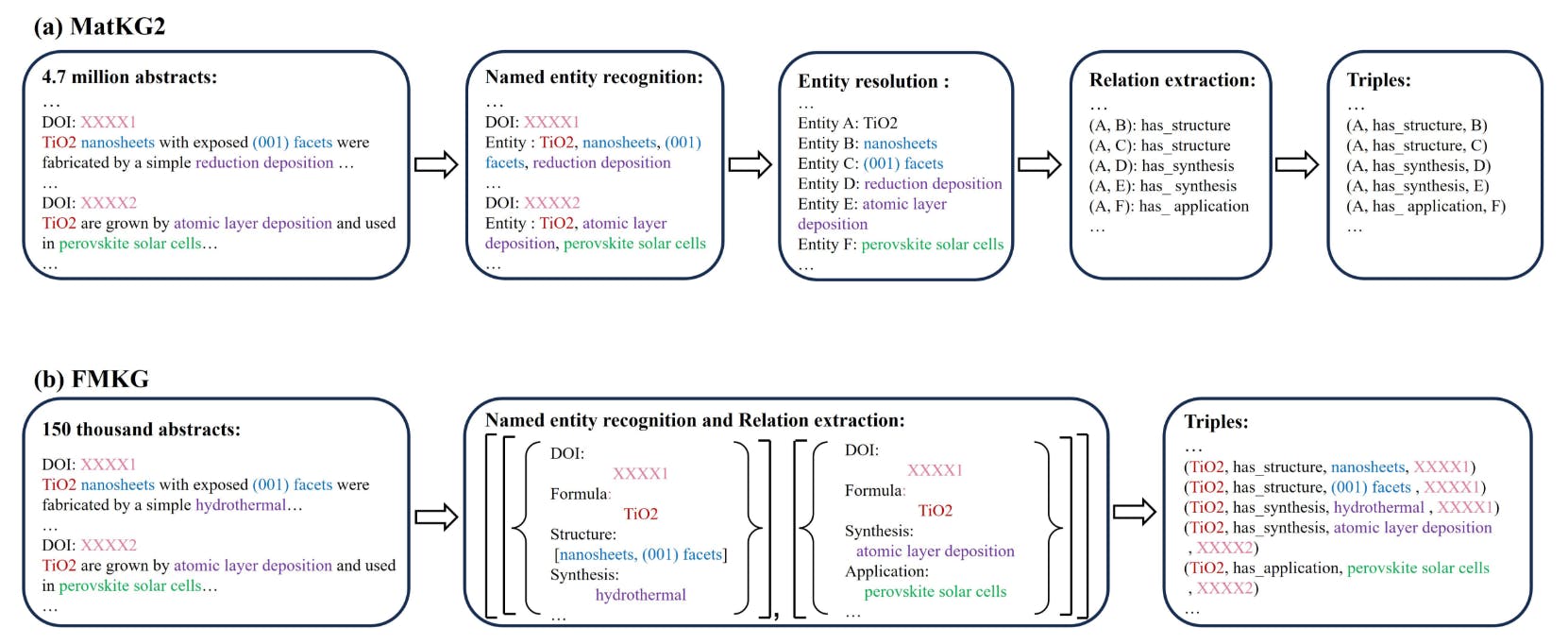
Knowledge graphs specifically dedicated to general materials are rare. In our discussion, we draw a comparison with MatKG2[15], showcasing the differences in construction methodologies between MatKG2 and FMKG, as depicted in the Figure 5. The construction of MatKG2 involves in a multi-step NER and RE pipeline, which can not catch the source of relations. In our method, we use end-to-end method that use a single LLM have been investigated for joint named entity recognition and relation extraction. It can not only catch keep source of each triple in KG so that enhance the factual basis of KG, but also perform better on RE task.
KGs are always dynamic, especially in cutting-edge field such as material science. The LLM internalizes a large amount of knowledge during the training process, it can perform good inference even when new nodes and relationships appear, making KG easy to update. Besides, our work is a starting point where other material researchers can continue build FMKG using our result as training dataset, using our dictionary, ChemDataExtractor and mat2vec to achieve ER task, our method can also be extend to full paper, extract more functional material information to construct a larger and more comprehensive functional material knowledge graph. Besides, our pipeline can also be used in other specialized domains to construct domain-specific KGs.







{kind=link}