
Table of Links
- Abstract and Introduction
- Backgrounds
- Type of remote sensing sensor data
- Benchmark remote sensing datasets for evaluating learning models
- Evaluation metrics for few-shot remote sensing
- Recent few-shot learning techniques in remote sensing
- Few-shot based object detection and segmentation in remote sensing
- Discussions
- Numerical experimentation of few-shot classification on UAV-based dataset
- Explainable AI (XAI) in Remote Sensing
- Conclusions and Future Directions
- Acknowledgements, Declarations, and References
7 Few-shot based object detection and segmentation in remote sensing
In the remote sensing domain, much of the focus has been on image classification tasks like land cover mapping. However, it is also essential to advance higher-level vision tasks like object detection and semantic segmentation, which extract richer information from imagery. For example, object detection can precisely localize and identify vehicles, buildings, and other entities within a scene. Meanwhile, segmentation can delineate land, vegetation, infrastructure, and water boundaries at the pixel level. Significant progress has been made in developing and evaluating object detection and segmentation techniques for remote sensing data. Various benchmarks and competitions have been organized using large-scale satellite and aerial datasets [85, 86]. State-ofthe-art deep learning models like R-CNNs, SSDs, and Mask R-CNNs [17] have shown strong performance. However, many of these rely on extensive annotated training data which can be costly and time-consuming to collect across diverse geographical areas. Therefore, advancing object detection and segmentation in remote sensing using limited supervision remains an open challenge. Few-shot learning offers a promising approach to enable effective generalization from scarce training examples. While some initial work has explored object detection for aerial images [87–91], a comprehensive survey incorporating the latest advancements is still lacking. Furthermore, few-shot semantic segmentation has received relatively little attention for remote sensing thus far.
7.1 Few-shot object detection in remote sensing
The main challenge in few-shot object detection is to design a model that can generalize well from a small number of examples [92–95]. This is typically achieved by leveraging prior knowledge learned from a large number of examples from different classes (known as base classes). The model is then fine-tuned on a few examples from the new classes (known as novel classes) [96].
There are various methods used in few-shot object detection, including metric learning methods, meta-learning methods, and data augmentation methods [97–99]. Metric learning methods aim to learn a distance function that can measure the similarity between objects. Meta-learning methods aim to learn a model that can quickly adapt to new tasks with a few training examples with the help other domain informations [100]. Data augmentation methods aim to generate more training examples by applying transformations to the existing examples [101]. Furthermore, a more comprehensive analysis of aerial image-based FSOD is available in the summarized Table 6.
Explainability in few-shot object detection refers to the ability to understand and interpret the decisions made by the model. This is important for verifying the correctness of the model’s predictions and for gaining insights into the model’s behavior. Explainability can be achieved by visualizing the attention maps of the model, which show which parts of the image the model is focusing on when making a prediction. Other methods include saliency maps [102], which highlight the most important pixels for a prediction, and decision trees, which provide a simple and interpretable representation of the model’s decision process [103]. Therefore, few-shot object detection methods have shown promising results in detecting novel objects in aerial images with limited annotated samples. The feature attention highlight module and the two-phase training scheme contribute to the model’s effectiveness and adaptability in few-shot scenarios. However, there are still challenges to be addressed, such as the performance discrepancy between aerial and natural images, and the confusion between some classes. Future research should focus on developing more versatile few-shot object detection techniques that can handle small, medium, and large objects effectively, and provide more interpretable and explainable results.
7.2 FSOD benchmark datasets for aerial remote sensing images
• NWPU VHR contains 10 categories, with three chosen as novel classes. Researchers commonly use a partition that involves base training on images without novel objects and fine-tuning on a set with k annotated boxes (where k is 1, 2, 3, 5, or 10) for each novel class. The test set has about 300 images, each containing at least one novel object.
• DIOR. dataset features 20 classes and over 23,000 images. Five categories are designated as novel, and various few-shot learning approaches are applied. Fine-tuning is performed with k annotated boxes (where k can be 3, 5, 10, 20, or 30) for each novel class, and performance is evaluated on a comprehensive validation set.

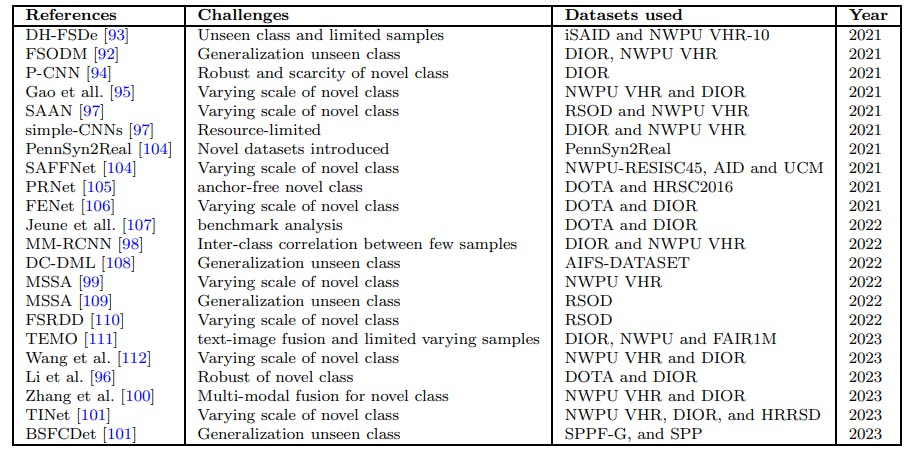
• RSOD. dataset consists of four classes. One class is randomly selected as the novel class, with the remaining three as base classes. During base training, 60% of samples for each base class are used for training, and the rest for testing. Fine-tuning is performed on k annotated boxes in the novel classes, where k can be 1, 2, 3, 5, or 10.
• iSAID dataset features 15 classes and employs three distinct base/novel splits designed according to data characteristics. Each split focuses on a different aspect—such as object size or variance in appearance. The third split specifically selects the six least frequent classes as novel. Base training uses all objects from base classes, and fine-tuning utilizes 10, 50, or 100 annotated boxes per class.
• DOTA dataset features an increase from 15 to 18 categories and nearly tenfold expansion to 1.79 million instances. It has two base/novel class splits, with three classes designated as novel. During episode construction, the number of shots for novel classes varies as 1, 3, 5, and 10.
• DAN dataset is an amalgamation of DOTA and NWPU VHR datasets, comprising 15 categories. It designates three classes as novel, with the remaining as base classes.
7.3 Few-shot image segmentation in remote sensing
Few-shot image segmentation (FSIS) is a challenging task in computer vision, particularly in the context of aerial images. This task aims to segment objects in images with only a few labeled examples, which is especially important due to the high cost of collecting labeled data in the domain of aerial images. Recent advancements in few-shot image segmentation have been driven by deep learning techniques, which have shown promising results in various computer vision tasks. Metric-based meta-learning models, such as Siamese networks and prototype networks, have been widely used in few-shot segmentation [113, 114]. These models learn to compare the similarity between support and query images and use this information to segment novel classes[115].
Another common approach in few-shot image segmentation is to use deep learning networks, specifically convolutional neural networks (CNNs) [116]. These networks have shown great success in image segmentation tasks and have been adapted for few-shot learning scenarios. Researchers have explored different architectures and training strategies to improve the performance of CNNs in few-shot image segmentation[116]. Meta-learning, which involves training a model to learn how to learn, has also been applied to few-shot image segmentation with promising results [116]. Meta-learning algorithms aim to extract meta-knowledge from a set of tasks and use this knowledge to quickly adapt to new tasks with only a few labeled examples. In terms of applications, few-shot image segmentation in aerial images has various potential applications. One application is in urban planning, where few-shot image segmentation can be used to identify and segment different types of buildings, roads, and other urban infrastructure [117–119]. Another application is in land-use and land-cover determination, where few-shot image segmentation can be used to classify different types of land cover, such as forests, agricultural land, and water bodies. Few-shot image segmentation can also be used in environmental monitoring and climate modeling to analyze changes in vegetation cover, water resources, and other environmental factors. In the field of wildfire recognition, detection, and segmentation, deep learning models have shown great potential[120]. These models have been successfully applied to aerial and ground images to accurately classify wildfires, detect their presence, and segment the fire regions. Various deep learning architectures have been explored, including CNNs, one-stage detectors (such as YOLO), twostage detectors (such as Faster R-CNN), and encoder-decoder models (such as U-Net and DeepLab). In the context of UAV images, a framework has been proposed for removing spatiotemporal objects from UAV images before generating the orthomosaic. The framework consists of two main processes: image segmentation and image inpainting. Image segmentation is performed using the Mask R-CNN algorithm, which detects and segments vehicles in the UAV images. The segmented areas are then masked to be removed. Image inpainting is carried out using the large mask inpainting (LaMa) method, a deep learningbased technique that reconstructs damaged or missing parts of an image [121]. Additionally, a more extensive examination of aerial image-based FSIS can be found in the Table 7.
Excitability in few-shot image segmentation, particularly in the context of remote sensing aerial images, have focused on the development of novel models and techniques that enhance the performance of segmentation tasks and provide insights into the decision-making process of the models. One such advancement is the Self-Enhanced Mixed Attention Network (SEMANet) proposed [122]. SEMANet utilizes three-modal (Visible-Depth-Thermal) images for few-shot semantic segmentation tasks. The model consists of a backbone


network, a self-enhanced module (SE), and a mixed attention module (MA). The SE module enhances the features of each modality by amplifying the differences between foreground and background features and strengthening weak connections. The MA module fuses the three-modal features to obtain a better feature representation. Another advancement is the combination of a self-supervised background learner and contrastive representation learning to improve the performance of few-shot segmentation models [115]. The selfsupervised background learner learns latent background features by mining the features of non-target classes in the background. The contrastive representation learning component of the model aims to learn general features between categories by using contrastive learning. This approach has shown potential for enhancing the performance and generalization ability of few-shot segmentation models. Still, there are still some problems to solve in the field, such as how to deal with differences in performance caused by intra-class confusions and how to make models that are simple to understand and can be fairly accurate. Future research should focus on the development of flexible fewshot object segmentation approaches that are capable of effectively handling lightweight models. These models should possess a higher level of interpretability for each of its components and demonstrate the ability to generalize across other domains.
7.3.1 Few-shot image segmentation benchmark datasets for remote sensing aerial images
• iSAID is a large-scale dataset for instance segmentation in aerial images. It contains 2,806 high-resolution images with annotations for 655,451 instances across 15 categories.
• Vaihingen consists of true orthophoto (TOP) images captured over the town of Vaihingen an der Enz, Germany. The images have a spatial resolution of 9 cm, which is quite high compared to many other aerial image datasets. The dataset also includes corresponding ground truth data, which provides pixel-wise annotations for six classes: impervious surfaces (such as roads and buildings), buildings, low vegetation (such as grass), trees, cars, and clutter/background.
• DLRSD contains images where the label data of each image is a segmentation image. This segmentation map is analyzed to extract the multi-label of the image. DLRSD has richer annotation information with 17 categories and corresponding label IDs.
Authors:
(1) Gao Yu Lee, School of Electrical and Electronic Engineering, Nanyang Technological University, 50 Nanyang Ave, 639798, Singapore ([email protected]);
(2) Tanmoy Dam, School of Mechanical and Aerospace Engineering, Nanyang Technological University, 65 Nanyang Drive, 637460, Singapore and Department of Computer Science, The University of New Orleans, New Orleans, 2000 Lakeshore Drive, LA 70148, USA ([email protected]);
(3) Md Meftahul Ferdaus, School of Electrical and Electronic Engineering, Nanyang Technological University, 50 Nanyang Ave, 639798, Singapore ([email protected]);
(4) Daniel Puiu Poenar, School of Electrical and Electronic Engineering, Nanyang Technological University, 50 Nanyang Ave, 639798, Singapore ([email protected]);
(5) Vu N. Duong, School of Mechanical and Aerospace Engineering, Nanyang Technological University, 65 Nanyang Drive, 637460, Singapore ([email protected]).







{kind=link}