Authors:
(1) Clemencia Siro, University of Amsterdam, Amsterdam, The Netherlands;
(2) Mohammad Aliannejadi, University of Amsterdam, Amsterdam, The Netherlands;
(3) Maarten de Rijke, University of Amsterdam, Amsterdam, The Netherlands.
Table of Links
Abstract and 1 Introduction
2 Methodology and 2.1 Experimental data and tasks
2.2 Automatic generation of diverse dialogue contexts
2.3 Crowdsource experiments
2.4 Experimental conditions
2.5 Participants
3 Results and Analysis and 3.1 Data statistics
3.2 RQ1: Effect of varying amount of dialogue context
3.3 RQ2: Effect of automatically generated dialogue context
4 Discussion and Implications
5 Related Work
6 Conclusion, Limitations, and Ethical Considerations
7 Acknowledgements and References
A. Appendix
3 Results and Analysis
We address (RQ1) and (RQ2) by providing an overview of the results and in-depth analysis of our crowdsourcing experiments. We first describe the key data statistics.
3.1 Data statistics
Phase 1. Figure 1 presents the distributions of relevance and usefulness ratings across the three variations, C0, C3, and C7. Figure 1a indicates a larger number of dialogues rated as relevant when annotators had no prior context (C0), compared to instances of C3 and C7, where a lower number


of dialogues received such ratings. This suggests that in the absence of prior context, annotators are more inclined to perceive the system’s response as relevant, as they lack evidence to assert otherwise. This trend is particularly prevalent when user utterances lean towards casual conversations, such as inquiring about a previously mentioned movie or requesting a similar recommendation to their initial query, aspects to which the annotators have no access. Consequently, this suggests that annotators rely on assumptions regarding the user’s previous inquiries, leading to higher ratings for system response relevance.
We observe a similar trend for usefulness (Figure 1b), compared to C3 and C7, C0 has more dialogues rated as useful. The introduction of the user’s next utterance introduced some level of ambiguity to annotators. Evident in instances where the user introduced a new item not mentioned in the system’s response and expressed an intention to watch it, the usefulness of the system’s response became uncertain. This ambiguity arises particularly when annotators lack access to prior context, making it challenging to tell if the movie was mentioned before in the preceding context.
These observations highlight the impact of the amount of dialogue context on the annotators’ perceptions of relevance and usefulness in Phase 1. This emphasizes the significance of taking contextual factors into account when evaluating TDSs.
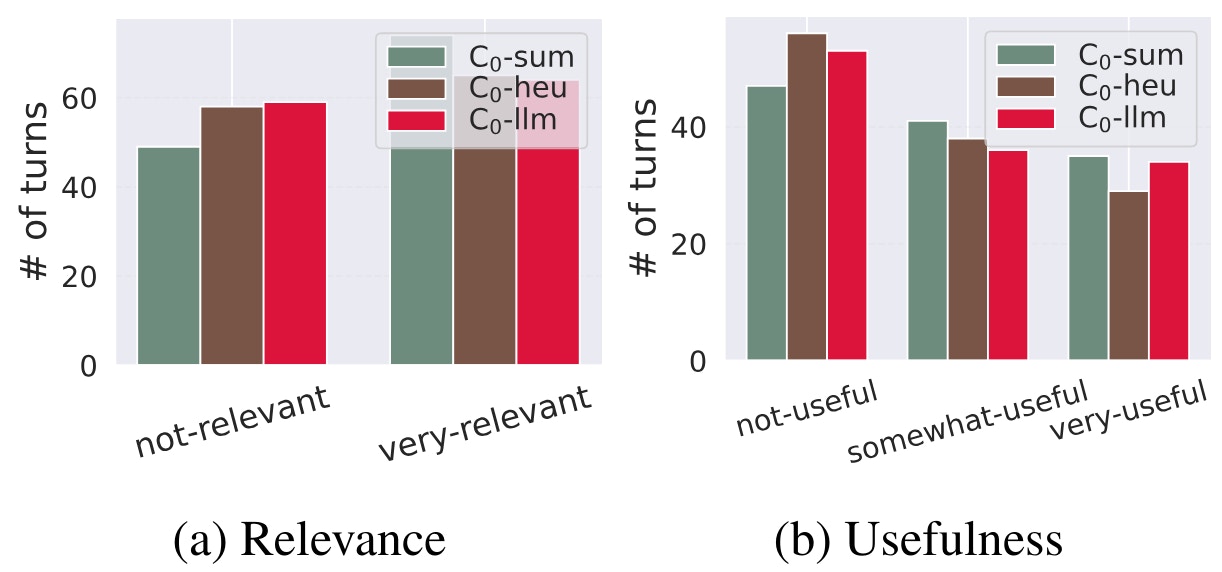
Phase 2. In Phase 2, we present findings on how different types of dialogue contexts influence the annotation of relevance and usefulness labels. When the dialogue summary is included as supplementary information for the turn under evaluation (C0-sum), a higher proportion of dialogues are annotated as relevant compared to C0-llm for relevance (60% vs. 52.5%, respectively); see Figure 2a.
In contrast to the observations made for relevance, we see in Figure 2b that a higher percentage of dialogues are predominantly labeled as not useful when additional information is provided to the annotators. This accounts for 60% in C0-heu, 47.5% in C0-llm, and 45% in C0-sum. This trend is consistent with our observations from Phase 1, highlighting that while system responses may be relevant, they do not always align with the user’s actual information need. We find that C0-sum exhibits the highest number of dialogues rated as useful, indicating its effectiveness in providing pertinent information to aid annotators in making informed judgments regarding usefulness.








{kind=link}